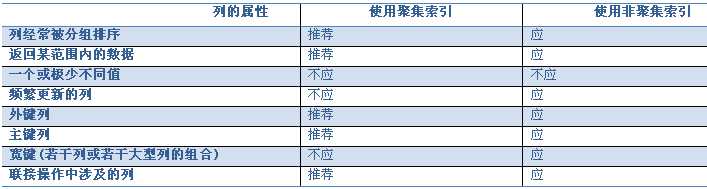
2.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
3.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20
5.下面的查询也将导致全表扫描:(不能前置百分号) select id from t where name like ‘%abc%’ 若要提高效率,可以考虑全文检索。
6.in 和 not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了: select id from t where num between 1 and 3
select xx,phone FROM send a JOIN ( select ‘13891030091‘ phone union select ‘13992085916‘ ………… UNION SELECT ‘13619100234‘ ) b on a.Phone=b.phone --替代下面 很多数据隔开的时候 in(‘13891030091‘,‘13992085916‘,‘13619100234‘…………)
7.如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描: select id from t where [email protected] 可以改为强制查询使用索引: select id from t with(index(索引名)) where num[email protected]
8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2=100 应改为: select id from t where num=100*2
9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where substring(name,1,3)=’abc’–name以abc开头的id select id from t where datediff(day,createdate,’2005-11-30′)=0–’2005-11-30′生成的id 应改为: select id from t where name like ‘abc%’ select id from t where createdate>=’2005-11-30′ and createdate<’2005-12-1′
10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
12.不要写一些没有意义的查询,如需要生成一个空表结构: select col1,col2 into #t from t where 1=0 这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样: create table #t(…)
13.很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num)
6、扩大服务器的内存,Windows 2000和SQL server 2000能支持4-8G的内存。配置虚拟内存:虚拟内存大小应基于计算机上并发运行的服务进行配置。运行 Microsoft SQL Server? 2000 时,可考虑将虚拟内存大小设置为计算机中安装的物理内存的 1.5 倍。如果另外安装了全文检索功能,并打算运行 Microsoft 搜索服务以便执行全文索引和查询,可考虑:将虚拟内存大小配置为至少是计算机中安装的物理内存的 3 倍。将 SQL Server max server memory 服务器配置选项配置为物理内存的 1.5 倍(虚拟内存大小设置的一半)。
8、如果是使用like进行查询的话,简单的使用index是不行的,但是全文索引,耗空间。 like ‘a%‘ 使用索引 like ‘%a‘ 不使用索引用 like ‘%a%‘ 查询时,查询耗时和字段值总长度成正比,所以不能用CHAR类型,而是VARCHAR。对于字段的值很长的建全文索引。
9、DB Server 和APPLication Server 分离;OLTP和OLAP分离
10、分布式分区视图可用于实现数据库服务器联合体。联合体是一组分开管理的服务器,但它们相互协作分担系统的处理负荷。这种通过分区数据形成数据库服务器联合体的机制能够扩大一组服务器,以支持大型的多层 Web 站点的处理需要。有关更多信息,参见设计联合数据库服务器。(参照SQL帮助文件‘分区视图‘) a、在实现分区视图之前,必须先水平分区表 b、在创建成员表后,在每个成员服务器上定义一个分布式分区视图,并且每个视图具有相同的名称。这样,引用分布式分区视图名的查询可以在任何一个成员服务器上运行。系统操作如同每个成员服务器上都有一个原始表的复本一样,但其实每个服务器上只有一个成员表和一个分布式分区视图。数据的位置对应用程序是透明的。
SELECT top 20 ad.companyname,comid,position,ad.referenceid,worklocation,
convert(varchar(10),ad.postDate,120) as ostDate1,workyear,degreedescription
FROM jobcn_query.dbo.COMPANYAD_query ad
where referenceID in(‘JCNAD00329667‘,‘JCNAD132168‘,‘JCNAD00337748‘,‘JCNAD00338345‘,‘JCNAD00333138‘,‘JCNAD00303570‘,
‘JCNAD00303569‘,‘JCNAD00303568‘,‘JCNAD00306698‘,‘JCNAD00231935‘,‘JCNAD00231933‘,‘JCNAD00254567‘,
‘JCNAD00254585‘,‘JCNAD00254608‘,‘JCNAD00254607‘,‘JCNAD00258524‘,‘JCNAD00332133‘,‘JCNAD00268618‘,‘JCNAD00279196‘,‘JCNAD00268613‘)
order by postdate desc
35、在IN后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数
36、当用SELECT INTO时,它会锁住系统表(sysobjects,sysindexes等等),阻塞其他的连接的存取。创建临时表时用显示申明语句,而不是 select INTO. drop table t_lxh begin tran select * into t_lxh from chineseresume where name = ‘XYZ‘ --commit 在另一个连接中SELECT * from sysobjects可以看到 SELECT INTO 会锁住系统表,Create table 也会锁系统表(不管是临时表还是系统表)。所以千万不要在事物内使用它!!!这样的话如果是经常要用的临时表请使用实表,或者临时表变量。
37、一般在GROUP BY 个HAVING字句之前就能剔除多余的行,所以尽量不要用它们来做剔除行的工作。他们的执行顺序应该如下最优:select 的Where字句选择所有合适的行,Group By用来分组个统计行,Having字句用来剔除多余的分组。这样Group By 个Having的开销小,查询快.对于大的数据行进行分组和Having十分消耗资源。如果Group BY的目的不包括计算,只是分组,那么用Distinct更快
38、一次更新多条记录比分多次更新每次一条快,就是说批处理好
39、少用临时表,尽量用结果集和Table类性的变量来代替它,Table 类型的变量比临时表好
40、在SQL2000下,计算字段是可以索引的,需要满足的条件如下:
a、计算字段的表达是确定的 b、不能用在TEXT,Ntext,Image数据类型 c、必须配制如下选项 ANSI_NULLS = ON, ANSI_PADDINGS = ON, …….
46、通过SQL Server Performance Monitor监视相应硬件的负载 Memory: Page Faults / sec计数器如果该值偶尔走高,表明当时有线程竞争内存。如果持续很高,则内存可能是瓶颈。 Process:
1、% DPC Time 指在范例间隔期间处理器用在缓延程序调用(DPC)接收和提供服务的百分比。(DPC 正在运行的为比标准间隔优先权低的间隔)。 由于 DPC 是以特权模式执行的,DPC 时间的百分比为特权时间 百分比的一部分。这些时间单独计算并且不属于间隔计算总数的一部 分。这个总数显示了作为实例时间百分比的平均忙时。 2、%Processor Time计数器 如果该参数值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。 3、% Privileged Time 指非闲置处理器时间用于特权模式的百分比。(特权模式是为操作系统组件和操纵硬件驱动程序而设计的一种处理模式。它允许直接访问硬件和所有内存。另一种模式为用户模式,它是一种为应用程序、环境分系统和整数分系统设计的一种有限处理模式。操作系统将应用程序线程转换成特权模式以访问操作系统服务)。 特权时间的 % 包括为间断和 DPC 提供服务的时间。特权时间比率高可能是由于失败设备产生的大数量的间隔而引起的。这个计数器将平均忙时作为样本时间的一部分显示。 4、% User Time表示耗费CPU的数据库操作,如排序,执行aggregate functions等。如果该值很高,可考虑增加索引,尽量使用简单的表联接,水平分割大表格等方法来降低该值。 Physical Disk: Curretn Disk Queue Length计数器该值应不超过磁盘数的1.5~2倍。要提高性能,可增加磁盘。 SQLServer:Cache Hit Ratio计数器该值越高越好。如果持续低于80%,应考虑增加内存。 注意该参数值是从SQL Server启动后,就一直累加记数,所以运行经过一段时间后,该值将不能反映系统当前值。
47、分析select emp_name form employee where salary > 3000 在此语句中若salary是Float类型的,则优化器对其进行优化为Convert(float,3000),因为3000是个整数,我们应在编程时使用3000.0而不要等运行时让DBMS进行转化。同样字符和整型数据的转换。
--查找所有索引
SELECT ‘dbcc showcontig (‘ + CONVERT(VARCHAR(20), i.id) + ‘,‘ + -- table id
CONVERT(VARCHAR(20), i.indid) + ‘)--‘ + --index id
OBJECT_NAME(i.id) + ‘.‘ + -- table name
i.name--index name
FROM sysobjects o
INNER JOIN sysindexes i ON ( o.id = i.id )
WHERE o.type = ‘U‘
AND i.indid < 2
AND i.id = OBJECT_ID(o.name)
ORDER BY OBJECT_NAME(i.id), i.indid
–结果
dbcc showcontig (2052202361,1)–AddBusiness.PK_AddBusiness