sql纵横表的扩展
Posted geliang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql纵横表的扩展相关的知识,希望对你有一定的参考价值。
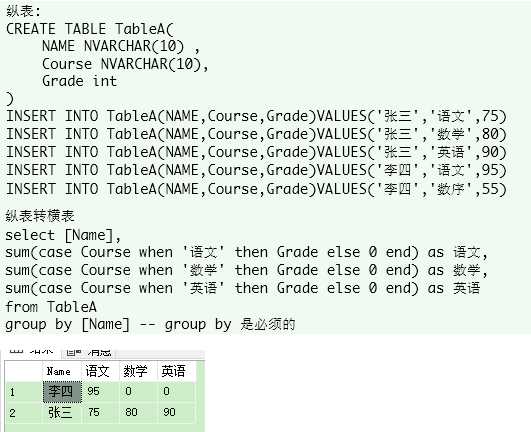
首先,纵横表的实现,百度一下一大堆,这里就不累赘了.我就放一张图片让大家回忆下把
这里有个需求.譬如导出用户地址簿, 在导出的时候需要 用户名, 地址1, 地址2, 地址3
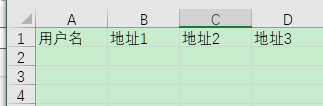
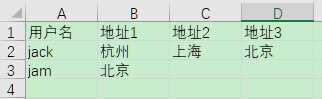
但我们的数据表往往是这样设计的
SELECT u.UserName, u.Address FROM users u

此时,我们的导出结果要是这样的
以往的做法是读取数据库,然后遍历结果集, 代码略
要是sql 能直接查询出我想要的结果集(如下图)

那么我程序就不用遍历了.
回顾下,在最开始的图中, 纵表转横表的核心语句在case语句中,有一列标识了这个成绩是哪个科目的,
既然如此,地址簿是不是也需要标识列呢, 此时动手写sql语句, 给地址簿添加一列,标识这是第几个地址
代码很简单
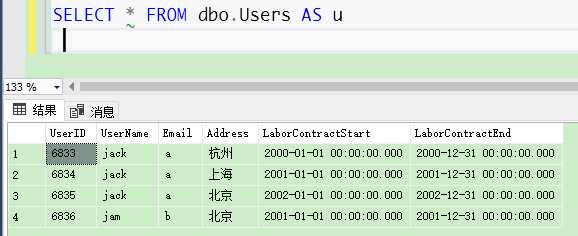
SELECT u.UserName, u.Address, ROW_NUMBER() over(partition by u.UserName order by u.UserName desc) as AddressIndex FROM dbo.Users AS u

这样,我们就出来了一个纵横表转换的基础数据.
为了后续代码看起来简短, 我决定把上面的语句放在CTE语句里
WITH newUsers AS (
SELECT u.UserName, u.Address, ROW_NUMBER() over(partition by u.UserName order by u.UserName desc) as AddressIndex FROM dbo.Users AS u
)
运行测试cte语句
WITH newUsers AS (
SELECT u.UserName, u.Address, ROW_NUMBER() over(partition by u.UserName order by u.UserName desc) as AddressIndex FROM dbo.Users AS u
)
SELECT * FROM newUsers
和没放在cte里的执行结果一致.
这时候再来写表转换
WITH newUsers AS (
SELECT u.UserName, u.Address, ROW_NUMBER() over(partition by u.UserName order by u.UserName desc) as AddressIndex FROM dbo.Users AS u
)
SELECT a.UserName,
(CASE WHEN ( a.AddressIndex =1 ) THEN a.Address ELSE null END) as extAddress1,
(CASE WHEN ( a.AddressIndex =2 ) THEN a.Address ELSE null END) as extAddress2,
(CASE WHEN ( a.AddressIndex =3 ) THEN a.Address ELSE null END) as extAddress3
from newUsers a
GROUP BY a.UserName,a.AddressIndex,a.Address
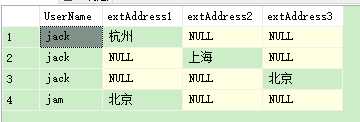
发现大致样子出来了. ,但是1,2,3行应该合并起来
解决方法,给上面结果集嵌套一层,代码如下
WITH newUsers AS (
SELECT u.UserName, u.Address, ROW_NUMBER() over(partition by u.UserName order by u.UserName desc) as AddressIndex FROM dbo.Users AS u
)
SELECT aa.UserName, MAX(aa.extAddress1), MAX(aa.extAddress2), MAX(aa.extAddress3)
FROM (
SELECT a.UserName,
(CASE WHEN ( a.AddressIndex =1 ) THEN a.Address ELSE null END) as extAddress1,
(CASE WHEN ( a.AddressIndex =2 ) THEN a.Address ELSE null END) as extAddress2,
(CASE WHEN ( a.AddressIndex =3 ) THEN a.Address ELSE null END) as extAddress3
from newUsers a
GROUP BY a.UserName,a.AddressIndex,a.Address
) aa GROUP BY aa.UserName
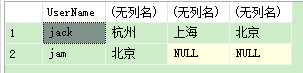
这样就出现了想要的结果集.
或许你会说,当地址簿有4个,5个或更多的地址的时候,sql修改起来麻烦, 但是我想说,代码根据业务逻辑来.这只是一个变化点,我满足当下需求,快速上线项目, 这个代码够用已经可以了.
当然你还可以用变量来解决sql语句的生成, 但是 这样一来代码就多了 ,具体代码实现我想小伙伴们花些时间就解决了.我在这里就不贴出代码, 给个友情提示把. 如果你要修改上面的代码,用变量实现, 此时CTE语句不能用,因为cte语句后面要紧跟select 语句 而不是 exec(sql变量) .
最后一点,关于这个sql的运行效率我没测试, 有心的小伙伴可以帮我留言.
======================扩展下=============
上面的sql修改下,把一行多个维度,给合并起来 譬如导出员工劳动合同,也可以用类似的sql
WITH newUsers AS (
SELECT u.UserName, u.LaborContractStart,U.LaborContractEnd,
ROW_NUMBER() over(partition by u.UserName order by u.UserName desc) as caseIndex
FROM dbo.Users AS u
)
SELECT aa.UserName,
MAX(aa.extLaborContractStart1) AS ‘LaborContractStart1‘,
MAX(aa.extLaborContractEnd1) AS ‘LaborContractEnd1‘,
MAX(aa.extLaborContractStart2) AS ‘LaborContractStart2‘,
MAX(aa.extLaborContractEnd2) AS ‘LaborContractEnd2‘,
MAX(aa.extLaborContractStart3) AS ‘LaborContractStart3‘,
MAX(aa.extLaborContractEnd3) AS ‘LaborContractEnd3‘
FROM (
SELECT a.UserName,
(CASE WHEN ( a.caseIndex =1 ) THEN a.LaborContractStart ELSE null END) as extLaborContractStart1, (CASE WHEN ( a.caseIndex =1 ) THEN a.LaborContractEnd ELSE null END) as extLaborContractEnd1,
(CASE WHEN ( a.caseIndex =2 ) THEN a.LaborContractStart ELSE null END) as extLaborContractStart2, (CASE WHEN ( a.caseIndex =2 ) THEN a.LaborContractEnd ELSE null END) as extLaborContractEnd2,
(CASE WHEN ( a.caseIndex =3 ) THEN a.LaborContractStart ELSE null END) as extLaborContractStart3, (CASE WHEN ( a.caseIndex =3 ) THEN a.LaborContractEnd ELSE null END) as extLaborContractEnd3
from newUsers a
GROUP BY a.UserName,a.caseIndex,a.LaborContractStart,a.LaborContractEnd
) aa
GROUP BY aa.UserName

以上是关于sql纵横表的扩展的主要内容,如果未能解决你的问题,请参考以下文章