自定义类实现原生SQL的GROUP_CONCAT的功能
Posted paulwhw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自定义类实现原生SQL的GROUP_CONCAT的功能相关的知识,希望对你有一定的参考价值。
大家都知道,原生的SQL为我们提供了分组之后查找组内数据的办法:GROUP_CONCAT方法;但是对于用Django开发的程序员来说~Django自带的ORM并没有内置这样功能的方法,而每一次遇到这样的需求如果都要用原生SQL去解决的话势必会降低我们的开发效率。
本文为大家介绍一种在Django项目中自定义类Coucat类的方式去实现对应的效果。
表关系
现在假设我们的Django项目的book应用中有两张关联的表:book表与publish表。表结构如下:
book表:
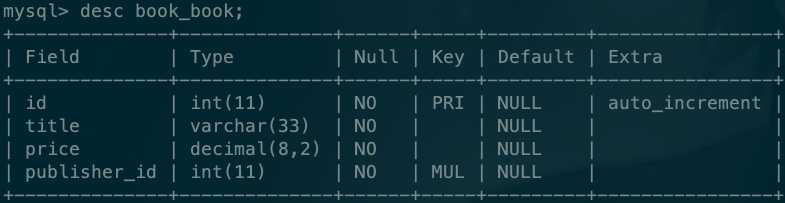
publish表:
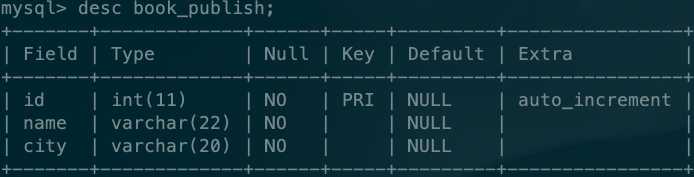
其中:book表的publisher_id是通过ORM语法与publish表建立关联的外键字段。
原生SQL中GROUP_CONCAT的分组查询
单表下的分组查询
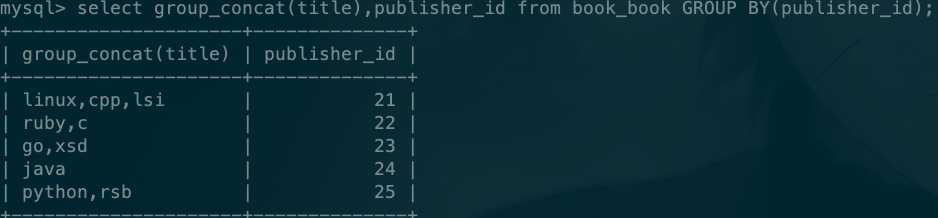
按照publisher_id分组查询每组数据下的书名:
select group_concat(title),publisher_id from book_book GROUP BY(publisher_id);
结果如下:
连表下的分组查询
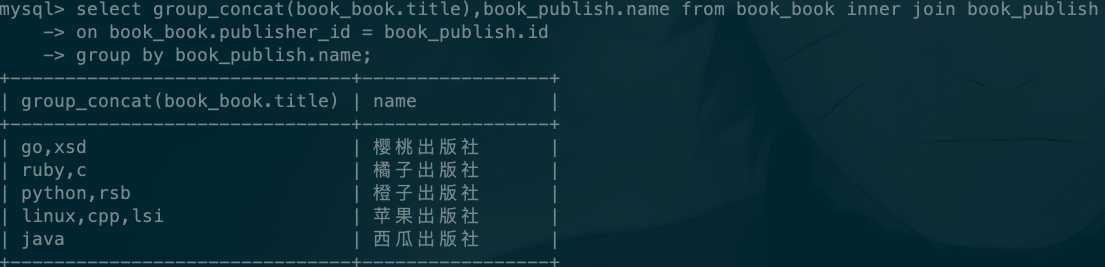
查找每个出版社出版的书籍的名称
select group_concat(book_book.title),book_publish.name from book_book inner join book_publish on book_book.publisher_id = book_publish.id group by book_publish.name;
结果如下:
ORM中自定义Concat类实现COUCAT_GROUP的效果
在我们Django项目中的lib目录下新建一个concat.py文件,文件中的内容如下:
# -*- coding:utf-8 -*- from django.db.models import Aggregate,CharField class Concat(Aggregate): function = ‘GROUP_CONCAT‘ template = ‘%(function)s(%(distinct)s%(expressions)s)‘ def __init__(self,expression,distinct=False,**extra): super(Concat,self).__init__( expression, distinct=‘DISTINCT‘ if distinct else ‘‘, output_field=CharField(), **extra)
以上的代码就是我们实现COUCAT_GROUP效果的类。
然后,创建一条测试路由:
url(r‘^concat/‘,views.concat),
视图函数中concat函数实现具体的功能:
from django.shortcuts import HttpResponse from lib.concat import Concat def concat(request): # 单表:用publisher_id分组,找每个分组中的书籍名称 ret = Book.objects.values(‘publisher_id‘).annotate(titles=Concat(‘title‘)) print(ret) #<QuerySet [{‘publisher_id‘: 21, ‘titles‘: ‘linux,cpp,lsi‘}, {‘publisher_id‘: 22, ‘titles‘: ‘ruby,c‘}, # {‘publisher_id‘: 23, ‘titles‘: ‘go,xsd‘}, {‘publisher_id‘: 24, ‘titles‘: ‘java‘}, {‘publisher_id‘: 25, ‘titles‘: ‘python,rsb‘}]> #跨表:每个出版社出版的所有的书籍 #方法一:以publish表为基准去查 ret = Publish.objects.values(‘name‘).annotate(titles=Concat(‘book__title‘)) print(ret) #<QuerySet [{‘name‘: ‘樱桃出版社‘, ‘titles‘: ‘go,xsd‘}, {‘name‘: ‘橘子出版社‘, ‘titles‘: ‘ruby,c‘}, # {‘name‘: ‘橙子出版社‘, ‘titles‘: ‘python,rsb‘}, {‘name‘: ‘苹果出版社‘, ‘titles‘: ‘linux,cpp,lsi‘}, {‘name‘: ‘西瓜出版社‘, ‘titles‘: ‘java‘}]> #方法二:以book表为基准去查 ret = Book.objects.values(‘publisher__name‘).annotate(titles=Concat(‘title‘)) print(ret) #<QuerySet [{‘publisher__name‘: ‘樱桃出版社‘, ‘titles‘: ‘go,xsd‘}, {‘publisher__name‘: ‘橘子出版社‘, ‘titles‘: ‘ruby,c‘}, # {‘publisher__name‘: ‘橙子出版社‘, ‘titles‘: ‘python,rsb‘}, {‘publisher__name‘: ‘苹果出版社‘, ‘titles‘: ‘linux,cpp,lsi‘}, # {‘publisher__name‘: ‘西瓜出版社‘, ‘titles‘: ‘java‘}]> return HttpResponse(‘Concat‘)
大家可以看到,用法也十分简单,只需要在分组的annotate方法中加上我们定义的这个类就可以了~
以上是关于自定义类实现原生SQL的GROUP_CONCAT的功能的主要内容,如果未能解决你的问题,请参考以下文章