大数据零基础学习hadoop入门教程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据零基础学习hadoop入门教程相关的知识,希望对你有一定的参考价值。
1、Hadoop生态概况Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠、高效、可伸缩的特点
Hadoop的核心是YARN,HDFS,Mapreduce,常用模块架构如下
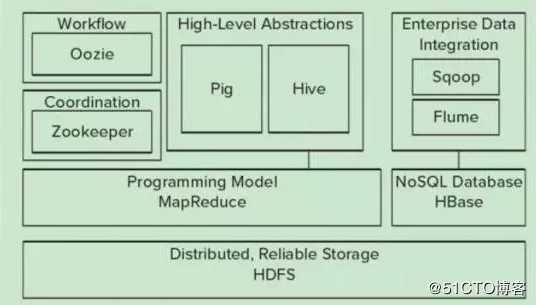
?
2、HDFS
源自谷歌的GFS论文,发表于2013年10月,HDFS是GFS的克隆版,HDFS是Hadoop体系中数据存储管理的基础,它是一个高度容错的系统,能检测和应对硬件故障
HDFS简化了文件一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序,它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器
3、Mapreduce
源自于谷歌的MapReduce论文,用以进行大数据量的计算,它屏蔽了分布式计算框架细节,将计算抽象成map和reduce两部分
4、HBASE(分布式列存数据库)
源自谷歌的Bigtable论文,是一个建立在HDFS之上,面向列的针对结构化的数据可伸缩,高可靠,高性能分布式和面向列的动态模式数据库
5、zookeeper
解决分布式环境下数据管理问题,统一命名,状态同步,集群管理,配置同步等
6、HIVE
由Facebook开源,定义了一种类似sql查询语言,将SQL转化为mapreduce任务在Hadoop上面执行
7、flume
日志收集工具
8、yarn分布式资源管理器
是下一代mapreduce,主要解决原始的Hadoop扩展性较差,不支持多种计算框架而提出的,架构如下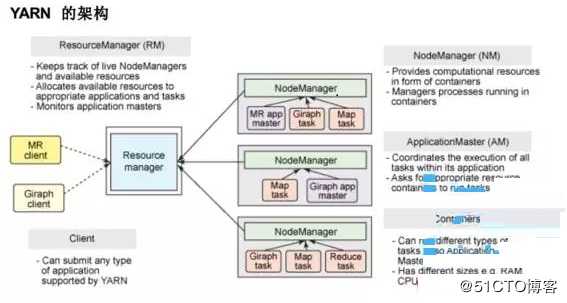
?
对大数据以及人工智能概念都是模糊不清的,该按照什么线路去学习,学完往哪方面发展,想深入了解,想学习的同学欢迎加入大数据学习裙:606859705,有大量干货(零基础以及进阶的经典实战)分享给大家,让大家了解到目前国内最完整的大数据高端实战实用学习流程体系 。从java和linux入手,其后逐步的深入到HADOOP-hive-oozie-web-flume-python-hbase-kafka-scala-SPARK等相关知识一一分享!
?
9、spark
spark提供了一个更快更通用的数据处理平台,和Hadoop相比,spark可以让你的程序在内存中运行
10、kafka
分布式消息队列,主要用于处理活跃的流式数据
11、Hadoop伪分布式部署
目前而言,不收费的Hadoop版本主要有三个,都是国外厂商,分别是
1、Apache原始版本
2、CDH版本,对于国内用户而言,绝大多数选择该版本
3、HDP版本
这里我们选择CDH版本hadoop-2.6.0-cdh5.8.2.tar.gz,环境是CentOS7.1,jdk需要1.7.0_55以上
[[email protected] ~]# useradd hadoop
我的系统默认自带的java环境如下
?
?
增加如下环境变量
?
?
做好如下授权
?

?
这里以Hadoop用户来进行管理和启动Hadoop的各种服务
?
?
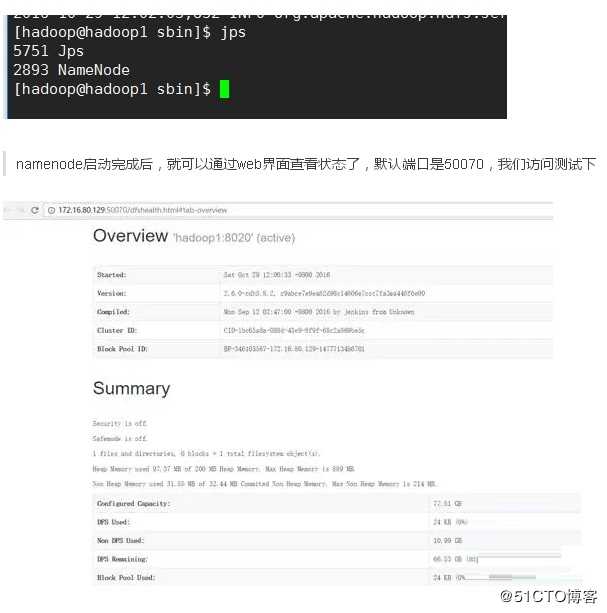
查看服务启动情况
?
以上是关于大数据零基础学习hadoop入门教程的主要内容,如果未能解决你的问题,请参考以下文章