文本处理工具之grep和正则表达式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本处理工具之grep和正则表达式相关的知识,希望对你有一定的参考价值。
grep :是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep命令选项
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系 grep –e ‘cat ’ -e ‘dog’ file
-w 匹配整个单词
-E 使用ERE
-F 相当于fgrep,不支持正则表达式
-f file 根据模式文件处理
grep命令常见的用法
1.在文中搜索一个单词,命令会返回包含该单词的文本行:
grep "root" file_name
grep root file_name
2.多个文中查找:
gerp "root" file_name1 file_name2 file_name3
3.使用正则表达式:
grep -E "[1-9]+"
egrep "[1-9]"
4.使用多个字符搜索:
grep -e "cat" -e "guo" file_name
正则表达式
由一类特殊字符及文本字符所编写的模式, 其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能
程序支持:grep,sed,awk,vim, less,nginx,varnish等
分类:
基本正则表达式
扩展正则表达式: egrep
元字符分类:字符匹配,匹配次数,位置锚定,分组。
man帮助:man 7 regex 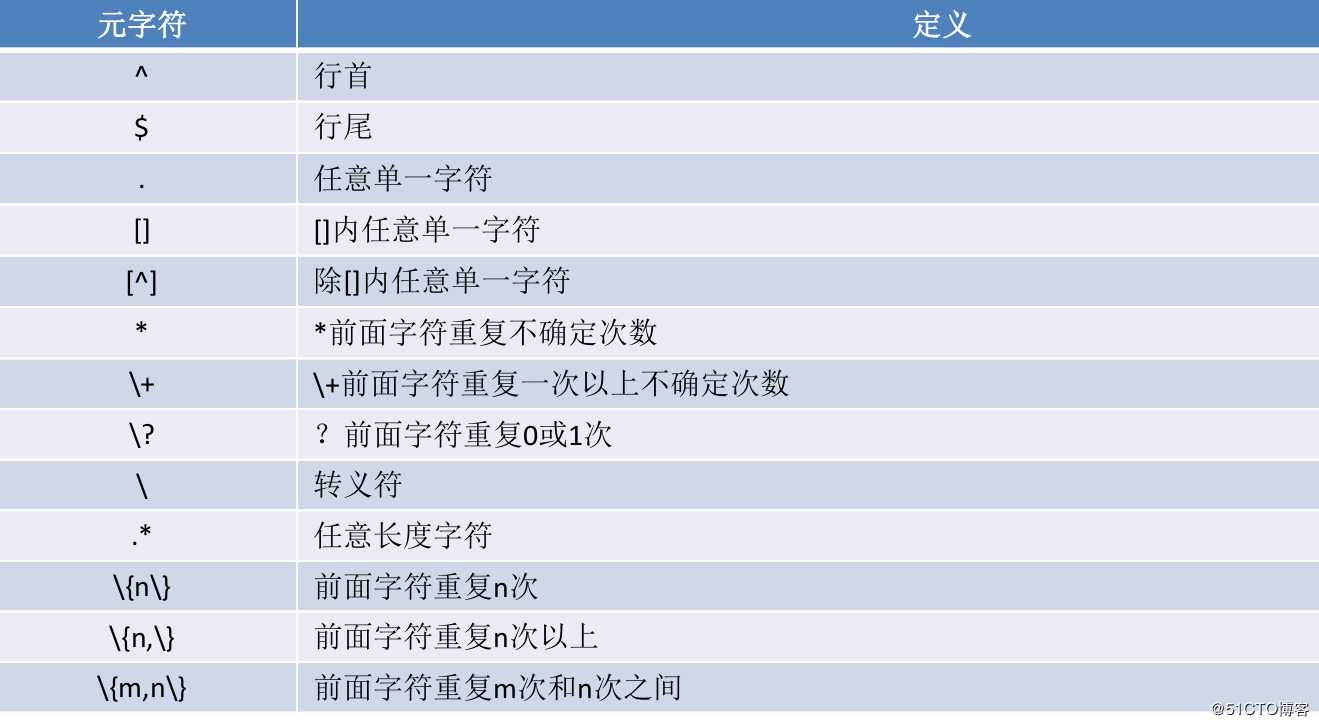

egrep及扩展的正则表达式
egrep = grep -E
1.字符匹配:
.任意单个字符
[]指定范围的字符
[^]不在指定范围的字符
2.次数匹配:
* 匹配前面字符任意次
?0次或1次
+ 1次或多次
{m} 匹配m次
{m,n} 至少m次,最多n次
3.位置锚定:
^ 行首
$ 行尾
\<,\b语首
\>,\b语尾
4.分组:
()
后向引用:\1, \2,.....
以上是关于文本处理工具之grep和正则表达式的主要内容,如果未能解决你的问题,请参考以下文章