机器学习:机器学习的一个实例
Posted freeself
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习:机器学习的一个实例相关的知识,希望对你有一定的参考价值。
大家都知道tensorflow(简称tf)是一个机器学习的框架,使用它就可以完成机器学习。那就用tf来演示一下怎么做机器学习吧,这样你就有一个具体的感受:原来是这样的啊!
本文使用tensorflow做一次机器学习的演示。 但是,tensorflow的理解跟使用,是可以作为一个独立的专题来讲解的,这个我再补充。
机器学习有两个关键点,一个是样本,一个是模型。样本的作用,包括用于训练(带标签)跟测试(带或不带标签),大量特征良好而标签准确的训练样本,是关键。模型,简单理解,就是一个函数,一个接受不断调整参数以达到最佳预测状态的函数,比如之前提到的简单线性回归模型。
本文的“原型”是这个地址:https://colab.research.google.com/notebooks/mlcc/first_steps_with_tensor_flow.ipynb?hl=zh-cn#scrollTo=9ivCDWnwE2Zx, 你可以查阅这个网页的内容。
我会尽量用自己的话来讲,突出重点,并且坚持“不要完整、不要完美”的思路。
(一)样本
不同的问题场景,使用不同的样本。有时,样本的获取或创建,是很耗时间,也是很关键的事情。
这里,要解决的问题,是“预测房价”,而样本已经有人准备好了,地址是这个:https://download.mlcc.google.com/mledu-datasets/california_housing_train.csv
对于样本的读取与分析,使用pandas(之前有单独介绍)。使用pandas读取时,可以直接读取这个地址,因为pandas支持联网的远程读取,也可以把这个文件下载到本地,再使用pandas来读取。
小程先下载这个样本文件,比如使用这个命令:
curl -o housing.csv "https://download.mlcc.google.com/mledu-datasets/california_housing_train.csv"
然后,使用pandas来读取,展示一些内容,并查看一般的统计信息:
执行这段代码,效果如下:
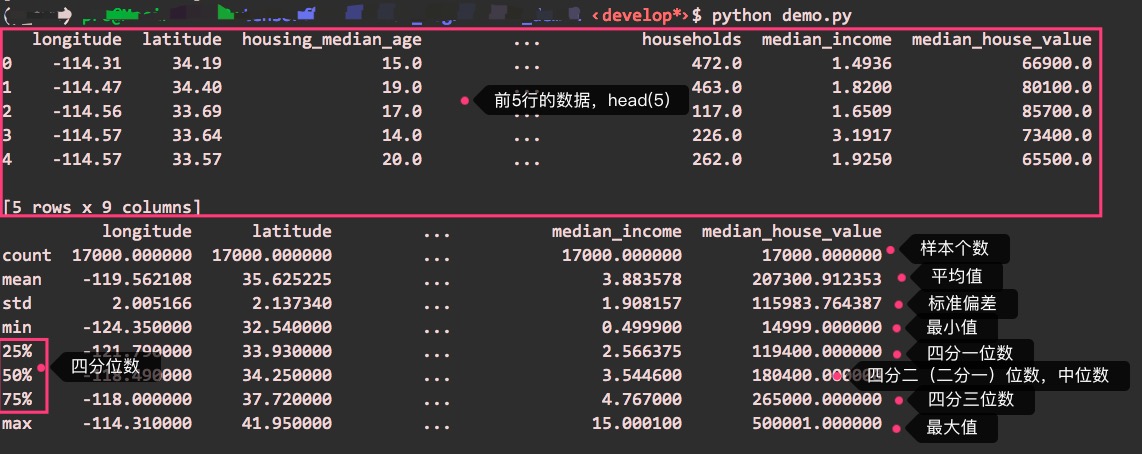
这个样本,是某个地区的房子的信息,小程的目标是根据这些信息,预测出在新的特征信息下(比如经纬度、房龄、面积等),会有什么样的median_house_value,即房子价值的中位数。
至此,已经解决了样本的问题,这个样本主要用于模型的训练。
(二)模型
先来回顾一下机器学习的工作图:
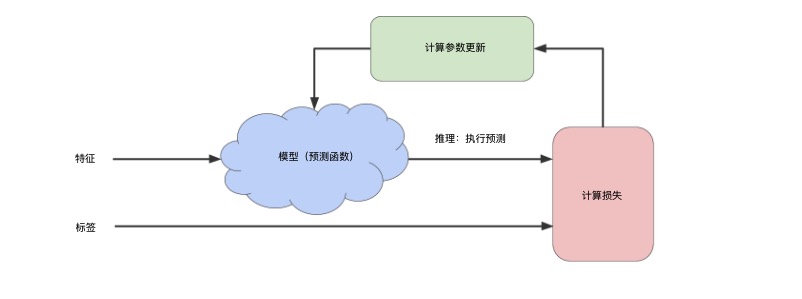
上图的整体,为机器的迭代学习过程。这里的“模型”,指的是整体的迭代学习过程,包括输入、预测模型、权重调整与损失计算。
为了更好地组织与实现学习过程,小程对上图的步骤加了划分,请留意下图的注释:
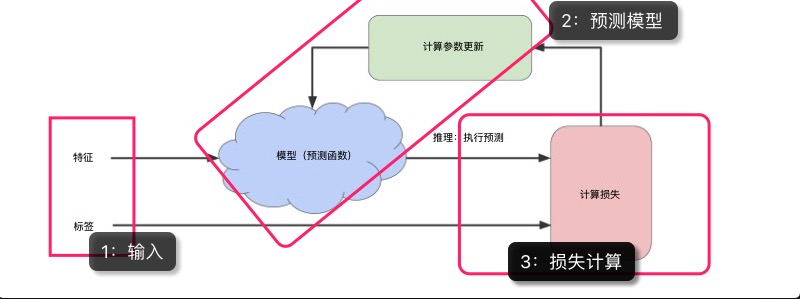
(1)输入
对于训练(即训练“预测模型”),需要输入特征与标签的组合(即样本)。这里,预测标签(也是目标)设定为房子价值的中位数即median_house_value,所以样本的标签也就设定为median_house_value。对于特征,为了演示上的简单,这里选择某个街道的房子总数即total_rooms做为单一特征。
于是,训练样本的特征与标签就确定下来了,可以这样写代码来获得:
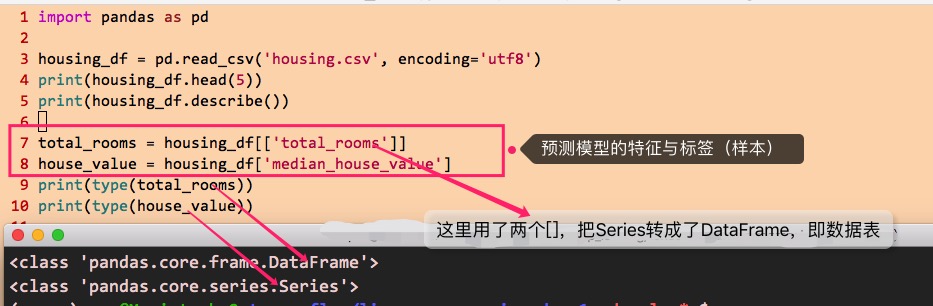
以上把特征与标签明确下来了,但是,在把样本(特征与标签的组合)设置给预测模型进行训练的时候,还有一些“预处理”可以实施以获得更好的训练效果,这个预处理,包括把样本转换成tensorflow的Dataset切片、是否随机抽取样本进行训练、数据重用的次数、迭代学习的次数、每次迭代使用的样本数,等等。
这个预处理,也叫“输入函数”,在预测模型执行训练时,需要指定输入函数。
在实现输入函数之前,先讲解几个概念。
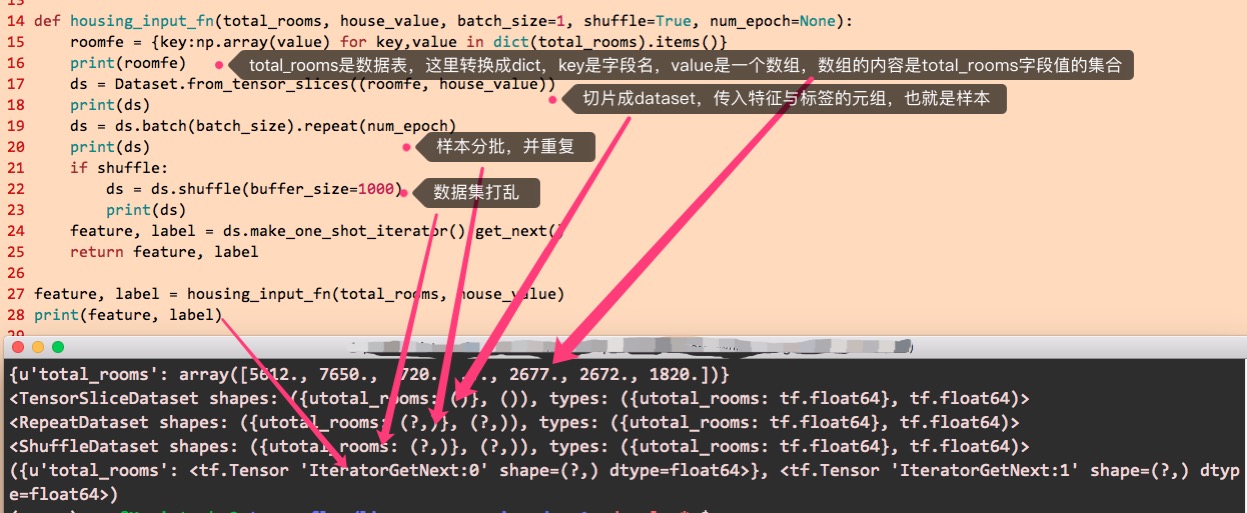
epoch,数据被(重复)使用的次数。比如epoch为1则所有样本只使用一次,epoch为2则所有样本使用两次。比如有三个样本为{a,b,c},epoch为2时,就是使用2次,变成{a,b,c,a,b,c},当然样本的顺序是可以打乱的。
迭代,一次迭代包括了标签预测、损失计算与权重调整的过程,一次迭代一般只使用小批量(batch_size个)样本。
step,迭代的总次数。
batch_size,每次迭代使用的样本的个数(并不一定要所有样本都使用上,比如小批量的梯度下降法)。
每次step(迭代),都调用一次输入函数,返回指定大小的数据集,直至step次数处理完,或者样本数据已经用完。
这个输入函数可以这样实现,请留意下图中的解释:
(2)预测模型
之前提到,简单线性回归是一个简单的预测模型,这个预测模型适用于从x到y的映射。本例中,就是从total_rooms预测出median_house_value,所以使用简单线性回归模型即可解决问题。
在tf.estimator模块中,有一个LinearRegressor类,它的对象就是一个线性回归模型。
在创建LinearRegressor模型时,需要指定调整模型参数的优化器,这里使用这前介绍的“小批量随机梯度下降”的优化器,代码如下:
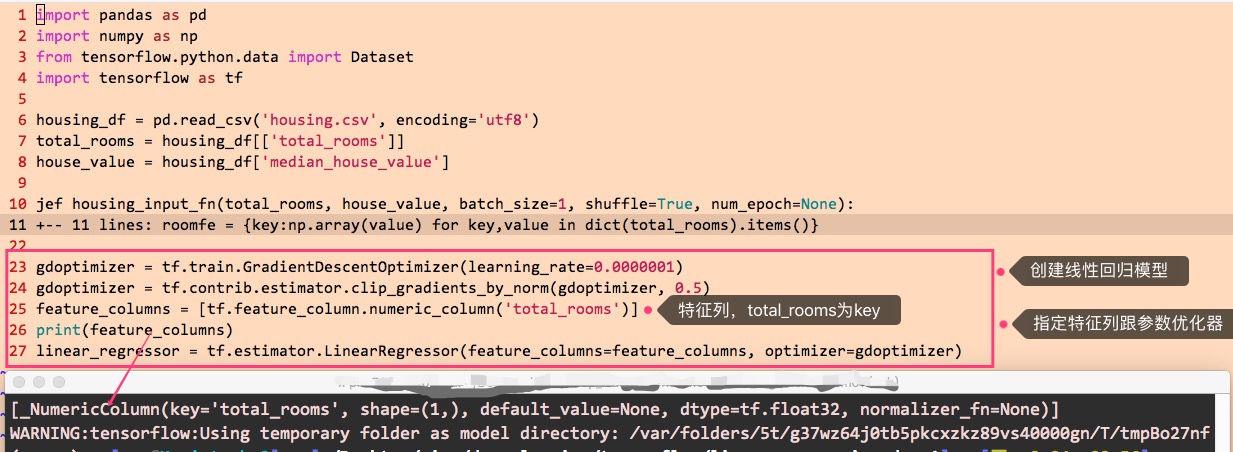
创建预测模型之后,就可以执行训练了:
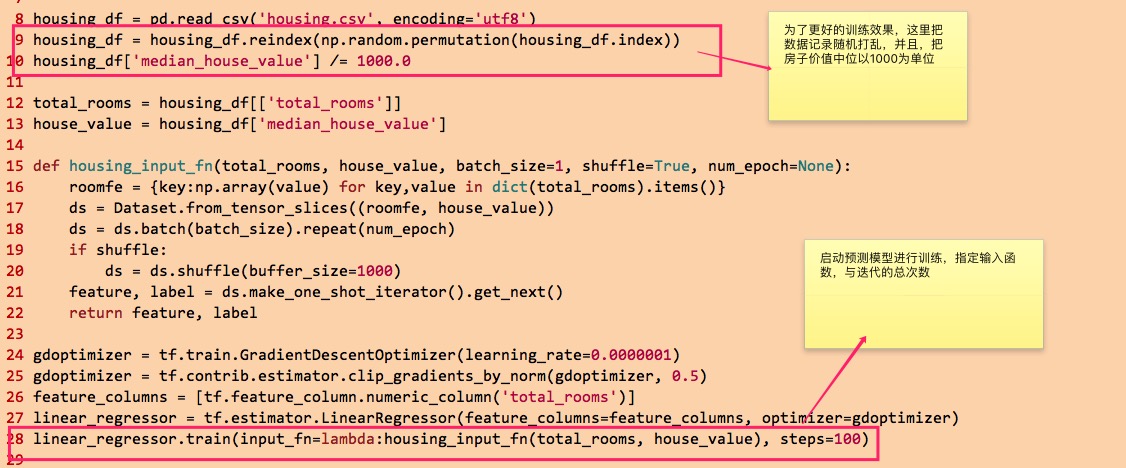
在创建预测模型时指定的梯度下降优化器,完成迭代学习过程中模型参数(比如权重)的调整。只要触发训练,这个优化器就会调整参数,这个过程不需要读者介入,包括下面的损失计算,也是优化器完成的工作。而我们进行损失计算,是为了观察收敛的情况,进而调整训练的参数,而不是模型的参数(如权重,这个是tensorflow的参数调整器来做的)。
(3)损失计算
预测模型在训练的过程中,会自动地,进行预测与损失计算,进而自动地调整模型的参数。
这一步,也叫评估。
需要注意,损失计算是创建预测模型时指定的优化器自动完成的事情,而这里计算损失,是为了调整模型的训练参数(比如步长、epoch等,这是你要做的事情)。
预测所有样本,得到预测值,再把预测值与真实的标签值,进行损失计算,分别计算出均方误差(MSE)跟均根方误差(RMSE),代码与执行效果如下:
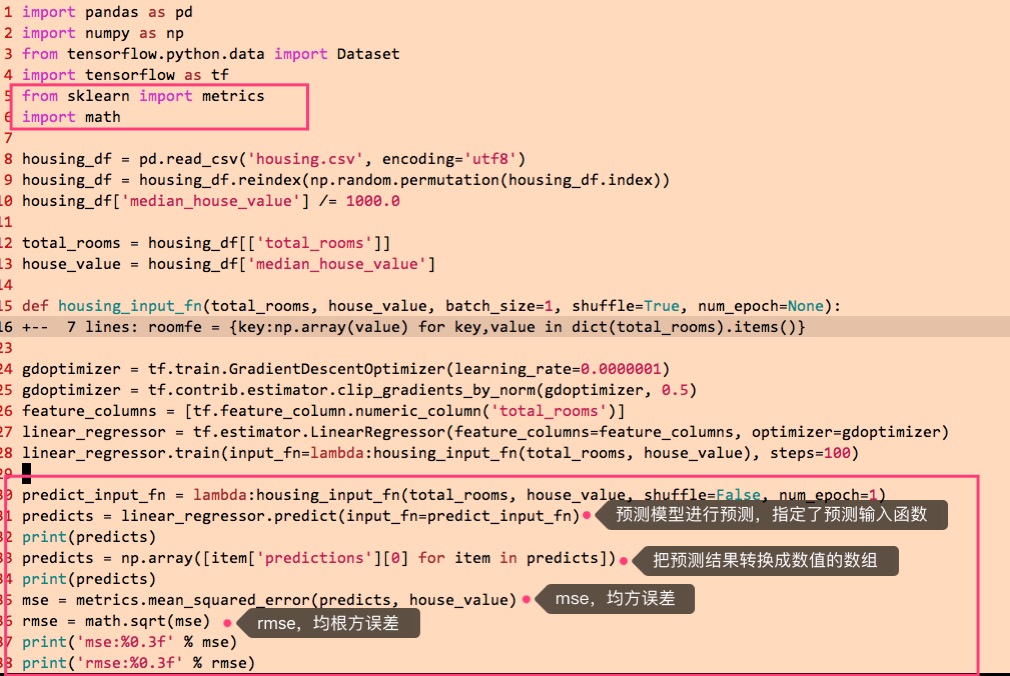

以上对所有样本进行了预测,并计算了误差MSE跟RMSE,一般来说根据RMSE进行误差大小的判断即可,那么,现在的RMSE值,到底有多大呢?可以看一下median_house_value的最大值跟最小值,再来理解一下,现在的RMSE值是一个什么样的概念,代码与效果如下:
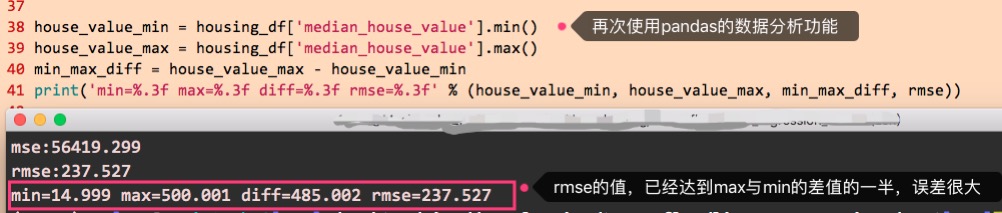
由上图的值来看,RMSE的值已经达到实际标签值的一半的误差,所以这个误差是巨大的。
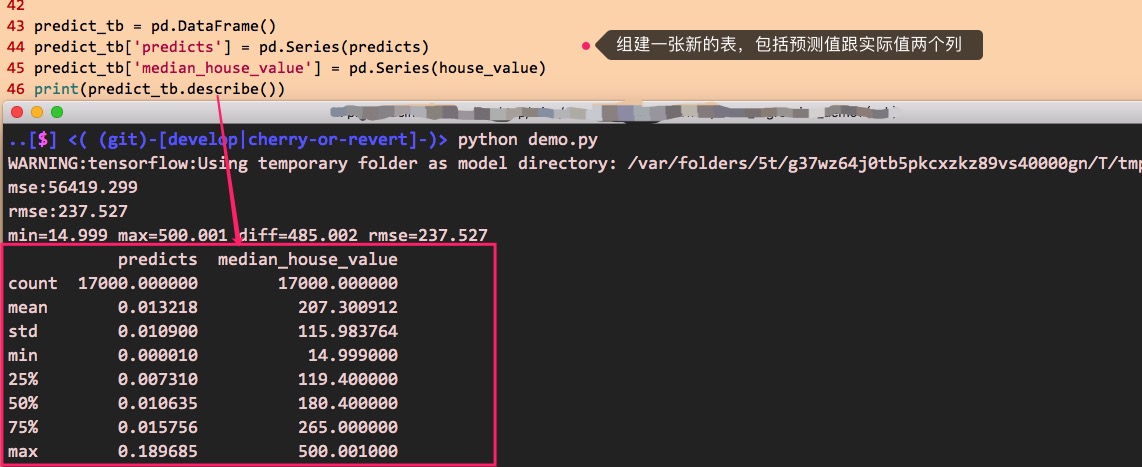
为了更直观地观察预测与实际值的差别,一个办法是使用pandas的统计分析来对比,另一个办法是绘制拟合线,这里分别演示一下。
以下代码使用pandas进行分析,对比预测与实际值的差别,代码与效果如下:
另一个办法是绘制当前误差下的拟合线,代码与效果如下:
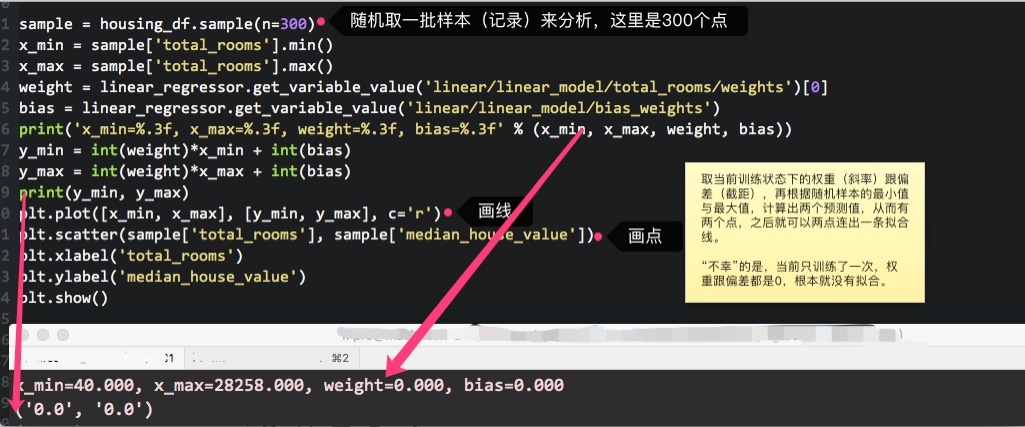
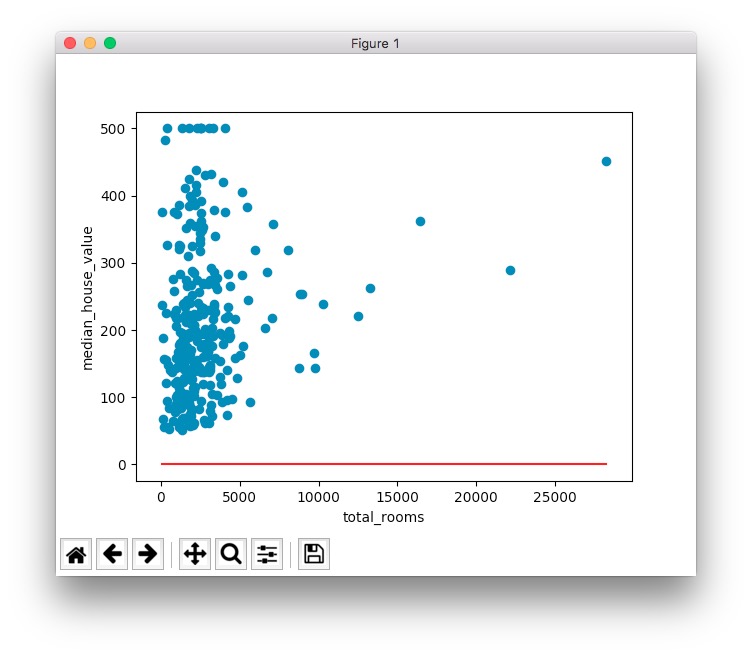
拟合线的目的是尽可能地拟合所有的点,但上图只训练了一次的模型,明显没有拟合的效果。为了得到更好的拟合效果,应该根据反馈的误差信息,调整训练参数,并进行反复的训练。
(三)调整训练参数
在样本跟模型(包括输入、创建预测模型、损失计算)确定下来之后,就可以反复地训练这个模型。
然后,根据反馈的误差信息,调整训练参数。
这里先“随意”地设置一下训练参数,再进行若干次训练,来观察一下误差的信息,把之前的代码调整一下,如下:
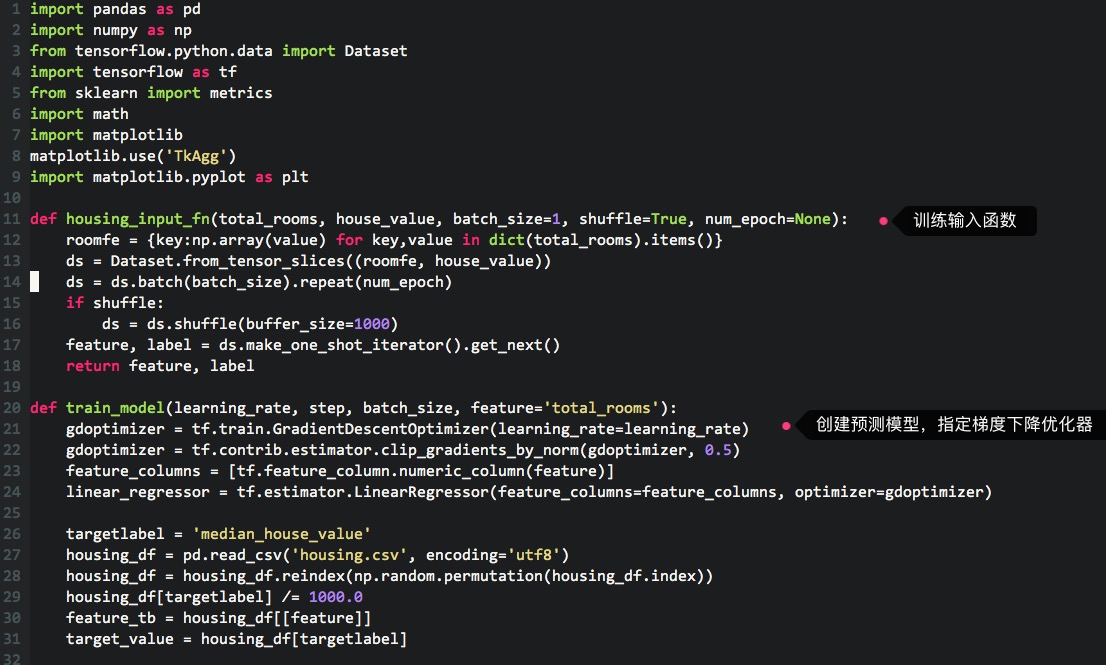
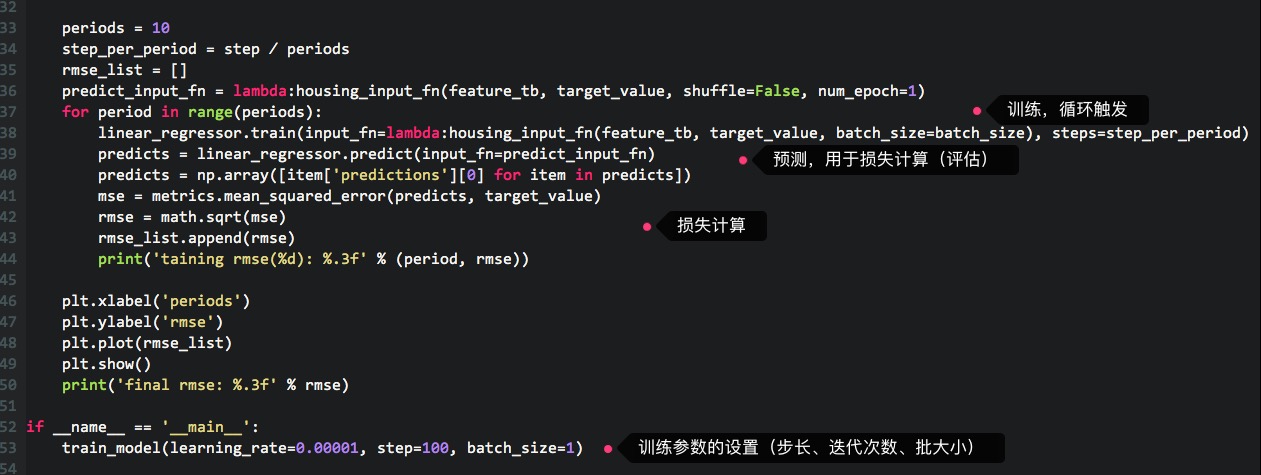
可以看到这样的输出:
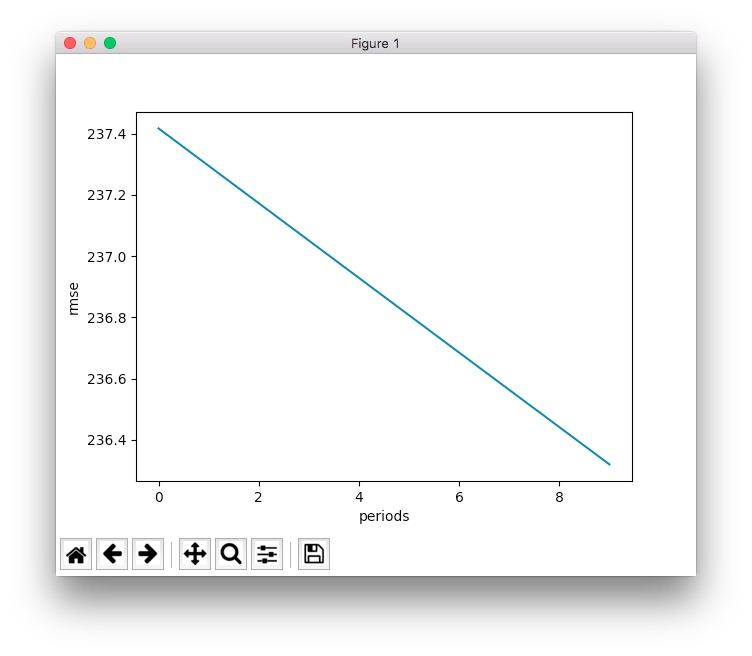
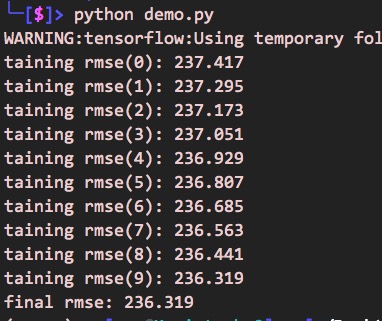
上面演示的最终误差还是很大,这时,为了让模型取得更好的收敛,应该调整训练参数,比如调整为:
train_model(learning_rate=0.0001, step=500, batch_size=10)
读者可以尝试使用不同的训练参数,并留意误差收敛的情况(某些训练参数下误差并不会一直减小)。
最终的效果,小程就不演示了,因为最终的效果不是重点,重点是你应该明白,为了取得更好的训练效果,应该根据样本的数量与质量(特征的质量)来调整训练参数(需要反复试验),一般来说,可以尝试使用较小的learning_rate+较大的step+较大的batch_size进行训练,但是,最终还是看效果,包括误差收敛情况,还有最终的使用情况。
调整训练参数,很有可能是一个反复试验的过程,就像是一个科学实验,不断重复“给出结论”、“验证”、“调整结论”再次“验证”的过程。
(四)使用模型进行预测
使用模型进行预测,也就是最终使用训练后的模型,属于测试模型的环节,方法类似于训练过程中的predict的使用,我记得在“音频标签化”的讲解时已经提过了,这里不细说。
再罗索一下。模型简单来说就是函数,一个接受调整参数的函数,可以不断进化,得到更好的预测效果。对于模型,如果你不会写,没有关系,tensorflow包括了一些有效的模型,而且连调整模型参数的梯度优化器也内置了(调整参数的过程不用你介入)。模型的训练参数怎么设置,是你要上心的,而训练参数的设置,跟样本的数量与质量都有关系,还跟你的经验有关系。另一方面,你最要上心的,是样本怎么来?你怎么获取或创建大量特征良好的用于训练的样本?你要花掉多少时间?
总结一下,本文演示了机器学习的一个实战的例子,流程上,包括样本的获取、模型的创建(包括样本输入、预测模型创建、梯度下降优化器指定、损失计算等)、训练与训练参数的调整、测试模型等。本文希望,能让你对传统机器学习的操作,有一个具体感性的认识。

以上是关于机器学习:机器学习的一个实例的主要内容,如果未能解决你的问题,请参考以下文章