简要介绍Active Learning(主动学习)思想框架,以及从IF(isolation forest)衍生出来的算法:FBIF(Feedback-Guided Anomaly Discovery)
Posted littlehann
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简要介绍Active Learning(主动学习)思想框架,以及从IF(isolation forest)衍生出来的算法:FBIF(Feedback-Guided Anomaly Discovery)相关的知识,希望对你有一定的参考价值。
1. 引言
本文所讨论的内容为笔者对外文文献的翻译,并加入了笔者自己的理解和总结,文中涉及到的原始外文论文和相关学习链接我会放在reference里,另外,推荐读者朋友购买 Stephen Boyd的《凸优化》Convex Optimization这本书,封面一半橘黄色一半白色的,有国内学者翻译成了中文版,淘宝可以买到。这本书非常美妙,能让你系统地学习机器学习算法背后蕴含的优化理论,体会数学之美。
本文主要围绕下面这篇paper展开内涵和外延的讨论:
[1] Siddiqui M A, Fern A, Dietterich T G, et al. Feedback-guided anomaly discovery via online optimization[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018: 2200-2209.
同时会在文章前半部分介绍这篇paper涉及到的2个主要理论:1)Active Learn;2)(online) Convex Optimization;3)isolation forest的相关内容请参阅另一篇blog。
笔者这里先简单概括一下这篇笔者所理解的这篇paper的主要核心思想:
1. 主动学习思想的融合:
主动学习,也叫查询学习,它要求算法在每轮学习迭代中能够基于某种策略,从当前样本集中选择出“最不确定的一个或一组样本”。从这个角度来思考,无监督异常检测算法普遍都能胜任这个目标,作者在paper中也提到了这个框架的可插拔性,paper中选择了 isolation forest孤立森林算法,每一轮迭代中,通过不断将 isolation tree 当前不确定的数据(无监督模型发现的异常数据),也即最浅路径叶节点输出给外部反馈者并接受feedback label(正例 or 负例),以此获得一批打标样本。
值得注意的是,这种反馈算法框架和具体的abnormal detection algorithm无关,不管是generalized linear anomaly detectors (GLADs)还是tree-based anomaly detectors,都可以应用。相关的讨论可以参阅其他的文章:
Active Anomaly Discovery (AAD) algorithm https://www.onacademic.com/detail/journal_1000039828922010_bc30.html https://www.researchgate.net/publication/318431946_Incorporating_Feedback_into_Tree-based_Anomaly_Detection Loda: Lightweight on-line detector of anomalies https://link.springer.com/article/10.1007%2Fs10994-015-5521-0 SSAD (Semi-Supervised Anomaly Detection) Active learning for network intrusion detection https://www.deepdyve.com/lp/association-for-computing-machinery/active-learning-for-network-intrusion-detection-4Y5zwDUev5 Toward Supervised Anomaly Detection https://jair.org/index.php/jair/article/view/10802
但是仅仅融入和主动学习还不够的, IF算法是无监督的,无法处理这批打标样本,我们还需要引入有监督训练过程,将外部反馈的新信息输入到模型中被存储以及记忆。
2. 凸优化框架的融合:
Isolation tree是一种树状结构,每个样本数据都是树中的一个叶节点。作者创造性在原始 Isolation tree 的基础上,将叶节点所在边赋予了权重w的概念,并将feedback数据(相当于label有监督标签)作为目标label值。这样,每次获得feedback反馈后,就可以基于这批feedback数据(例如100个)进行多元线性回归的参数学习,即回到了有监督学习的范畴内。具体的涉及到Loss Function如何选择,文章接下来会详细讨论。
2. Active Learning(主动学习)
0x1:主动学习基本概念
主动学习(查询学习),是机器学习的一个子领域。主要的思想是:通过一定的算法查询最有用的未标记样本,并交由专家进行标记,然后用查询到的样本训练分类模型来提高模型的精确度。
0x2:什么场景下需要主动学习
1. 项目是冷启动的,在冷启动初期,标签数据是非常稀少的,而且打标成本也相对比较高; 2. 项目虽然不是冷启动,但是很难通过专家构建多元线性分类器,换句话说就是很难通过写出一条条实值规则的逻辑组合。这在实际工作中也是非常常见的,典型地表现会是安全运营人员会发现自己的专家经验“很难准确定义”,往往是通过长时间地不断调整逻辑组合以及判别阈值threshold后,可能依然无法做到0误报0漏报。 显然,人脑不适合高维的、高精确度的复杂线性函数的处理。但是与此同时,人脑又善于根据复杂的高纬度特征,得出一个模糊性的综合判断。例如,当一个安全专家具体拿到某个样本的时候,他通过经验还是能够较快判断出正例/负例,在大多数时候,这个判断又是非常准确的。 笔者认为,我们需要通过机器学习辅助我们进行安全数据分析的一个原因就在于:人脑似乎可以进行非常复杂的逻辑判断,但是却很难数学化地准确表达出自己具体是怎么得到这个结果的。人的经验在很多时候是很准的,但是你要是问他到底是怎么判断的,他往往只能沉思片刻,然后露出一副坚定而微笑的表情,凭经验判断的!而通过机器学习的训练过程,让机器从数据中学习到人的模糊经验,得到一个数值化的、可稳定复现的决策系统。 3. 无监督算法得到的异常未必就对应了业务场景中的一个真实异常事件,即算法层面的outlier和真实业务场景中的abnormal_target往往是存在一个gap的。 我们知道,无监督异常检测算法是根据特征工程后的特征向量进行数值计算后,得到一个异常值排序,这就导致特征工程的结果会极大影响之后的算法运行结果。 针对这一困难,传统方法是需要模型开发者基于对业务的理解去优化特征设计,甚至优化样本集。这一优化通常是纯粹基于经验和尝试的,过程中由于缺少标签指引,其迭代过程甚为繁琐。
0x3:主动学习算法模型框架
主动学习的模型如下:
A = (C,Q,S,L,U)
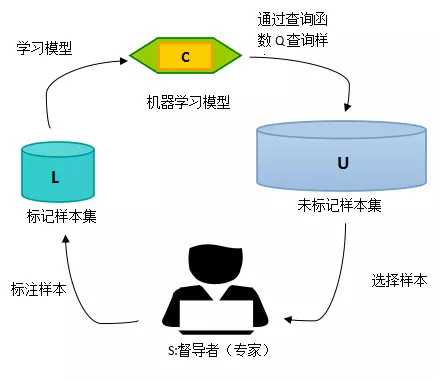
1. 机器学习模型C
只要是有监督学习算法即可。
2. 查询函数Q
查询函数的设计最常用的策略是:不确定性准则(uncertainty)和差异性准则(diversity)。1)不确定性准则对于不确定性,我们可以借助信息熵的概念来进行理解。我们知道信息熵是衡量信息量的概念,也是衡量不确定性的概念。信息熵越大,就代表不确定性越大,包含的信息量也就越丰富。
2)差异性准则(diversity)
0x4:Online Active learning or Batch-size Active learning?
通俗地理解,Online active learning就是模型一次只输出一个预测样本给打标员,打标员通过检视后将反馈结果输入回模型,完成一次迭代。
Batch-size active learning是模型一次输出一整批数据(例如128),打标员统一打标后,统一将结果输入回模型。
理论上说,online learning更利于逼近全局最优,但是在实际工程中,online learning并不容易做到,因为人是不可能持续地一个样本一个样本的打标的,人毕竟不是机器,人会疲劳。因此,笔者在实际项目中,对原始论文中的Online部分修改为了Batch-size,通过一次积累一个batch样本,然后依然流式地逐一输入给原算法。
和online GD和batch-size GD问题一样,batch-size可以理解为对online的一种近似模拟,一般情况下,只要batch不要设置地太大(32-64),对最终结果的影响基本上可以忽略不计。
论文原作者提出的是online active learning,在实际工业场景中,online active learning的部署成本很大,我们一般采用small batch-size active learning代替,总体上效果影响有限。
Relevant Link:
https://blog.csdn.net/Jinpeijie217/article/details/80707978 https://www.jianshu.com/p/e908c3595fc0 https://www.cnblogs.com/hust-yingjie/p/8522165.html
3. (Online) Convex Optimization Framework
0x1:凸优化简介
凸优化在数学规划领域具有非常重要的地位,一旦将一个实际问题表示为一个凸优化问题,大体上意味着对应问题已经得到彻底解决。从理论角度看,用凸优化模型对一般非线性优化模型进行局部逼近,始终是研究非线性规划问题的主要途径。
从理论推演脉络角度来说,凸优化理论是研究优化问题的一个重要分支。实际上,最小二乘以及现行规划问题都属于凸优化问题。
0x2:在线凸优化算法流程
下图展示在线凸优化的伪码流程图:

在一轮的迭代中,都要从凸集中选择一组向量序列w,并选择一个损失函数f()用于计算和目标值之间的差距。
算法的最终目标是:通过选择一组权重w序列![]() ,以及一组损失函数
,以及一组损失函数![]() ,并使总体的离差最小。
,并使总体的离差最小。
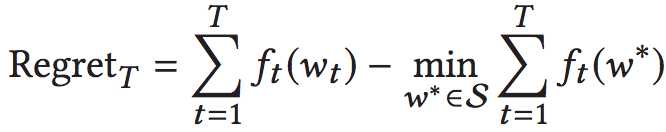
Relevant Link:
https://www.cnblogs.com/wzdLY/p/9569576.html https://www.cnblogs.com/wzdLY/p/9570843.html https://www.jianshu.com/p/e908c3595fc0
4. Feedback-Guided Anomaly Discovery via Online Optimization
0x1:FBIF和传统IF(isolation forest)的区别
我们在文章的开头已经讨论了FBIF的主要思想,下面通过一个图例来说明,FBIF是如何具体解决传统IF的缺陷的。
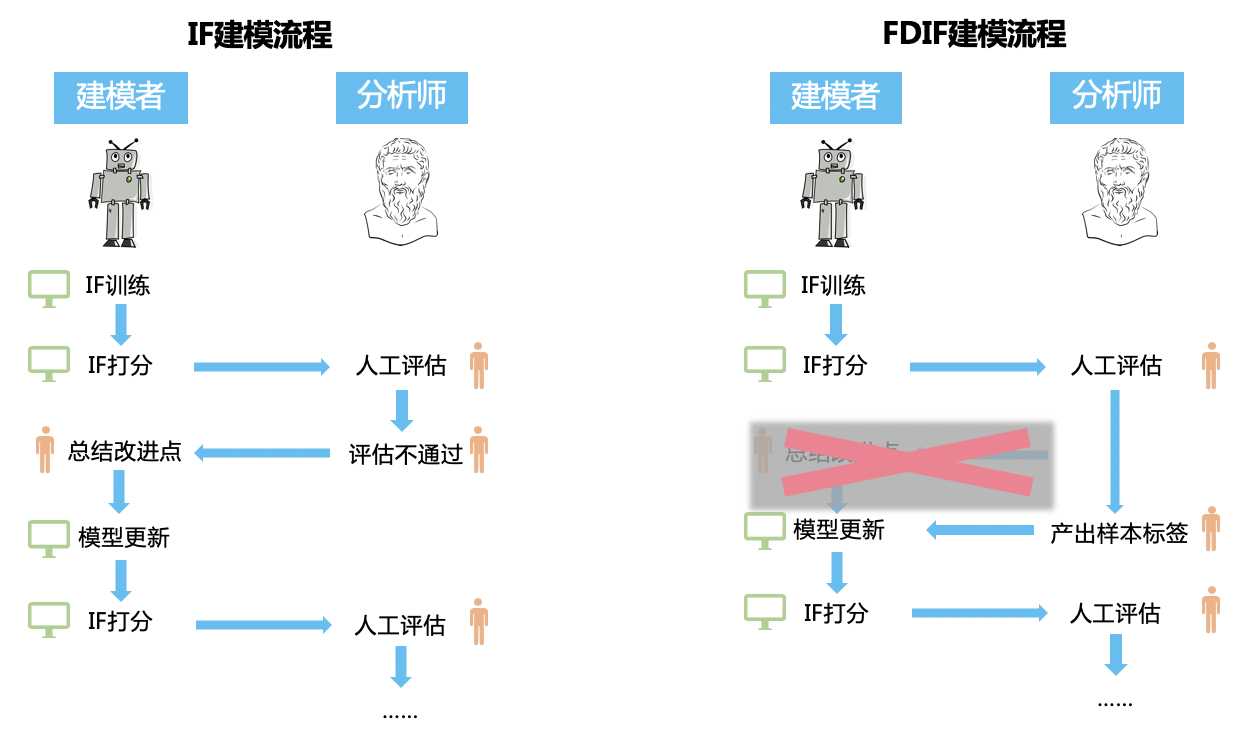
1. 传统IF问题
传统IF检测异常时通常会将头部异常样本集(通常不会太多)输出给分析师,借助他们的专家经验判定是否为所要抓捕的风险,若准确率满足要求则进行生产部署,若不满足要求,则需要建模人员和分析师一起尝试修改特征工程,或者通过白名单排除一些样本集,这是一个将分析师的评估结果人工翻译给IF算法的过程。
这样方法的问题在于,outlier检测算法模式是固定的,具体被检出哪些是outlier,很大程度上依赖于特征工程的设计。所以这个时候为了提高异常发现的recall,算法设计者会尽可能地将“领域经验”融入到特征工程的设计中。但如我们前面所说,算法层面上的异常并不一定就是在业务场景下关注的目标事件,可能某个样本向量从算法层面看,确实非常异常的“离群”,但是从业务角度看却恰恰是一个正常的数据点,而且最麻烦的问题是,当我们不断尝试优化、调整、增加我们的领域经验特征后,这个现象依然大量存在,往往这个时候,模型开发者就只能遗憾地宣布:oh!no!我的这个业务场景不适合无监督异常发现,换别的方案吧。
2. FBIF的解决思路
FBIF作者的解决思路我这里理解是这样的:首先IF是一种生成式模型,IF训练收敛过程没有打标样本的参与,最终生成的概率分布决策函数(decision function)没有有监督样本的参与,经验误差自然会很大。作者将online learning框架思想融入模型中,将监督学习的思想和流程加入到这个无监督过程中,使完全的无监督算法变成半监督的算法。这样得到的综合模型即拥有无监督异常算法的泛化能力,同时也能兼顾有监督学习的强拟合能力的特点。
FBIF省去了传统利用IF做异常检测模型中,反复人工翻译的过程,直接输出,反馈,而后吸收的过程建模为一个online learning过程。
0x2:FBIF算法模型
FBIF本质上还是一个异常点预测函数,模型产出的对应数据点的异常值,模型公式如下: ,x代表待预测样本点,w代表模型超参数。注意,这是一个半监督模型,超参数w是可以不断调整的。
,x代表待预测样本点,w代表模型超参数。注意,这是一个半监督模型,超参数w是可以不断调整的。
 这个函数是一个特征映射函数(feature function),用于将输入的样本向量转化到一个n维向量空间中,即:
这个函数是一个特征映射函数(feature function),用于将输入的样本向量转化到一个n维向量空间中,即: 。
。
这样讲可能有些抽象,以IF为例,输入样本示例是一个我们定义的向量(例如12维),通过IF之后形成了tree-based的结构,对IF中每棵树的每一条边e,定义:


这样我们将整个tree上的每一条边按照ont-hot形式进行编码,那么可以很容易想象,每一个leaf节点都会经过一定数量的边,例如一颗3层6个边的树,某个节点对应的树结构向量可能就是【1,1,1,0,0,0】,如下图所示:
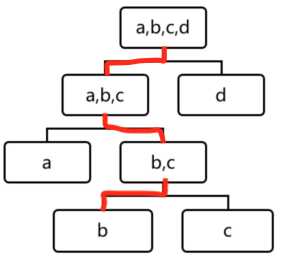
那函数有什么作用呢?我们先来直观理解一下,回到我们上面举得例子:
 ,同时看另一个叶节点
,同时看另一个叶节点
从IF的算法理论来看,叶节点d的异常度是比叶节点b的异常度要高的。原始的IF算法也就是基于这点对“不同深度”的叶节点得出不同的异常度的。并且,原始IF,每个边的权重都相等,因此节点的异常值完全取决于映射后得到的向量,也即越浅层的叶节点越异常。
回到FBIF的公式上来:,FBIF给每个边一个权重 ,同时满足
,同时满足 ,即树中所有的边和权重w进行向量相乘和总的概率分配和为1.
,即树中所有的边和权重w进行向量相乘和总的概率分配和为1.
权重w是由feedback反馈(有监督标签)驱动调整的,因此,score越大意味着异常度越高,score越小意味着异常度越小,这就构成了一个有监督线性回归模型(也即原文说的generalized linear anomaly detectors (GLADs))的回归训练过程。
很显然,IF算法是固定的这里不再赘述,读者朋友可以参阅另一篇blog。 我们本文主要讨论的是权重w是如何调整的,这是FBIF的重点。
0x3:online convex optimization(OCO) - 有监督参数调整过程
FBIF的主体框架采用了online convex optimization(OCO)框架来描述该过程,可以理解为:我们是在一个对抗性的环境循环地一轮轮做游戏的过程,其中每一轮我们的行动(action)是选择convex set S中的向量,在游戏的第t步,过程如下:
- 1. 我们选择

- 2. 环境选择一个凸函数

- 3. 我们得到损失

详细的算法流程如下:

我们接下来逐个讨论各个子环节。
1. Select a vector wt for the abnormal detector
注意,OCO是一个不断迭代循环的过程,模型不仅产出“suspicious abnormal instance”给反馈者,同时上一轮反馈者给的feedback也会影响这一轮的模型预测结果,是一个递归过程。
 ,w的维度等于树中边的数量。
,w的维度等于树中边的数量。
特别的, ,初始状态和传统IF是一样的,所有边的权重都相等。
,初始状态和传统IF是一样的,所有边的权重都相等。
OCO框架采用了正则化技术,使用L2范数进行差异评估,关于正则化技术的讨论可以参阅另一篇blog。
另外,在论文中选用了tree-based的anomaly detect function,所以对权重w的限制是非负,这点在写代码的时候需要注意。
2. Find top anomaly score‘s instance
接下来按照IF的传统过程得到映射后向量,并乘上权重参数w,根据异常值score得到一组top anomaly instance。
3. Get feedback
yt = +1:alien yt = −1:nominal
4. 无放回反馈
注意,上面算法流程图中, ,FBIF每轮反馈后的样本点是不参与下一轮的反馈抽样的。理论上说,不断循环下去,所有的样本都会得到一次反馈,最终半监督过程彻底演化为完全的有监督过程。
,FBIF每轮反馈后的样本点是不参与下一轮的反馈抽样的。理论上说,不断循环下去,所有的样本都会得到一次反馈,最终半监督过程彻底演化为完全的有监督过程。
但是在实际工程项目中,基本上,样本集D是一个天文数字,在笔者所在的网络安全攻防场景更是家常便饭,所以人工反馈最多只能完成最多上万次的反馈,一般通过上千次的反馈后,FBIF模型就会完成收敛。
5. Use yt to calculate Loss Function
接下来的问题如何将反馈转换为可优化的数值函数,以便进行最优逼近,例如梯度下降。
基本上来说:
yt = +1:loss值要更小 yt = -1:loss值要相对更大
损失函数的总体目的是在整个比赛中(所有的t轮次)之后,总体的损失最小,所以这是一个符合贪婪模式的迭代式优化算法。
文章列举了loss function function的两种定义方式,这也是我们很熟悉的线性回归中的损失函数,这部分的讨论其实和线性回归没有本质的原理区别。
1)Linear Loss
![]()
2)Log-likelihood Loss
![]() ,其中,
,其中,![]()
6. Update the weight vector
得到了损失函数的形式和计算方法之后,通过梯度下降对权重参数进行更新。
0x4:算法运行过程概述
- 初始化(只运行一次):基于数据集训练初始化IF,根据树结构得到映射函数,并初始化边权重。
- 循环运行OCO反馈过程,并不断调整权重w。在OCO优化过程中,树结构是不变的,也即映射函数是不变的,变动的只有权重w。
- 达到收敛条件,例如反馈人员精疲力竭、全部样本都反馈一遍了、达到设定的最大迭代次数。
该算法的时间复杂度很低,它的主要计算开销集中在初始化训练IF,在迭代过程中得益于online setting可以实现增量更新,其时间成本几乎可忽略不计。
可以看到,人工的反馈相当于加入了一种梯度方向,在原始Unsupervised Dection algorithm的基础上,强行“影响”了训练过程中参数的调整方向,最终得到的模型参数是“数据+人经验”综合影响的结果。这可以理解为是一种加入了先验知识的模型训练。
不太严谨地一个比喻,我们可以将原本IF预测函数有一个超判别面(超矩形),现在加入了feedback之后,又一只手强行扭动这个超判别面的形状,将其尽量地扭成符合业务场景中关注的异常和正常的真值概率边界位置,这个扭动的力度和程度就取决于feedback反馈进行的次数以及每次反馈的样例数。
5. 通过一个例子来看FBIF的直观效果
$ cd test $ ../iforest.exe -i datasets/anomaly/ann_thyroid_1v3/fullsamples/ann_thyroid_1v3_1.csv -o outtest/ann_thyroid_1v3_1 -t 100 -s 256 -m 1 -x 5 -f 10 -w 2 -l 2 -a 1 # Trees = 100 # Samples = 256 MaxHeight = 0 Orig Dimension = 3251,21 # Iterations = 128 # 迭代1024次 # Feedbacks = 10 # 返回10个top异常样本的label结果 Loss type = logistic Update type = online Num Grad Upd = 1 Reg. Constant = 0 Learning Rate = 1 Variable LRate = 0 Positive W only = 0 ReInitWgts = 0 Regularizer type = L2
程序对一个数据集同时进行了IF和FBIF过程,注意,最好运行1024次以上,比较容易看出数据趋势。运行结束后可以得到两个不同的文件:
# IF运行结果 "ann_thyroid_1v3_1_summary_feed_0_losstype_logistic_updatetype_online_ngrad_1_reg_0_lrate_1_pwgt_0_inwgt_0_rtype_L2.csv" iter,feed1,feed2,feed3,feed4,feed5,feed6,feed7,feed8,feed9,feed10 1,0,1,1,1,1,2,3,3,4,4 2,1,1,2,2,2,2,3,3,4,5 3,0,0,1,1,1,2,2,2,2,2 4,0,0,1,2,2,2,3,4,4,5 5,1,1,1,1,1,1,2,2,2,2 6,1,1,1,1,2,2,2,2,2,3 7,1,1,1,1,1,1,1,1,2,2 8,0,0,0,1,1,2,3,3,3,3 9,0,0,0,1,2,2,2,2,2,2 10,0,1,1,1,1,1,1,1,1,1 11,1,1,1,1,2,2,2,2,2,2 12,0,1,1,1,1,2,2,2,2,2 13,0,0,1,2,2,2,2,2,3,3 14,0,1,1,1,1,2,2,2,2,2 15,0,0,0,0,1,1,1,1,1,2 16,0,1,1,2,2,2,2,2,2,2 17,0,1,1,2,2,2,2,2,2,2 18,1,1,2,2,2,2,3,3,3,3 19,0,1,1,1,1,1,1,1,2,2 20,0,0,0,0,1,1,1,1,1,1 21,0,0,1,2,2,2,3,3,4,5 22,0,1,1,1,1,1,1,1,1,1 # FBIF运行结果 "ann_thyroid_1v3_1_summary_feed_10_losstype_logistic_updatetype_online_ngrad_1_reg_0_lrate_1_pwgt_0_inwgt_0_rtype_L2.csv" iter,feed1,feed2,feed3,feed4,feed5,feed6,feed7,feed8,feed9,feed10 1,0,1,2,3,3,4,5,6,7,8 2,1,2,3,4,4,5,6,7,8,9 3,0,0,1,2,2,3,4,5,6,7 4,0,0,1,2,3,4,5,6,7,8 5,1,2,3,3,4,5,6,7,8,9 6,1,2,2,3,4,5,6,7,8,9 7,1,2,2,2,3,4,5,6,7,7 8,0,0,0,1,2,2,3,4,5,6 9,0,0,0,1,2,3,3,4,5,6 10,0,1,1,2,3,4,4,5,6,7 11,1,2,2,3,4,5,6,7,8,9 12,0,1,2,3,3,4,5,6,7,8 13,0,0,1,2,3,3,4,5,6,7 14,0,1,2,3,3,4,5,6,7,8 15,0,0,0,0,1,2,2,2,3,4 16,0,1,2,2,3,4,5,6,7,8 17,0,1,2,3,3,3,4,5,6,7 18,1,2,3,4,5,6,7,7,8,9 19,0,1,2,2,2,2,2,2,2,3 20,0,0,0,0,1,2,3,4,5,6 21,0,0,1,2,3,3,4,5,6,7 22,0,1,2,2,2,2,2,2,2,2 23,0,1,2,2,3,4,5,6,7,8 24,0,0,1,2,2,3,4,5,6,7 25,0,0,1,2,3,4,4,5,6,7 26,0,0,1,2,3,4,5,5,6,7
咋一看好像看不出有什么区别,我们接下来从几个角度来分析一下结果数据:
0x1:算法收敛速度对比
我们先对两个文件进行unique处理,结果如下:
# IF过程 1024 -> 230:压缩率 = 77.5% # FBIF过程 1024 -> 138:压缩率 = 86.7%
压缩率越低,意味着预测结果的概率分布越分散,即不集中。
这个结果可以这么理解,IF是基于随机过程进行特征选择和切分阈值选择的,随机性很高,不容易收敛。
而FBIF因为加入了feedback的拟合过程,随着梯度下降的训练,模型逐渐向feedback的梯度方向拟合,因此收敛速度更快。
0x2:算法拟合能力对比
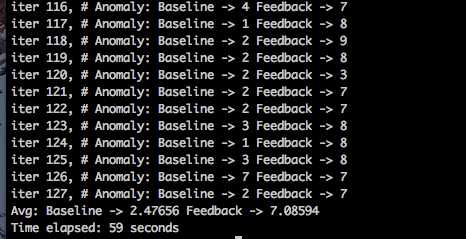
再来看IF和FBIF的平均反馈值:
Avg: Baseline -> 2.31934 Feedback -> 6.70898
可以看到,FBIF比IF的平均异常反馈要高很多,这意味着,FBIF算法产出的异常值,更有可能是业务场景中关心的异常点(也即和label更靠近)。
再来看最后一次预测结果的召回对比:
# FBIF 1024,1,2,3,4,5,6,6,7,8,9 # IF 1024,1,2,2,2,2,2,2,2,2,3
FBIF的召回率已经比开始时有很大提升,而IF依然和初始时没有太多变化。
从这里也看出,IF算法不需要迭代运行多次,一次运行和多次运行的结果没有太多区别。
Relevant Link:
https://github.com/siddiqmd/FeedbackIsolationForest
以上是关于简要介绍Active Learning(主动学习)思想框架,以及从IF(isolation forest)衍生出来的算法:FBIF(Feedback-Guided Anomaly Discovery)的主要内容,如果未能解决你的问题,请参考以下文章