Hive 学习 Hive的数据类型
Posted tashanzhishi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive 学习 Hive的数据类型相关的知识,希望对你有一定的参考价值。
正文
一, 数字类型
如下表所示:
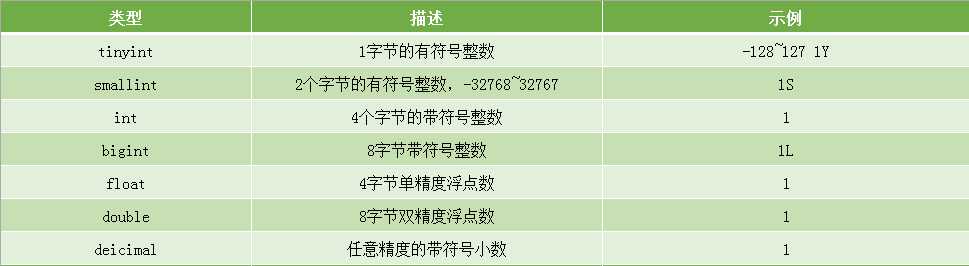
实例:
create table t_test(a string ,b int,c bigint,d float,e double,f tinyint,g smallint)
二,日期时间类型

示例:有如下数据:
1,zhangsan,1985-06-30 2,lisi,1986-07-10 3,wangwu,1985-08-09
建表:
那么,就可以建一个表来对数据进行映射 create table t_customer(id int,name string,birthday date) row format delimited fields terminated by ‘,‘; 然后导入数据 load data local inpath ‘/root/customer.dat‘ into table t_customer; 然后,就可以正确查询
三,字符串类型
对于字符串类型,是比较常见的,在Hive中常用的就是String,主要原因是Java的数据类型。

四,混杂类型

五,复合类型
有一些数据有一些特点的结构,而hive比起常见的关系型数据库多了几个非常方便的数据类型,如下:

5.1 array数据类型
array实例,有如下数据:
战狼2,吴京:吴刚:龙母,2017-08-16 三生三世十里桃花,刘亦菲:痒痒,2017-08-20 普罗米修斯,苍老师:小泽老师:波多老师,2017-09-17 美女与野兽,吴刚:加藤鹰,2017-09-17
分析:对于演员字段,如果是将其所有演员当做一个字符串来存储,在数据查询的时候就不是很方便,这时就可以利用hive的一个新的数据类型数组来进行建表如下:
-- 建表映射: create table t_movie(movie_name string,actors array<string>,first_show date) row format delimited fields terminated by ‘,‘ collection items terminated by ‘:‘; -- 导入数据 load data local inpath ‘/root/hivetest/actor.dat‘ into table t_movie; load data local inpath ‘/root/hivetest/actor.dat.2‘ into table t_movie;
查询:
select movie_name,actors[0],first_show from t_movie; # 通过下标取数据 +---------------------+------------------------+---------------------+--+ | t_movie.movie_name | t_movie.actors | t_movie.first_show | +---------------------+------------------------+---------------------+--+ | 战狼2 | "吴京" | 2017-08-16 | | 三生三世十里桃花 | "刘亦菲" | 2017-08-20 | | 普罗米修斯 | "苍老师" | 2017-09-17 | | 美女与野兽 | "吴刚" | 2017-09-17 | +---------------------+------------------------+---------------------+--+ 4 rows selected (0.141 seconds)
其他用法:
select movie_name,actors,first_show from t_movie where array_contains(actors,‘吴刚‘); # array_contains的使用 +-------------+-------------------+-------------+--+ | movie_name | actors | first_show | +-------------+-------------------+-------------+--+ | 战狼2 | ["吴京","吴刚","龙母"] | 2017-08-16 | | 美女与野兽 | ["吴刚","加藤鹰"] | 2017-09-17 | +-------------+-------------------+-------------+--+ 2 rows selected (0.128 seconds) select movie_name ,size(actors) as actor_number # size()的使用 ,first_show from t_movie; +-------------+---------------+-------------+--+ | movie_name | actor_number | first_show | +-------------+---------------+-------------+--+ | 战狼2 | 3 | 2017-08-16 | | 三生三世十里桃花 | 2 | 2017-08-20 | | 普罗米修斯 | 3 | 2017-09-17 | | 美女与野兽 | 2 | 2017-09-17 | +-------------+---------------+-------------+--+ 4 rows selected (0.152 seconds)
5.2 map类型
map实例,有如下数据:
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28 2,lisi,father:mayun#mother:huangyi#brother:guanyu,22 3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29 4,mayun,father:mayongzhen#mother:angelababy,26
分析:上述数据,中间的字段在java中我们可以用map的key-value形式:
-- 建表映射上述数据 create table t_family(id int,name string,family_members map<string,string>,age int) row format delimited fields terminated by ‘,‘ collection items terminated by ‘#‘ # 元素之间的分割符 map keys terminated by ‘:‘; # key-value之间的分隔符 -- 导入数据 load data local inpath ‘/root/hivetest/fm.dat‘ into table t_family;
查询练习:
select * from t_family; +--------------+----------------+----------------------------------------------------------------+---------------+--+ | t_family.id | t_family.name | t_family.family_members | t_family.age | +--------------+----------------+----------------------------------------------------------------+---------------+--+ | 1 | zhangsan | {"father":"xiaoming","mother":"xiaohuang","brother":"xiaoxu"} | 28 | | 2 | lisi | {"father":"mayun","mother":"huangyi","brother":"guanyu"} | 22 | | 3 | wangwu | {"father":"wangjianlin","mother":"ruhua","sister":"jingtian"} | 29 | | 4 | mayun | {"father":"mayongzhen","mother":"angelababy"} | 26 | +--------------+----------------+----------------------------------------------------------------+---------------+--+ -- 查出每个人的 爸爸、姐妹 select id,name,family_members["father"] as father,family_members["sister"] as sister,age from t_family; +-----+-----------+--------------+-----------+--+ | id | name | _c2 | _c3 | +-----+-----------+--------------+-----------+--+ | 1 | zhangsan | xiaoming | NULL | | 2 | lisi | mayun | NULL | | 3 | wangwu | wangjianlin | jingtian | | 4 | mayun | mayongzhen | NULL | +-----+-----------+--------------+-----------+--+ 4 rows selected (0.136 seconds) -- 查出每个人有哪些亲属关系 select id,name,map_keys(family_members) as relations,age from t_family; +-----+-----------+--------------------------------+------+--+ | id | name | relations | age | +-----+-----------+--------------------------------+------+--+ | 1 | zhangsan | ["father","mother","brother"] | 28 | | 2 | lisi | ["father","mother","brother"] | 22 | | 3 | wangwu | ["father","mother","sister"] | 29 | | 4 | mayun | ["father","mother"] | 26 | +-----+-----------+--------------------------------+------+--+ 4 rows selected (0.129 seconds) -- 查出每个人的亲人名字 select id,name,map_values(family_members) as relations,age from t_family; +-----+-----------+-------------------------------------+------+--+ | id | name | relations | age | +-----+-----------+-------------------------------------+------+--+ | 1 | zhangsan | ["xiaoming","xiaohuang","xiaoxu"] | 28 | | 2 | lisi | ["mayun","huangyi","guanyu"] | 22 | | 3 | wangwu | ["wangjianlin","ruhua","jingtian"] | 29 | | 4 | mayun | ["mayongzhen","angelababy"] | 26 | +-----+-----------+-------------------------------------+------+--+ 4 rows selected (0.132 seconds) -- 查出每个人的亲人数量 select id,name,size(family_members) as relations,age from t_family; +-----+-----------+------------+------+--+ | id | name | relations | age | +-----+-----------+------------+------+--+ | 1 | zhangsan | 3 | 28 | | 2 | lisi | 3 | 22 | | 3 | wangwu | 3 | 29 | | 4 | mayun | 2 | 26 | +-----+-----------+------------+------+--+ 4 rows selected (0.138 seconds) -- 查出所有拥有兄弟的人及他的兄弟是谁 -- 方案1:一句话写完 select id,name,age,family_members[‘brother‘] from t_family where array_contains(map_keys(family_members),‘brother‘); +-----+-----------+------+---------+--+ | id | name | age | _c3 | +-----+-----------+------+---------+--+ | 1 | zhangsan | 28 | xiaoxu | | 2 | lisi | 22 | guanyu | +-----+-----------+------+---------+--+ 2 rows selected (0.168 seconds) -- 方案2:子查询 select id,name,age,family_members[‘brother‘] from (select id,name,age,map_keys(family_members) as relations,family_members from t_family) tmp where array_contains(relations,‘brother‘); +-----+-----------+------+---------+--+ | id | name | age | _c3 | +-----+-----------+------+---------+--+ | 1 | zhangsan | 28 | xiaoxu | | 2 | lisi | 22 | guanyu | +-----+-----------+------+---------+--+ 2 rows selected (0.168 seconds)
5.3 struct类型
struct示例,有如下数据:
1,zhangsan,18:male:深圳 2,lisi,28:female:北京 3,wangwu,38:male:广州 4,赵六,26:female:上海 5,钱琪,35:male:杭州 6,王八,48:female:南京
分析:上述数据分为两部分,若用map和array都方便,我们可以吧第二部分看做是一个对象。
建表:
drop table if exists t_user; create table t_user(id int,name string,info struct<age:int,sex:string,addr:string>) row format delimited fields terminated by ‘,‘ collection items terminated by ‘:‘; -- 导入数据 load data local inpath ‘/root/hivetest/user.dat‘ into table t_user;
查询测试:
-- 查询每个人的id name和地址 select id,name,info.addr from t_user; +------------+--------------+----------------------------------------+--+ | t_user.id | t_user.name | t_user.info | +------------+--------------+----------------------------------------+--+ | 1 | zhangsan | {"age":18,"sex":"male","addr":"深圳"} | | 2 | lisi | {"age":28,"sex":"female","addr":"北京"} | | 3 | wangwu | {"age":38,"sex":"male","addr":"广州"} | | 4 | 赵六 | {"age":26,"sex":"female","addr":"上海"} | | 5 | 钱琪 | {"age":35,"sex":"male","addr":"杭州"} | | 6 | 王八 | {"age":48,"sex":"female","addr":"南京"} | +------------+--------------+----------------------------------------+--+ 6 rows selected (0.163 seconds)
以上是关于Hive 学习 Hive的数据类型的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(六十二)<Hive旅程第三站:Hive数据类型>