rcnn 文本分类代码
Posted datascience1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了rcnn 文本分类代码相关的知识,希望对你有一定的参考价值。
import tensorflow as tf
class TextRCNN:
def __init__(self, sequence_length, num_classes, vocab_size, word_embedding_size, context_embedding_size,
cell_type, hidden_size, l2_reg_lambda=0.0):
# Placeholders for input, output and dropout
self.input_text = tf.placeholder(tf.int32, shape=[None, sequence_length], name=‘input_text‘)
self.input_y = tf.placeholder(tf.float32, shape=[None, num_classes], name=‘input_y‘)
self.dropout_keep_prob = tf.placeholder(tf.float32, name=‘dropout_keep_prob‘)
l2_loss = tf.constant(0.0)
text_length = self._length(self.input_text)
# Embeddings
with tf.device(‘/cpu:0‘), tf.name_scope("embedding"):
self.W_text = tf.Variable(tf.random_uniform([vocab_size, word_embedding_size], -1.0, 1.0), name="W_text")
self.embedded_chars = tf.nn.embedding_lookup(self.W_text, self.input_text)
# Bidirectional(Left&Right) Recurrent Structure
with tf.name_scope("bi-rnn"):
fw_cell = self._get_cell(context_embedding_size, cell_type)
fw_cell = tf.nn.rnn_cell.DropoutWrapper(fw_cell, output_keep_prob=self.dropout_keep_prob)
bw_cell = self._get_cell(context_embedding_size, cell_type)
bw_cell = tf.nn.rnn_cell.DropoutWrapper(bw_cell, output_keep_prob=self.dropout_keep_prob)
(self.output_fw, self.output_bw), states = tf.nn.bidirectional_dynamic_rnn(cell_fw=fw_cell,
cell_bw=bw_cell,
inputs=self.embedded_chars,
sequence_length=text_length,
dtype=tf.float32)
with tf.name_scope("context"):
shape = [tf.shape(self.output_fw)[0], 1, tf.shape(self.output_fw)[2]]
self.c_left = tf.concat([tf.zeros(shape), self.output_fw[:, :-1]], axis=1, name="context_left")
self.c_right = tf.concat([self.output_bw[:, 1:], tf.zeros(shape)], axis=1, name="context_right")
with tf.name_scope("word-representation"):
self.x = tf.concat([self.c_left, self.embedded_chars, self.c_right], axis=2, name="x")
embedding_size = 2*context_embedding_size + word_embedding_size
with tf.name_scope("text-representation"):
W2 = tf.Variable(tf.random_uniform([embedding_size, hidden_size], -1.0, 1.0), name="W2")
b2 = tf.Variable(tf.constant(0.1, shape=[hidden_size]), name="b2")
self.y2 = tf.tanh(tf.einsum(‘aij,jk->aik‘, self.x, W2) + b2)
with tf.name_scope("max-pooling"):
self.y3 = tf.reduce_max(self.y2, axis=1)
with tf.name_scope("output"):
W4 = tf.get_variable("W4", shape=[hidden_size, num_classes], initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b4")
l2_loss += tf.nn.l2_loss(W4)
l2_loss += tf.nn.l2_loss(b4)
self.logits = tf.nn.xw_plus_b(self.y3, W4, b4, name="logits")
self.predictions = tf.argmax(self.logits, 1, name="predictions")
# Calculate mean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
# Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, axis=1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, tf.float32), name="accuracy")
@staticmethod
def _get_cell(hidden_size, cell_type):
if cell_type == "vanilla":
return tf.nn.rnn_cell.BasicRNNCell(hidden_size)
elif cell_type == "lstm":
return tf.nn.rnn_cell.BasicLSTMCell(hidden_size)
elif cell_type == "gru":
return tf.nn.rnn_cell.GRUCell(hidden_size)
else:
print("ERROR: ‘" + cell_type + "‘ is a wrong cell type !!!")
return None
# Length of the sequence data
@staticmethod
def _length(seq):
relevant = tf.sign(tf.abs(seq))
length = tf.reduce_sum(relevant, reduction_indices=1)
length = tf.cast(length, tf.int32)
return length
# Extract the output of last cell of each sequence
# Ex) The movie is good -> length = 4
# output = [ [1.314, -3.32, ..., 0.98]
# [0.287, -0.50, ..., 1.55]
# [2.194, -2.12, ..., 0.63]
# [1.938, -1.88, ..., 1.31]
# [ 0.0, 0.0, ..., 0.0]
# ...
# [ 0.0, 0.0, ..., 0.0] ]
# The output we need is 4th output of cell, so extract it.
@staticmethod
def last_relevant(seq, length):
batch_size = tf.shape(seq)[0]
max_length = int(seq.get_shape()[1])
input_size = int(seq.get_shape()[2])
index = tf.range(0, batch_size) * max_length + (length - 1)
flat = tf.reshape(seq, [-1, input_size])
return tf.gather(flat, index)
以上代码从https://github.com/roomylee/rcnn-text-classification/blob/master/rcnn.py 拷贝过来的。
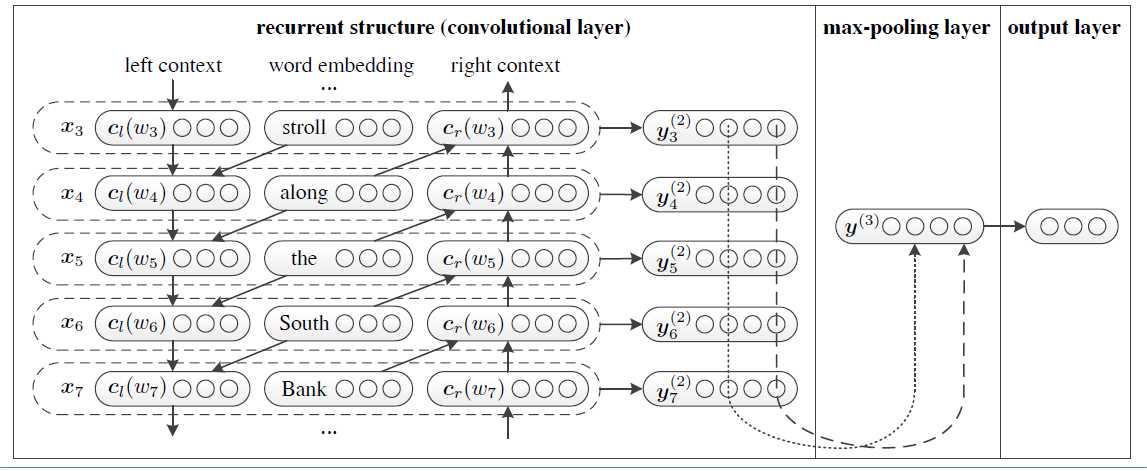
rcnn的模型来源于论文Recurrent Convolutional Neural Networks for Text Classification,模型如下图:
以上是关于rcnn 文本分类代码的主要内容,如果未能解决你的问题,请参考以下文章