使用selenium动态渲染爬取拉勾网上450个java职位的信息
Posted ouyangbo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用selenium动态渲染爬取拉勾网上450个java职位的信息相关的知识,希望对你有一定的参考价值。
开始这个小项目的时候要确保你的电脑中有装上selenium以及相应的浏览器驱动,还有别忘了Mongodb数据库
我们首先打开拉勾网的官网查看下基本的页面元素
当我在搜索框中输入java的时候,url如下,当我想用下面的url进行抓取的时候,我发现事情并不简单。
我点击下一页的时候发现,url并没有变化,所以并不能用最基本的抓取方法了,而改为ajax请求进行抓取
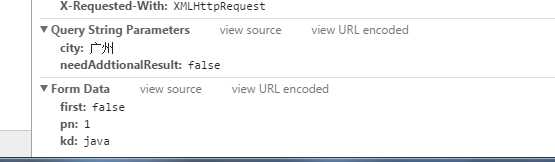
当我查看ajax请求的时候,发现事情又不简单的了,这个分页的请求带的参数时Form data,也就是表单形式的参数,
所以,拉勾网上的ajax请求不是get请求,不能再url里面直接带参数了,而是post请求
所以用ajax的请求方式也是不能顺利的抓取的,至少对于我这个新手来说
所以我决定采取Selenium动态渲染的方式进行抓取
确定基本的抓取方式之后我们就可以开始工作啦!
首先导入必备的包
from time import sleep from pyquery import PyQuery as pq from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver import ActionChains from selenium.common.exceptions import TimeoutException
创建一个lagou.py文件,声明一个LagouSpider类,并且定义它的init方法
class LagouSpider(object): def __init__(self): self.url = ‘https://www.lagou.com/‘ self.browser = webdriver.Chrome() self.browser.set_window_size(1920, 1080) self.wait = WebDriverWait(self.browser,20) self.list=[]
定义搜索的方法
def search(self): try: self.browser.get(self.url) actions = ActionChains(self.browser) actions.click() actions.perform() input = WebDriverWait(self.browser, 10).until( EC.presence_of_element_located((By.ID,‘search_input‘)) ) submit = WebDriverWait(self.browser,10).until( EC.element_to_be_clickable((By.ID,‘search_button‘)) ) sleep(2) input.send_keys(‘JAVA‘) sleep(2) submit.click() except TimeoutException: return self.search()
定义获取下一页的方法
def next_page(self): try: next = WebDriverWait(self.browser,10).until( EC.element_to_be_clickable((By.CLASS_NAME,‘pager_next ‘)) ) next.click() except TimeoutException: self.next_page()
获取我要爬取的数据,包括职位,工资,职位的需求
#获取数据以及对数据进行清洗 def get_salary(self): html = self.browser.page_source doc = pq(html) items = doc(‘.list_item_top‘).items() for item in items: java_dict={ ‘position‘:item.find(‘.p_top .position_link h3‘).text(), ‘salary‘:item.find(‘.p_bot .li_b_l‘).text().split(‘ ‘,1)[0], ‘qualification‘:item.find(‘.p_bot .li_b_l‘).text().split(‘ ‘,1)[1] } print(java_dict) self.list.append(java_dict) self.save_data(java_dict) print(len(self.list)) sleep(2) self.next_page()
最后创建一个config.py,MONGODB的配置
MONGO_URL =‘localhost‘ MONGO_DB = ‘lagou‘ MONGO_COLLECTION=‘java‘
在lagou.py文件中写上
from config import * import pymongo client = pymongo.MongoClient(MONGO_URL) db = client[MONGO_DB]
在LagouSpider中,保存到MONGODB数据库中
#保存到MONGDB中 def save_data(self,result): try: if db[MONGO_COLLECTION].insert(result): print(‘存储到MONGODB成功‘) except Exception: print(‘存储到MONGODB失败‘)
创建统筹调用的方法
def main(self): self.search() for i in range(1,31): self.get_salary()
最后开始爬取啦
LagouSpider().main()
查看MONGODB数据库
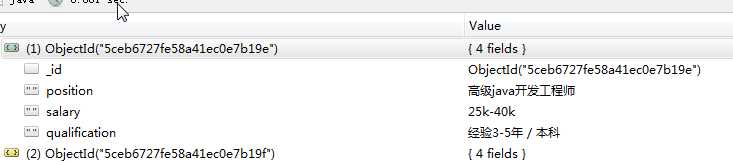
已经成功爬取啦
以上是关于使用selenium动态渲染爬取拉勾网上450个java职位的信息的主要内容,如果未能解决你的问题,请参考以下文章