DCN v2
Posted leebxo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DCN v2相关的知识,希望对你有一定的参考价值。
转自:https://blog.csdn.net/u014380165/article/details/88072737
论文:Deformable ConvNets v2: More Deformable, Better Results
论文链接:https://arxiv.org/abs/1811.11168
这篇博客介绍个人非常喜欢的一篇目标检测文章:DCN v2,也就是Deformable ConvNets论文的升级版,效果提升很明显,思想很简洁。主要的改进包括:
1、在特征提取网络的更多层中引入deformable convolution结构,从后面的实验来看,这个操作虽然简单,但是效果提升非常明显,只不过在v1论文中使用PASCAL VOC数据集,所以难以观察到这部分提升。
2、改进deformable结构,我们知道不管是deformable convolution还是deformable RoI pooling,主要通过引入offset,使得特征提取过程能够更加集中于有效信息区域,而这篇论文在v1的基础上引入了modulation,modulation简单而言就是权重,通过分配不同权重给经过offset修正后的区域,实现更加准确的特征提取。
3、第2点的想法很好,但是从作者的实验来看(Table1或Table2的最后2行),仅仅通过第2点带来的提升还是比较有限的,主要原因在于现有的损失函数难以监督模型对无关紧要的区域设置较小的权重,因此在模型训练阶段引入RCNN feature mimicking,这部分受论文Revisiting rcnn: On awakening the classification power of faster rcnn的启发,不过实现方式不一样,这篇文章通过联合训练RCNN网络提供有效的监督信息,发挥modulation的权重作用,使得提取到的特征更加集中于有效区域,因此和第2点是紧密结合的。
首先看看这篇文章用到的3个可视化指标,参看Figure1,Figure1是关于常规卷积、DCNv1和DCNv2的对比图,用来说明Deformable convolution的效果。
1、effective sampling locations, 也就是有效的计算区域,这个在DCNv1论文中看得比较多了,简而言之就是几个卷积层叠加后从输出中的某个点往前推算出参与该点计算的特征点区域,在Figure1中就是往前推算3层得到的图,因此点数最多为9^3=729,常规卷积因为有重叠,所以看到的只有49个(a中第一行),可变卷积因为涉及越界,所以实际点数少于729,一般在200左右(b中第一行)。
2、effective receptive fields,也就是有效感受野,可以通过梯度来计算,不同于理论感受野。
3、error-bounded saliency region,表示当以完整的输入图像进行计算和只以输入图像的部分区域进行计算时,模型得到的输出相同时的最小区域,简而言之,这部分区域(saliency region)是对模型输出影响较大的区域。
从Figure1中可以得到几个结论:
1、基于常规卷积层的深度网络对于形变目标有一定的学习能力,比如(a)中的最后一行,基本上都能覆盖对应的目标区域或者非目标区域,这主要归功于深度网络的拟合能力,这种拟合能力有点强行拟合的意思,所以才有DCN这种设计。
2、DCNv1对于形变目标的学习能力要比常规卷积强,能够获取更多有效的信息。比如(b)中的最后一行,当输出点位置在目标上时(前2张图),影响区域相比常规卷积而言更大。
3、DCNv2对于形变目标的学习能力比DCNv1更强,不仅能获取更多有效的信息,而且获取的信息更加准确,比如?中的最后一行,目标区域更加准确。因此简单来讲,DCNv1在有效信息获取方面的recall要高于常规卷积,而DCNv2不仅有较高的recall,而且有较高的precision,从而实现信息的精确提取。

Figure2是关于常规卷积、DCNv1和DCNv2的对比图,用来说明Deformable RoI pooling的效果。
这里涉及的effective bin location和Figure1中的effective sampling location含义类似,整体上(a)到(c)的实验结果和Figure1中的实验结果一致。(d)和(e)是在模型训练阶段引入的RCNN feature mimicking效果,通过对比(c)和(d)的最后一行图就能明显看出来当RoI在目标上时,(d)中的有效区域更加精确,当RoI不在目标上时,差别不大,这部分后面也有实验证明(Table3)。那么(e)和(d)的对比能说明什么?因为(e)是在常规卷积网络上添加RCNN feature mimicking进行联合训练,但(e)中的有效区域并不准确,原因就在于没有引入modulation和offset,相当于仅有监督信息,但是没有有效的执行点,这也是这篇论文比较有意思的地方。

接下来大概介绍一下modulated deformable convolution,公式如下所示,△mk就是modulation要学习的参数,这个参数的取值范围是[0,1],假如去掉这个参数,那么就是DCNv1中的deformable convolution。
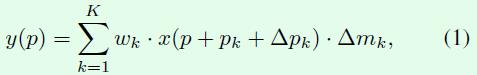
从论文来看,△pk,△mk都是通过一个卷积层进行学习,因此卷积层的通道数是3K,其中2K表示△pk,这和DCNv1的内容是一样的,剩下K个通道的输出通过sigmoid层映射成[0,1]范围的值,就得到△mk。
modulated deformable RoI pooling结构的设计也是同理,公式如下所示,假如去掉△mk参数,那么就是DCNv1中的deformable RoI pooling。
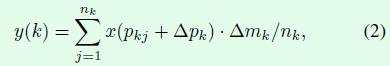
总结一下,DCN v1中引入的offset是要寻找有效信息的区域位置,DCN v2中引入modulation是要给找到的这个位置赋予权重,这两方面保证了有效信息的准确提取。
接下来看看训练阶段增加RCNN feature mimicking是如何实现的,示意图如Figure3所示,姑且称左边的网络为主网络(Faster RCNN),右边的网络为子网络(RCNN)。实现上大致是用主网络训练过程中得到的RoI去裁剪原图,然后将裁剪到的图resize到224×224大小作为子网络的输入,子网络通过RCNN算法提取特征,最终提取到14×14大小的特征图,此时再结合IoU(此时的IoU就是一整个输入图区域,也就是224×224)作为modulated deformable RoI pooling层的输入得到IoU特征,最后通过2个fc层得到1024维特征,这部分特征和主网络输出的1024维特征作为feature mimicking loss的输入,用来约束这2个特征的差异,同时子网络通过一个分类损失进行监督学习,因为并不需要回归坐标,所以没有回归损失。在inference阶段仅有主网络部分,因此这个操作不会在inference阶段增加计算成本。
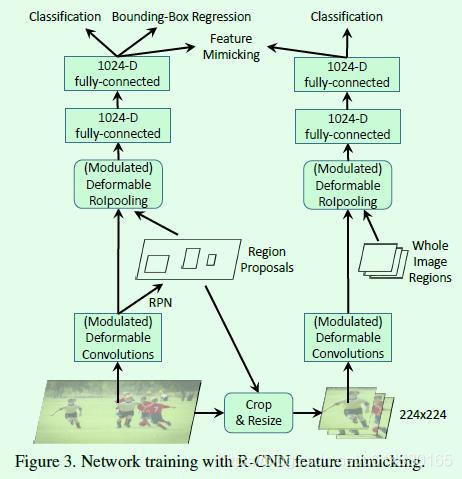
那么为什么RCNN feature mimicking方法有效?因为RCNN这个子网络的输入就是RoI在原输入图像上裁剪出来的图像,因此不存在RoI以外区域信息的干扰,这就使得RCNN这个网络训练得到的分类结果更加可靠,以此通过一个损失函数监督主网络Faster RCNN的分类支路训练就能够迫使网络提取到更多RoI内部特征,而这个迫使的过程主要就是通过添加的modulation机制和原有的offset实现。
feature mimicking loss采用cosine函数度量2个输入之间的差异,这是利用了cosine函数能够度量两个向量之间的角度的特性,其中fRCNN(b)表示子网络输出的1024维特征,fFRCNN(b)表示主网络输出的1024维特征,通过对多个RoI的损失进行求和就得到Lmimic。
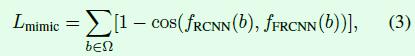
实验结果部分的内容十分丰富,依次来看看:
Table1和Table2都是在COCO 2017 val数据集上的实验结果,差别仅在于输入图像的短边处理不同,Table1是短边缩放到1000的实验结果,Table2是短边缩放到800的实验结果。以Table1为例,从[email protected]和[email protected]这两行的对比可以直接看出即便只是简单将DCNv1中的可变卷积层扩展到c4的网络层,就能有非常明显的效果提升。正如作者所说,当初DCNv1的实验主要是在PASCAL VOC数据集上做的,因此看不到明显提升,切换到COCO数据集就不一样了,因此多关注数据集能够避免一些好的想法夭折。再看看DCNv2的第二个创新点,关于引入modulate,实验对比是[email protected]~c5+dpool和[email protected]+mdpool,提升有,但是不算很明显,这部分可以结合Table3中关于RCNN feature mimicking的实验一起看,在增加这个监督信息进行训练后,效果提升还是比较明显的。
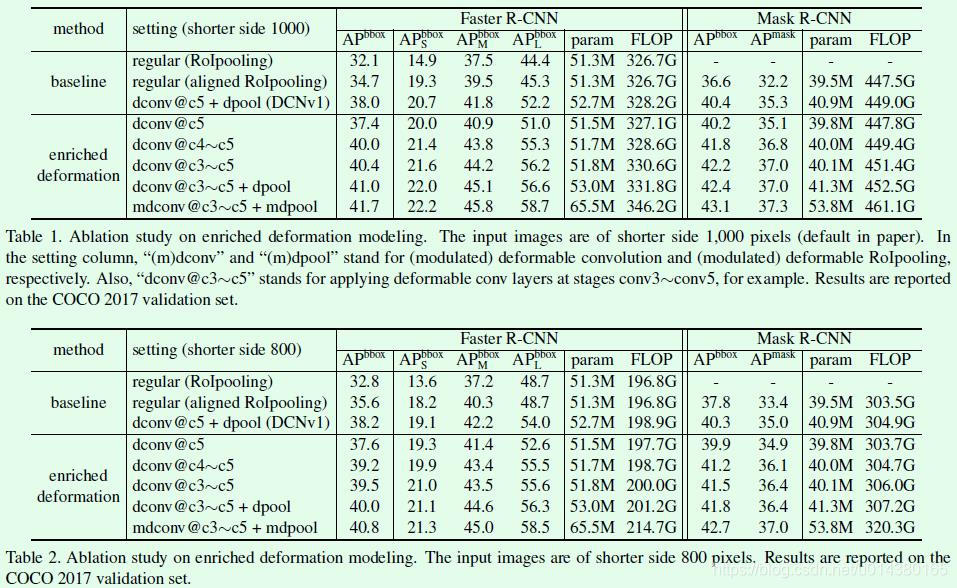
Table3是在COCO 2017 val数据集上关于RCNN feature mimicking是否有效的对比实验,可以看到在DCNv2的基础上增加foreground的IoU进行联合训练提升非常明显,而在常规卷积网络中(regular)的提升非常少,这也说明了仅有监督信息还是不够的,还需要modulation和offset扮演执行者角色进行实际操作。

Table4是在COCO 2017 test-dev数据集上的测试结果,这个实验是为了验证DCNv2的思想在不同特征提取网络中是否有效,这部分关于DCNv2的实验同样引入了RCNN feature mimic损失。可以看出当特征提取网络从ResNet-50升级到ResNet-101和ResNeXt-101时,检测和分割的指标都有所提升,说明了DCNv2的设计确实有效。
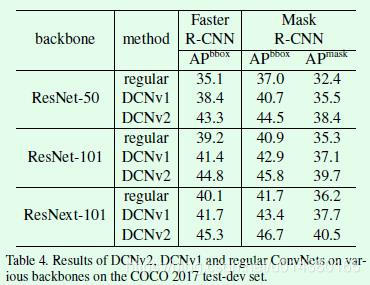
Figure4是关于输入图像短边resize到不同尺寸时常规卷积和DCNv2的效果对比。可以看出常规卷积在输入图像短边尺寸变大时(比如超过1000),效果反而下降了,尤其对于大尺寸目标下降更加明显,而DCNv2没有这样的现象。
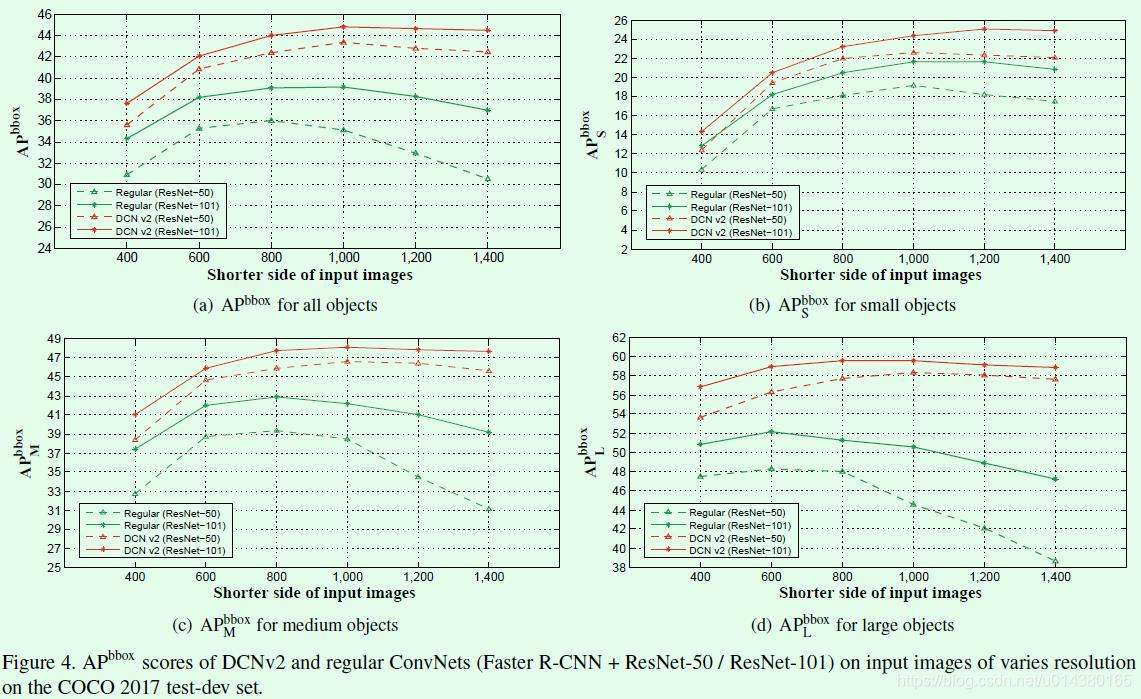
出现这种现象的原因就在于使用常规卷积时,当输入图像分辨率变大,那么对应的目标尺寸也会变大,但是因为常规卷积的感受野不变,所以能够获取到的特征信息就有限,如Figure5(a)第一行的3个图所示,感受野面积依次递减。DCNv2因为感受野受卷积的offset和modulation控制,因此在图像分辨率变大时仍然可以获取目标的足够信息,如Figure5(b)第一行的3个图所示,效果上基本不受影响。

</div>以上是关于DCN v2的主要内容,如果未能解决你的问题,请参考以下文章