Tess4J -4.0.2- Linux 实践 [解决:Tess4J - Native library (linux-x86-64/libtesseract.so) not found in reso
Posted socketqiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tess4J -4.0.2- Linux 实践 [解决:Tess4J - Native library (linux-x86-64/libtesseract.so) not found in reso相关的知识,希望对你有一定的参考价值。
Tess4J是Tesseract的Java JNA wrapper。本文介绍了在CentOS 7 操作系统中使用Tess4J的步骤及注意事项。在正式开始之前,先花一点篇幅,对相关的技术作一简要介绍。
一点点背景
Tesseract
Tesseract 是一个著名的开源OCR引擎,支持100多种语言,可以开箱即用。还可以通过训练方式支持更多语言。Tesseract诞生于1984年,来自HP公司,2005年开源。自2006年起,由谷歌接手开发。截止目前,最新的稳定版本是2017年6月1日发布的3.05.01。还有一只比较活跃的基于LSTM(长短期记忆网络,是一种时间递归神经网络)的4.0版本,还在研发中,最新释放的是2018年6月26日的4.0.0-beta.3。Tesseract由C++开发。
站点:
https://github.com/tesseract-ocr/tesseract
Leptonica
Tesseract作为OCR引擎,避免不了使用图像处理。Tesseract使用的图像处理主要由leptonica提供。Leptonica 包含众多图像处理和图像分析相关的功能。
站点:
http://www.leptonica.com/
Java JNA Wrapper
JNA 是 Java Native Access的缩写,顾名思义,是一个实现Java调用操作系统Native应用的库。提起Java本地调用,大家自然联想的JNI,但JNI使用过程十分复杂,会让人望而生畏。JNA则采取更加自然的方式,为Java应用提供调用本地应用的支持。
站点:
https://github.com/java-native-access/jna
Tess4J
Tess4J通过Java JNA Wrapper,提供了Java的Tesseract API,同时还提供了Windows 32bit和64bit的Tesseract的DLL以及一些样例图像。通过Tess4J,可以在Windows下非常便利的通过Java使用Tesseract。对于Linux、MAC等其他操作系统,则需要自行构建Tesseract才可以使用Tess4J。
也就是说,原生的Tess4J并不是跨平台的,仅仅是对Windows开箱即用的。
这也是本文写作的初衷,记录在Linux环境中,使用Tess4J的步骤及淌过的坑。
本文使用的技术版本
为什么要单独强调版本?长期混迹开源坑的同志们一定了解一个事实:大部分的开源项目其质量(功能可用性,文档正确性、更新及时性)相对一般,在圈子里混,必须具备在众多繁杂的信息中去伪存真的能力,在社区里大声疾呼求关注的技巧,极强的动手能力以及百折不挠的精神。。。
对于某些技术问题,谷歌出来的结果中,很大一部分是无效的,会浪费大量的时间,甚至走入歧途。但同众多作者交流后发现,绝大部分这类情况是有文章介绍方案不完整,或者不够严谨导致的。
因此,我认为,作为分享的每一个实践,需要具备可重复操作的基本要求。所以,我会尽量精确的重复我实践过程使用的软件及环境的版本,希望对大家有所帮助。
Tess4J:4.0.2
Tesseract:4.0.0-beta.1
Leptonica:1.76.0
JDK:1.8 Update 102 64bit
运行环境:CentOS 7 (内核:3.10.0-862.3.3.el7.x86_64)64bit
GCC:4.8.5
Clang:3.4
开发环境:Windows 10 64bit
为何这样选?
这里的坑是,不能根据自己的喜好,使用新版本。我使用过Tesseract 4.0.0-beta.3,但运行JVM会报出Fatal Error最后自行退出,看报出的错误来判断,大概是Tesseract中某些函数签名变化,Tess4J中签名与之不匹配所致。
还记得官方文档(https://github.com/tesseract-ocr/tesseract/wiki)吗?
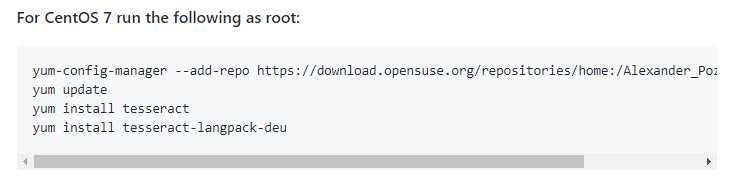
官方Wiki提到,Linux的so库,可以通过安装预先编译的包,如果按照Wiki操作,便会自动安装最新版本。我也曾经尝试通过yum列表旧版本安装,发现即使所谓的旧版本,也会导致Tess4J运行时报错。(通过yum下载并自动安装的rpm包如下所示)
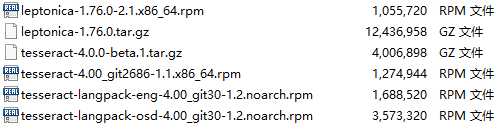
这里必须根据Tess4J适配的版本来选择。
Tess4J的versionchanges.txt中描述了最近几个版本的变化:
Version 4.0.0 (28 April 2018)
- Upgrade to Tesseract 4.0.0-beta.1 (45bb942)
- Update Lept4J to 1.9.3 (Leptonica 1.75.3)
Version 4.0.1 (2 May 2018)
- Fix a path issue when extracting resources from JAR to temp directory on Windows server
Version 4.0.2 (3 May 2018)
- Replace JNA string constant Platform.RESOURCE_PREFIX
- Update jai-imageio url
- Update Lept4J to 1.9.4
可见,最新版的Tess4J,仅对Tesseract 4.0.0-beta.1进行过适配,因此产生了上面描述的版本组合。鉴于无法确定预先构建的包哪个是从Tesseract 4.0.0-beta.1构建而来,因此只能通过源码自行构建。
构建Tesseract
1 修改yum的Repo
可能是我所在的环境网络非常差,yum默认会使用mirror,但绝大部分mirror连接不上,会导致下载过程在大量无效的mirror尝试中进行,非常浪费时间。
因此,我关闭了yum的fast mirror插件(/etc/yum/pluginconf.d),另外修改了CentOS-Base.repo。
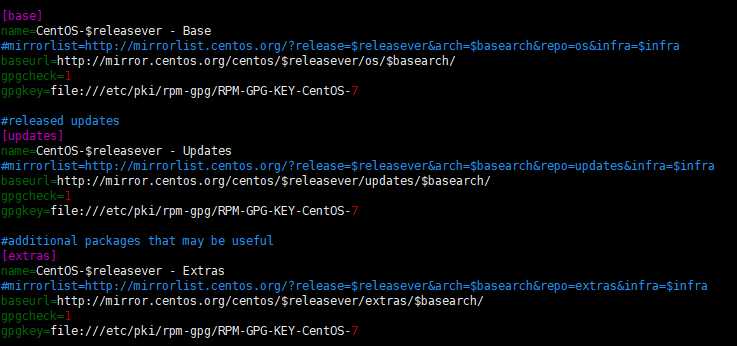
2 安装必备包
|
1
2
3
|
yum -y updateyum -y install libstdc++ autoconf automake libtool autoconf-archive pkg-config gcc gcc-c++ make libjpeg-devel libpng-devel libtiff-devel zlib-develyum group install -y "Development Tools" |
注意:autoconf-archive 是官方说明中都没有提到的必备组件。
3 下载源码
Leptonica
http://www.leptonica.com/source/leptonica-1.76.0.tar.gz
Tesseract
https://codeload.github.com/tesseract-ocr/tesseract/tar.gz/4.0.0-beta.1
下载完毕效果:

4 安装Leptonica
|
1
2
3
4
5
6
|
tar -zxvf leptonica-1.76.0.tar.gzcd leptonica-1.76.0./autobuild./configuremake -jmake install |
5 安装Tesseract
|
1
2
3
4
5
6
7
|
tar -zxvf 4.0.0-beta.1.tar.gzcd tesseract-4.0.0-beta.1/./autogen.shPKG_CONFIG_PATH=/usr/local/lib/pkgconfig LIBLEPT_HEADERSDIR=/usr/local/include ./configure --with-extra-includes=/usr/local/include --with-extra-libraries=/usr/local/libLDFLAGS="-L/usr/local/lib" CFLAGS="-I/usr/local/include" make -jmake installldconfig |
6 确认安装
经过漫长的编译过程,Tesseract已经安装完毕。
执行如下指令:
|
1
|
tesseract -v |
显示内容如下:

即为安装完毕。
获取so库
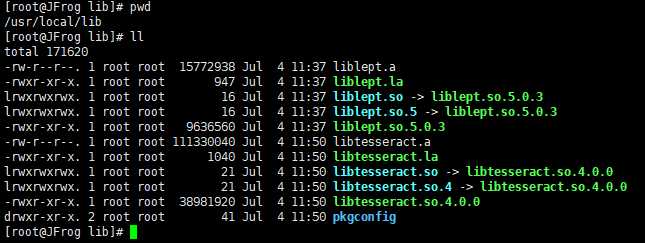
在/usr/local/lib中,可以找到Tess4J需要的依赖库libtesseract.so。可见libtesseract.so实际指向libtesseract.so.4.0.0。liblept.so是leptonica的库,Tesseract也需要调用。
为Tess4J设置库(so)文件位置
Tess4J的JAR包中,包含windows的DLL库,其位置如下:
在Tess4J运行时,会将操作系统依赖的库从JAR包中解压出来使用,对于Linux系统的so文件,也是如此。Tess4J约定的Linux库文件存储路径为classpath根路径下的linux-x86-64。
既然已经拿到了so文件,显而易见的有两种方法:
1 修改tess4j-4.0.2.jar,将so文件按照约定路径存储,这样Tess4J在运行时就会自动解压使用。
但这种方式修改了Tess4J公开发布的JAR包,日后升级会有麻烦,因此,不建议这样操作。
2 将linux-x86-64放到Java工程的classpath根目录。这样在运行时,Tess4J就可以找到库了。我的Java工程采用的Gradle构建,因此将这些文件放到了src/main/resources下。
linux-x86-64目录中包含的文件,是从Linux系统中/usr/local/lib拷贝而来,去掉了一些链接文件,具体如下:
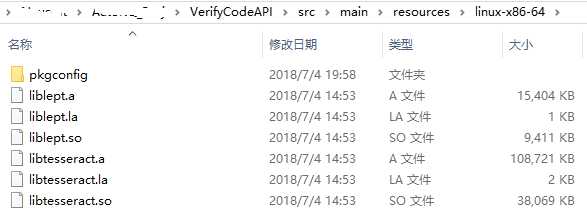
至此,已经完成了Tess4J在库文件方面的准备。
在Tess4J设置Tesseract数据目录tessdata
Tesseract运行时是需要加载语言的训练数据的,按照约定,这些训练数据需要放在tessdata下。但Tess4J 4.0.2对Windows和Linux两类操作系统目录处理方式是不一致的。
初始化Tesseract的代码,setDatapath就是用来设置tessdata目录的。
|
1
2
3
|
ITesseract instance = new Tesseract();//设置tessdata目录instance.setDatapath("/path/to/tessdata"); |
Tesseract的训练数据以“语言名.traineddata”命名。
经过实测,在Windows中,需要直接指定到.traineddata所在目录,在Linux中,则需要指定到一个目录,其中包含一个叫做tessdata的文件夹,tessdata内部是.traineddata文件。
举例说明:
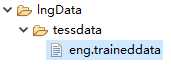
在Windows中,instance.setDatapath("lngData/tessdata");
在Linux中,instance.setDatapath("lngData");
显然这是一个BUG,不过开源项目有BUG已经是家常便饭了。
为此,我在实践时根据操作系统做了一个小小的适配。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
ITesseract instance = new Tesseract();File tessTrainedDataLoc = null;if(SystemDetector.isWindows()) //Windows Data目录直接指定到*.traineddata所在目录 tessTrainedDataLoc = new File(System.getProperty("user.dir"),"lngData\\\\tessdata");else // 在Linux(如CentOS 7)中,Data目录指定到tessdata上一级 tessTrainedDataLoc = new File(System.getProperty("user.dir"),"lngData");instance.setDatapath(tessTrainedDataLoc.getAbsolutePath()); |
以上用到的SystemDetector代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import java.util.Properties;public class SystemDetector private static boolean isWindows = false; private static boolean isLinux = false; static Properties props = System.getProperties(); String systemName = props.getProperty("os.name"); if (systemName.toLowerCase().indexOf("windows") != -1) isWindows = true; if (systemName.toLowerCase().indexOf("linux") != -1) isLinux = true; public static boolean isWindows() return isWindows; public static boolean isLinux() return isLinux; |
至此,全部完成。在Windows上开发的项目使用Tess4J,已经可以在Linux中正常运行。
关于Tesseract的训练数据
Tesseract最大优势就是可以开箱即用,拥有大量语言的训练数据,实际使用时,可以根据需要进行OCR识别的内容类型添加。
但是不要贪多,识别范围越广,速度也就越慢,甚至还会影响精确度。建议在使用时尽量指定要识别内容的语言,类型,以便在准确度及效率之间取一个恰当的平衡。
Tesseract训练数据可以从下面获取:
https://github.com/tesseract-ocr/tessdata
Tesseract 4使用了LSTM,因此还有一个叫做tessdata_best的Repo,其内容是使用LSTM模型训练的各种语言识别率最高的训练数据。(推荐使用)
https://github.com/tesseract-ocr/tessdata_best
如果对Tesseract效果不满意,还可以自行准备数据进行训练。Tesseract所有项目均在Github上,链接地址为:
https://github.com/tesseract-ocr
以上是关于Tess4J -4.0.2- Linux 实践 [解决:Tess4J - Native library (linux-x86-64/libtesseract.so) not found in reso的主要内容,如果未能解决你的问题,请参考以下文章