二.requests库的运用
1.爬虫的基本框架是获取HTML页面信息,解析页面信息,保存结果,requests模块是用于第一步获取HTML页面信息; requests库用于爬取HTML页面,提交网络请求,基于urllib,但比urllib更方便。
2.安装requests库
打开命令行,输入
pip install requests
即可安装
3.下面介绍一些requests库的基本用法
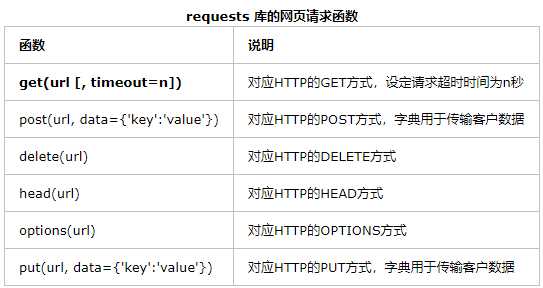
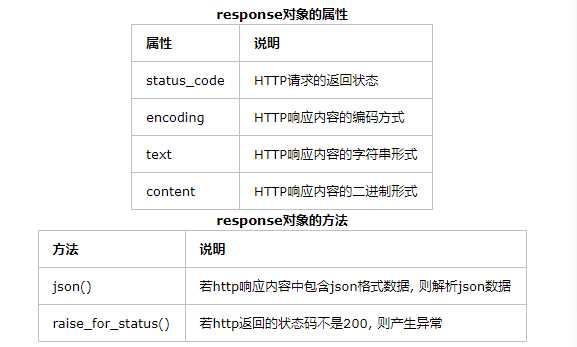
get方法,它能够获得url的请求,并返回一个response对象作为响应。
常见的HTTP状态码:200 - 请求成功,301 - 资源(网页等)被永久转移到其它URL,404 - 请求的资源(网页等)不存在,500 - 内部服务器错误。