PostgreSQL 缓存
Posted linguoguo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PostgreSQL 缓存相关的知识,希望对你有一定的参考价值。
PostgreSQL physical storage 和 inter db 值得阅读
数据在物理介质上存储是以page的形式,大小为8K,如下:
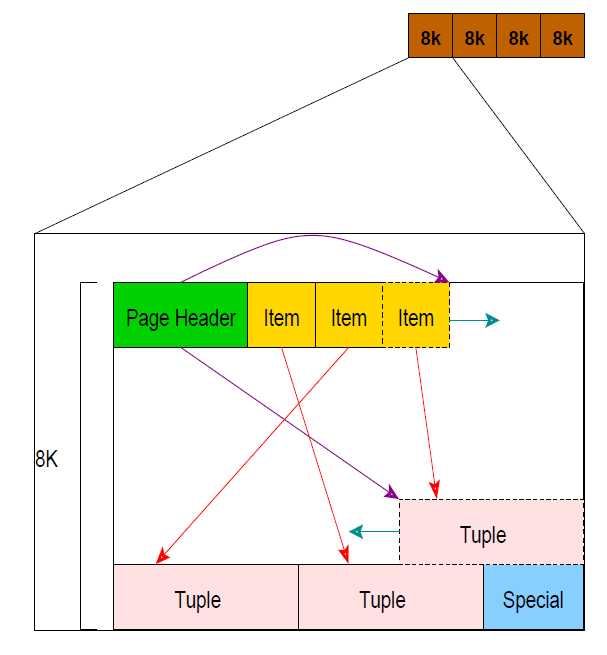
- a
tuple或anitem是行的同义词 - a
relation是表的同义词 - a
filenode是表示对表或索引的引用的id。 - a
block和page是等于它们代表存储表的文件的8kb段信息。
PostgreSQL会把table数据和index以page的形式存储在缓存中,同时在某些情况下(使用 prepared)也会把查询计划缓存下来,但是不会去缓存具体的查询结果。它是把查询到的数据页缓存起来,这个页会包含连续的数据,即不仅仅是你所要的查询的数据。
缓存指的是共享缓存,shared_buffers,所代表的内存区域可以看成是一个以8KB的block为单位的数组,即最小的分配单位是8KB。当Postgres想要从disk获取(主要是table和index)数据(page)时,他会(根据page的元数据)先搜索shared_buffers,确认该page是否在shared_buffers中,如果存在,则直接命中,返回缓存的数据以避免I/O。如果不存在,Postgres才会通过I/O访问disk获取数据。
缓冲区的分配
我们知道Postgres是基于进程工作的系统,即对于每一个服务器的connection,Postgres主进程都会向操作系统fork一个新的子进程(backend)去提供服务。同时,Postgres本身除了主进程之外也会起一些辅助的进程。
因此,对于每一个connection的数据请求,对应的后端进程(backend)都会首先向LRU cache中请求数据页page(这个数据请求不一定指的是SQL直接查询的表或者视图的page,比如index和系统表),这个时候就发起了一次缓冲区的分配请求。那么,这个时候我们就要抉择了。如果要请求的block就在cache中,那最好,我们"pinned"这个block,并且返回cache中的数据。所谓的"pinned"指的是增加这个block的"usage count"。
当"usage count"为0时,我们就认为这个block没用了,在后面cache满的时候,它就该挪挪窝了。
那也就是说,只有当buffers/slots已满的情况下,才会引发缓存区的换出操作。
缓存区的换出
决定哪个page该从内存中换出并写回到disk中,这是一个经典的计算机科学的问题。
一个最简单的LRU算法在实际情况下基本上很难work起来。因为LRU是要把最近最少使用的page换出去,但是我们没有记录上次运行时的状态。
因此,作为一个折中和替代,我们追踪并记录每个page的"usage count",在有需要时,将那些"usage count"为0的page换出并写回到disk中。后面也会提到,脏页面也会被写回disk。
以上是关于PostgreSQL 缓存的主要内容,如果未能解决你的问题,请参考以下文章