支持向量机 : 线性可分类 svm
Posted massquantity
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了支持向量机 : 线性可分类 svm相关的知识,希望对你有一定的参考价值。
支持向量机(support vector machine, 以下简称 svm)是机器学习里的重要方法,特别适用于中小型样本、非线性、高维的分类和回归问题。本系列力图展现 svm 的核心思想和完整推导过程,以飨读者。
一、原理概述
机器学习的一大任务就是分类(Classification)。如下图所示,假设一个二分类问题,给定一个数据集,里面所有的数据都事先被标记为两类,能很容易找到一个超平面(hyperplane)将其完美分类。
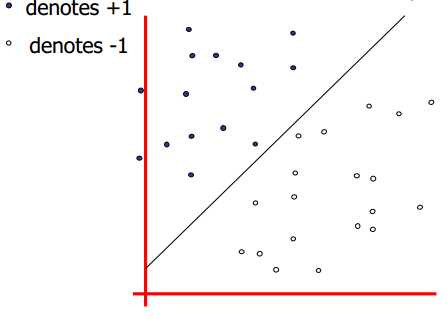
然而实际上可以找到无数个超平面将这两类分开,那么哪一个超平面是效果最好的呢?
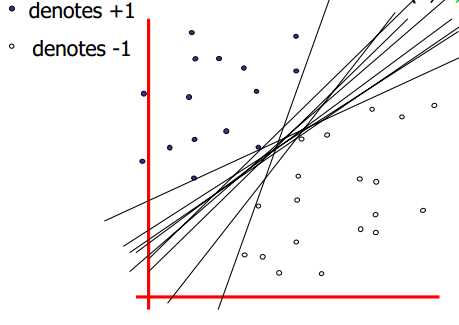
要回答这个问题,首先就要定义什么叫做“效果好”?在面临机器学习问题的时候普遍不是很关心训练数据的分类正确与否,而是关心一个新数据出现时其能否被模型正确分类。如果新数据被分类的准确率高,可以认为是“效果好”,或者说有较好的泛化能力。因此这里的问题就转化为:上图中哪一个超平面对新数据的分类准确率最高?
然而令人沮丧的是,没人能确切地回答哪个超平面最好,因为没人能把真实世界中的所有数据都拿过来测试。从广义上来说,大部分的理论研究都是对真实情况的模拟,譬如我们用人均收入来衡量一个国家的人民生活水平,这里的人均收入甚至只是一个不太接近的近似,因为不可能把每个国家中所有人的收入都拿出来一一比较。我们的大脑善于把繁琐的细节组合起来并高度抽象化,形成模型和假设,来逼近真实情况。
所以,在这个问题上我们能做的,也只有提出假设,建立模型,验证假设。而在 svm 中,这个假设就是:拥有最大“间隔”的超平面效果最好。
间隔(margin)指的是所有数据点中到这个超平面的最小距离。如下图所示,实线为超平面,虚线为间隔边界,黑色箭头为间隔,即虚线上的点到超平面的距离。可以看出,虚线上的三个点(2蓝1红)到超平面的距离都是一样的,实际上只有这三个点共同决定了超平面的位置,因而它们被称为“支持向量(support vectors)”,而“支持向量机”也由此而得名。
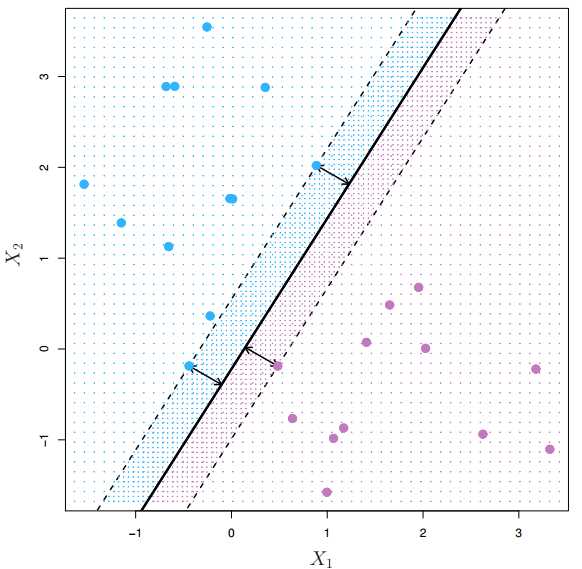
于是我们来到了svm的核心思想 —— 寻找一个超平面,使其到数据点的间隔最大。原因主要是这样的超平面分类结果较为稳健(robust),对于最难分的数据点(即离超平面最近的点)也能有足够大的确信度将它们分开,因而泛化到新数据点效果较好。
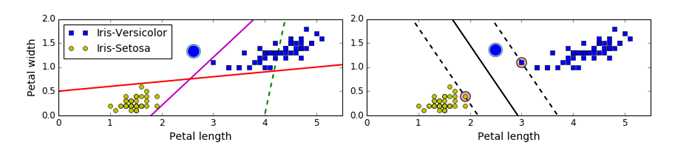
比如上左图的红线和紫线虽然能将两类数据完美分类,但注意到这两个超平面本身非常靠近数据点。以紫线为例,圆点为测试数据,其正确分类为蓝色,但因为超平面到数据点的间隔太近,以至于被错分成了黄色。 而上右图中因为间隔较大,圆点即使比所有蓝点更靠近超平面,最终也能被正确分类。
二、间隔最大化与优化问题(线性可分类svm)
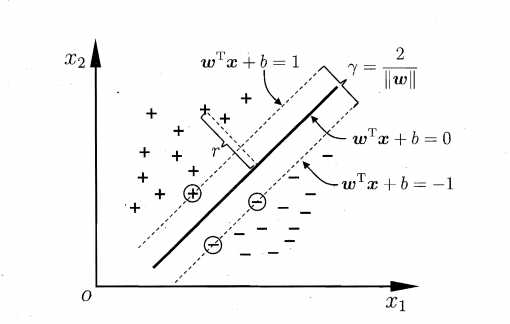
给定一组数据 \\(\\left\\{\\left(\\boldsymbol{x}_{1}, y_{1}\\right),\\left(\\boldsymbol{x}_{2}, y_{2}\\right), \\ldots,\\left(\\boldsymbol{x}_{m}, y_{m}\\right)\\right\\}\\), 其中 \\(\\boldsymbol{x}_i \\in \\mathbb{R}^d\\), \\(y_i \\in \\{-1, +1\\}\\) 。如果两类样本线性可分,即存在一个超平面 \\(\\boldsymbol{w}^{\\top} \\boldsymbol{x}+b = 0\\) 将两类样本分隔开,这样可以得到:
\\[
y_{i} \\operatorname{sign}\\left(\\boldsymbol{w}^{\\top} \\boldsymbol{x}_{i}+b\\right)=1 \\iff y_{i}\\left(\\boldsymbol{w}^{\\top} \\boldsymbol{x}_{i}+b\\right)>0 \\tag{1.1}
\\]
对于任意的 \\(\\zeta > 0\\) ,\\((1.1)\\) 式等价于 \\(y_{i}\\left(\\zeta\\, \\boldsymbol{w}^{\\top} \\boldsymbol{x}_{i}+\\zeta\\, b\\right)>0\\) ,则说明 \\((\\boldsymbol{w}, b)\\) 具有放缩不变性,为了后面优化方便,令 \\(\\min |\\boldsymbol{w^\\top x} + b| = 1\\) ,即:
\\[
\\begin{cases}
\\boldsymbol{w}^{\\top}\\boldsymbol{x}_i + b \\geqslant +1, \\quad \\text{if} \\;\\; {y}_i = +1 \\\\boldsymbol{w}^{\\top}\\boldsymbol{x}_i + b \\leqslant -1, \\quad \\text{if} \\;\\;y_i = -1 \\\\end{cases}
\\]
这样 \\((1.1)\\) 式就转化为
\\[
y_{i}\\left(\\boldsymbol{w}^{\\top} \\boldsymbol{x}_{i}+b\\right) \\geq 1 \\tag{1.2}
\\]
上一节提到我们希望间隔最大化,那么间隔该如何表示? 样本空间任意点 \\(\\boldsymbol{x}\\) 到超平面的距离为 \\(dist = \\frac{|\\boldsymbol{w}^\\top\\boldsymbol{x} + b|}{||\\boldsymbol{w}||}\\) (证明见附录),间隔为距离超平面 \\(\\boldsymbol{w}^{\\top} \\boldsymbol{x}+b = 0\\) 最近的样本到超平面距离的两倍,即:
\\[
\\gamma = 2 \\min \\frac{|\\boldsymbol{w}^\\top\\boldsymbol{x} + b|}{||\\boldsymbol{w}||} = \\frac{2}{||\\boldsymbol{w}||}
\\]
这样线性 svm 的优化目标即为:
\\[
\\begin{aligned}
{\\max_{\\boldsymbol{w}, b}} & \\;\\;\\frac{2}{||\\boldsymbol{w}||} \\implies \\min\\limits_{\\boldsymbol{w}, b}\\frac12 ||\\boldsymbol{w}||^2 \\\\[1ex]
{\\text { s.t. }} & \\;\\;y_{i}\\left(\\boldsymbol{w}^{\\top} \\boldsymbol{x}_{i}+b\\right) \\geq 1 , \\quad i=1,2, \\ldots, m
\\end{aligned} \\tag{1.3}
\\]
这是一个凸二次规划(convex quadratic programming)问题,可以用现成的软件包计算。该问题有 \\(d + 1\\) 个变量 (\\(d\\) 为 \\(\\boldsymbol{x}_i\\) 的维度) 和 \\(m\\) 个约束,如果 \\(d\\) 很大,则求解困难。所以现实中一般采用对偶算法(dual algorithm),通过求解原始问题(primal problem)的对偶问题(dual problem),来获得原始问题的最优解。这样做的优点,一是对偶问题往往更容易求解,二是能自然地引入核函数,进而高效地解决高维非线性分类问题。
三、拉格朗日对偶性
原始的优化问题 \\((1.3)\\) 式与对偶问题的转换关系如下,里面的一些具体原理可参阅前文 (拉格朗日乘子法 - KKT条件 - 对偶问题) :
\\[
不等式约束优化问题 \\;\\;\\overset{\\normalsize 拉格朗日乘子法}{\\iff} \\;\\; 无约束优化问题\\;\\; \\overset{对偶性}{\\iff} \\;\\;对偶问题
\\]
由拉格朗日乘子法,注意这里有 \\(m\\) 个样本,于是为每条约束引入拉格朗日乘子 \\(\\alpha_i \\geqslant 0\\) ,\\((1.3)\\) 式的拉格朗日函数为:
\\[
\\mathcal{L}(\\boldsymbol{w}, b, \\boldsymbol{\\alpha}) =\\frac{1}{2} ||\\boldsymbol{w}||^2+\\sum_{i=1}^{m} \\alpha_{i}\\left(1-y_{i}\\left(\\boldsymbol{w}^{\\top} \\boldsymbol{x}_{i}+b\\right)\\right) \\tag{2.1}
\\]
其相应的对偶问题为:
\\[
\\begin{align*}
\\max _{\\boldsymbol{\\alpha}}\\min _{\\boldsymbol{w}, b} & \\;\\; \\frac{1}{2} ||\\boldsymbol{w}||^2+\\sum_{i=1}^{m} \\alpha_{i}\\left(1-y_{i}\\left(\\boldsymbol{w}^{\\top} \\boldsymbol{x}_{i}+b\\right)\\right) \\\\text{s.t.} & \\;\\; \\alpha_i \\geqslant 0, \\quad i=1,2, \\ldots, m
\\end{align*} \\tag{2.2}
\\]
上式内层对 \\((\\boldsymbol{w}, b)\\) 的优化属于无约束优化问题,则令偏导等于零:
\\[
\\begin{align*}
\\frac{\\partial \\mathcal{L}}{\\partial \\boldsymbol{w}}=\\mathbf{0} & \\implies \\boldsymbol{w}=\\sum_{i=1}^{m} \\alpha_{i} y_{i} \\boldsymbol{x}_{i} \\\\
\\frac{\\partial \\mathcal{L}}{\\partial b}=0 & \\implies \\sum_{i=1}^{m} \\alpha_{i} y_{i}=0 \\\\end{align*}
\\]
代入 \\((2.2)\\) 式得:
\\[
\\begin{align*}
\\max_{\\boldsymbol{\\alpha}} \\quad& \\sum\\limits_{i=1}^m \\alpha_i - \\frac12 \\sum\\limits_{i=1}^m\\sum\\limits_{j=1}^m\\alpha_i\\alpha_j y_i y_j \\boldsymbol{x}_i \\boldsymbol{x}_j \\\\[1ex]
\\text{s.t.} \\quad & \\alpha_i \\geqslant 0, \\quad i=1,2, \\ldots, m \\\\[1ex]
& \\sum\\limits_{i=1}^m \\alpha_i y_i = 0
\\end{align*} \\tag{2.3}
\\]
此依然属于二次规划问题,求出 \\(\\boldsymbol{\\alpha}\\) 后,即可得原始问题的参数 \\((\\boldsymbol{w}, b)\\) 。该二次规划问题有 \\(m\\) 个变量, \\((m + 1)\\)项约束,因而适用于 \\(d\\) 很大,\\(m\\) 适中 ( \\(d >> m\\) ) 的情况。而当 \\(m\\) 很大时,问题变得不可解,这时候可使用 SMO 这类专为 svm 设计的优化算法,后文详述。 另外上文也提到 \\((1.3)\\) 式的原始二次规划问题适用于 \\(d\\) 比较小的低维数据,所以 scikit-learn 中的 LinearSVC 有 dual : bool, (default=True) 这个选项,当样本数 > 特征数时,宜设为 False,选择解原始优化问题,可见使用 svm 并不是非要转化为对偶问题不可 。而相比之下 SVC 则没有 dual 这个选项,因为 SVC 中实现了核函数,必须先转化为对偶问题,后文再议。
前文已证明 \\((2.2)\\) 式的最优解应满足 KKT 条件,由 KKT 条件中的互补松弛条件可知 \\(\\alpha_i (1 - y_i (\\boldsymbol{w}^\\top \\boldsymbol{x}_i + b)) = 0\\) 。当 \\(\\alpha_i > 0\\) 时, \\(y_i(\\boldsymbol{w}^\\top\\boldsymbol{x}_i + b) = 1\\) ,说明这些样本点 \\((\\boldsymbol{x}_i, y_i)\\) 一定在间隔边界上,它们被称为“支持向量”,这些点共同决定了分离超平面。这是 svm 的一个重要特性: 训练完成后,大部分训练样本不需要保留,最终模型仅与支持向量有关。
于是可根据支持向量求 \\(\\boldsymbol{w}\\):
\\[
\\begin{align*}
\\boldsymbol{w} &=\\sum_{i=1}^{m} \\alpha_{i} y_{i} \\boldsymbol{x}_{i} \\\\
&=\\sum_{i:\\,\\alpha_i=0}^{m} 0 \\cdot y_{i} \\boldsymbol{x}_{i}+\\sum_{i : \\,\\alpha_{i}>0}^{m} \\alpha_{i} y_{i} \\boldsymbol{x}_{i} \\\\
&=\\sum_{i \\in S V} \\alpha_{i} y_{i} \\boldsymbol{x}_{i}
\\end{align*} \\tag{2.5}
\\]
其中 \\(SV\\) 代表所有支持向量的集合。对于任意支持向量 \\((\\boldsymbol{x}_s, y_s)\\),都有 \\(y_s(\\boldsymbol{w}^\\top \\boldsymbol{x}_s + b) = 1\\) 。将 \\((2.5)\\) 式代入,并利用 \\(y_s^2 = 1\\) :
\\[
y_s(\\sum\\limits_{i \\in {SV}} \\alpha_i y_i \\boldsymbol{x}_i^\\top\\boldsymbol{x}_s + b) = y_s^2 \\quad \\implies b = y_s - \\sum\\limits_{i \\in SV} \\alpha_i y_i \\boldsymbol{x}_i^\\top\\boldsymbol{x}_s
\\]
实践中,为了得到对 \\(b\\) 更稳健的估计,通常对所有支持向量求解得到 \\(b\\) 的平均值:
\\[
b = \\frac{1}{|SV|} \\sum\\limits_{s \\in SV} \\left( y_s - \\sum\\limits_{i \\in SV} \\alpha_i y_i \\boldsymbol{x}_i^\\top\\boldsymbol{x}_s \\right)
\\]
于是线性 svm 的假设函数可表示为:
\\[
f(\\boldsymbol{x}) = \\text{sign} \\left(\\sum\\limits_{i \\in SV} \\alpha_i y_i \\boldsymbol{x}_i^\\top \\boldsymbol{x} + b \\right)
\\]
附录: 点到超平面的距离
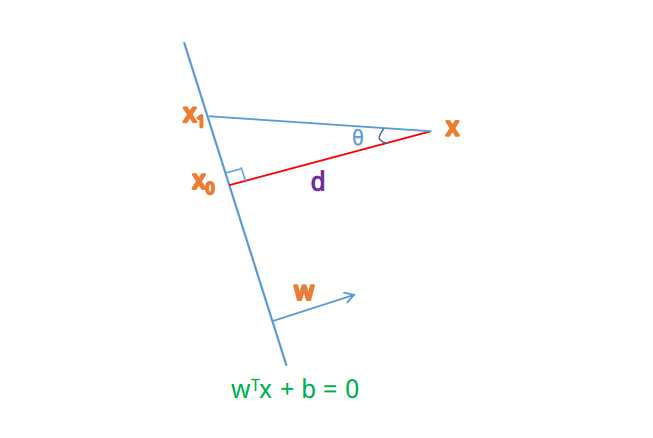
如上图所示,想要求 \\(\\boldsymbol{x}\\) 到超平面 \\(\\boldsymbol{w}^\\top\\boldsymbol{x} + b = 0\\) 的距离 \\(d\\) 。设 \\(\\boldsymbol{x}_0\\) 和 \\(\\boldsymbol{x}_1\\) 是超平面上的两个点,则:
\\[
\\begin{cases}
\\boldsymbol{w}^{\\top}\\boldsymbol{x}_0 + b = 0 \\\\[0.5ex]
\\boldsymbol{w}^{\\top}\\boldsymbol{x}_1 + b = 0
\\end{cases}
\\quad \\implies \\quad \\boldsymbol{w}^\\top (\\boldsymbol{x}_0 - \\boldsymbol{x}_1) = 0
\\]
即 \\(\\boldsymbol{w}?\\) 垂直于超平面。
证明1:
\\[
d = ||\\boldsymbol{x} - \\boldsymbol{x}_1|| \\cos \\theta = ||\\boldsymbol{x} - \\boldsymbol{x}_1|| \\frac{|\\boldsymbol{w}^\\top(\\boldsymbol{x} - \\boldsymbol{x}_1)|}{||\\boldsymbol{w}||\\cdot||\\boldsymbol{x} - \\boldsymbol{x}_1||} = \\frac{|\\boldsymbol{w}^\\top\\boldsymbol{x} - \\boldsymbol{w}^\\top \\boldsymbol{x}_1|}{||\\boldsymbol{w}||} = \\frac{|\\boldsymbol{w}^\\top\\boldsymbol{x} + b|}{||\\boldsymbol{w}||}
\\]
证明2: 由于 \\(\\frac{\\boldsymbol{w}}{||\\boldsymbol{w}||}\\) 为单位向量:
\\[
\\boldsymbol{w}^\\top\\boldsymbol{x}_0 + b = \\boldsymbol{w}^\\top \\left(\\boldsymbol{x} - d\\cdot \\frac{\\boldsymbol{w}} {||\\boldsymbol{w}||} \\right) + b = 0 \\quad \\implies \\quad d = \\frac{|\\boldsymbol{w}^\\top\\boldsymbol{x} + b|}{||\\boldsymbol{w}||}
\\]
/
以上是关于支持向量机 : 线性可分类 svm的主要内容,如果未能解决你的问题,请参考以下文章