大数据学习之sqoop框架 25
Posted hidamowang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习之sqoop框架 25相关的知识,希望对你有一定的参考价值。
1:Sqoop概述
1)官网
2)场景
传统型缺点,分布式存储。把传统型数据库数据迁移。
Apache Sqoop(TM)是一种用于在Apache Hadoop和结构化数据存储(如关系数据库)之间高效传输批量数据的工具 。
2:Sqoop安装部署
1)下载安装包
2)解压
tar -zxvf .tar
3)修改配置
vi sqoop-env.sh
export HADOOP_COMMON_HOME=/root/training/hadoop-2.8.4
export HADOOP_MAPRED_HOME=/root/training/hadoop-2.8.4
export HIVE_HOME=/root/training/hive
export ZOOCFGDIR=/root/training/zookeeper-3.4.10/conf
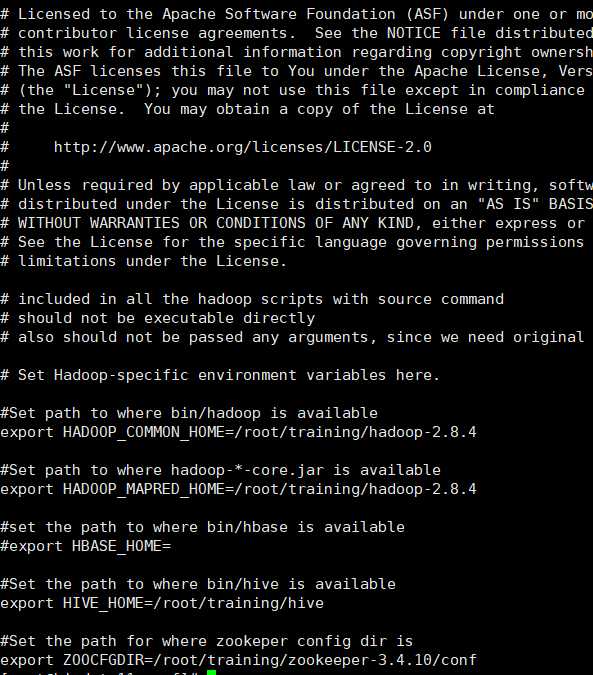
4)发送mysql驱动到lib下
5)检测是否安装成功
bin/sqoop help
3:Sqoop的import命令
1)数据从mysql中导入到hdfs当中
bin/sqoop import --connect jdbc:mysql://bigdata11:3306/sq --username root --password 199902 --table user --target-dir /sqoop/datas --delete-target-dir --num-mappers 1 --fields-terminated-by "\\t"
2)数据mysql中导入到hdfs当中进行筛选
bin/sqoop import --connect jdbc:mysql://bigdata11:3306/sq --username root --password 199902 --target-dir /sqoop/selectdemo --delete-target-dir --num-mappers 1 --fields-terminated-by "\\t" --query ‘select * from user where id<=1 and $CONDITIONS‘
3)通过where筛选
bin/sqoop import --connect jdbc:mysql://bigdata11:3306/sq --username root --password 199902 --target-dir /sqoop/selectdemo2 --delete-target-dir --num-mappers 1 --fields-terminated-by "\\t" --table user --where "id<=1"
4)mysql导入到hive
需要先创建hive表
bin/sqoop import --connect jdbc:mysql://training09-01:3306/sq --username root -
-password 199902 --table user1 --num-mappers 1 --hive-import --fields-terminated-by "\\t" --hive-overwrite --hive-table user_sqoop
问题:hiveconf
解决:
vi ~/.bash_profile(记得在export PATH之前)
export HADOOP_CLASSPATH=$HADOOP_CLASSPASS:/root/training/hive/lib/*
5)常见bug
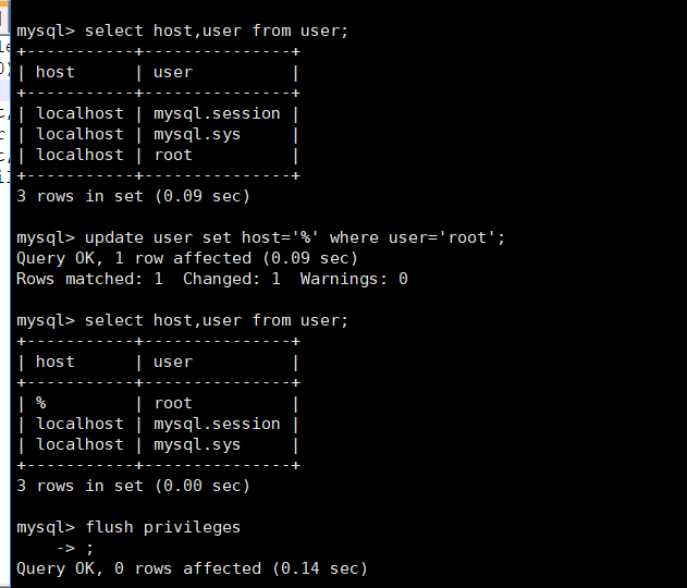
mysql权限问题:
###grant all privileges on *.* to [email protected]‘%‘ identified by "password";############
我用这个报错。可以用下面的方法
首先进入MySQL 使用mysql数据库
use mysql;
在这个库中修改user表
update user set host=‘%‘ where user=‘root‘
再刷新一下
flush privileges;
4:Sqoop的export命令
需求:Hive/trainingfs的数据导出到mysql
1)根据hive中的字段创建mysql表
2)编写sqoop启动命令
bin/sqoop export --connect jdbc:mysql://bigdata11:3306/sq --username root -
-password 199902 --table user1 --num-mappers 1 --export-dir /user/hive/ware
house/user_sqoop --input-fields-terminated-by "\\t"
3)mysq中查看数据是否导入
5:Sqoop打包脚本的使用
1)创建文件夹
mkdir sqoopjob
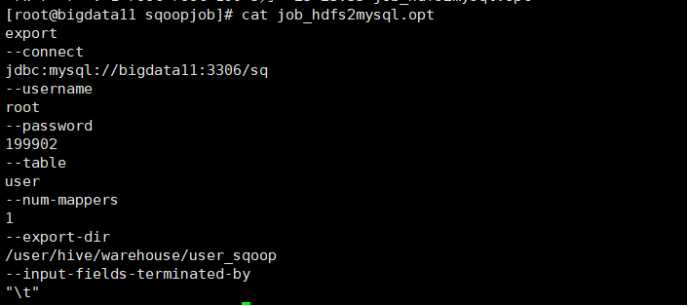
2)创建文件脚本 vi job_hdfs2mysql.opt
export
--connect
jdbc:mysql://bigdata11:3306/sq
--username
root
--password
199902
--table
user1
--num-mappers
1
--export-dir
/user/hive/warehouse/user_sqoop
--input-fields-terminated-by
"\\t"
注意:一行命令 一行值
3)执行脚本文件
bin/sqoop --options-file /root/sqoopjob/job_hdfs2mysql.opt
6:sqoop常用命令
|
命令 |
说明 |
|
import |
将数据导入到集群 |
|
export |
将集群数据导出 |
|
codegen |
将某数据库中表生成javaBean并打包为jar |
|
eval |
查看sql执行结果 |
|
createhivetable |
创建hive表 |
|
importalltables |
导入某个数据库中所有表到trainingfs中 |
|
listtables |
列出某个数据库下的所有表 |
|
merge |
将trainingfs中不同目录下的数据合并在一起 |
|
查看sqoop版本 |
versionV |
|
help |
查看帮助信息 |
7:sqoop常用参数
|
参数 |
说明 |
|
–connect |
连接关系型数据库URL |
|
–connectionmanager |
指定连接管理类 |
|
–driver |
JDBC的driver class |
|
–username |
连接数据库的用户名 |
|
–password |
连接数据库的密码 |
|
–verbose |
在控制台中打印详细信息 |
|
–help |
查看帮助 |
|
–hiveimport |
将关系型数据库导入到hive表中 |
|
–hiveoverwrite |
覆盖掉hive表中已存在的数据 |
|
–createhivetable |
创建hive表 |
|
–hivetable |
接入hive表 |
|
–table |
指定关系型数据库的表名 |
以上是关于大数据学习之sqoop框架 25的主要内容,如果未能解决你的问题,请参考以下文章