基于统计的中文实体识别方法简述
Posted 一个芝麻糕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于统计的中文实体识别方法简述相关的知识,希望对你有一定的参考价值。
命名实体识别(NER)是自然语言处理的一个基础任务,其目的是识别出语料中的人名、地名、组织机构名等命名实体,一般包括三大类(实体类、时间类和数字类)和七小类(人名、地名、机构名、时间、日期、货币和百分比)。NER是信息抽取、机器翻译、知识图谱等多种自然语言处理任务必不可少的组成部分。
NER方法大致可分为两类:基于规则的方法和基于统计的方法。基于规则的方法多采用语言学家手工构造规则模板,这类系统大多依赖于知识库和词典,需要人工建立实体识别规则,成本高且可移植性差。基于统计的方法一般需要语料库来进行训练,常用的方法有HMM、CRF和神经网络等。本文主要介绍基于统计的方法,先简单介绍CRF,然后简单介绍BiLSTM-CRF。
CRF
条件随机场(CRF)是给定一组输入序列条件下另一组输出序列的条件概率分布模型,定义:设 X 与 Y 是随机变量,P(Y|X) 是给定 X 时 Y 的条件概率分布,若随机变量 Y 构成的是一个马尔科夫随机场,则称条件概率分布 P(Y|X) 是条件随机场。
先来看什么是随机场,随机场是由若干个位置组成的整体,当按照某种分布给每一个位置随机赋予一个值之后,其全体就叫做随机场。马尔科夫随机场是随机场的特例,它假设随机场中某一个位置的赋值仅仅与和它相邻的位置的赋值有关,和与其不相邻的位置的赋值无关。CRF 是马尔科夫随机场的特例,它假设马尔科夫随机场中只有 X 和 Y 两种变量,X 一般是给定的,而 Y 一般是在给定 X 的条件下的输出,这样马尔科夫随机场就特化成了条件随机场。
再来看看什么是线性链条件随机场,在上述CRF的定义中,并没有要求X和Y具有相同的结构,而实现中,一般都假设X和Y有相同的结构,即:X=(X1,X2,...Xn),Y=(Y1,Y2,...Yn),有相同结构的CRF就构成了线性链条件随机场(linear-CRF),如词性标注中一句话被分成10个词,10个词对应10个词性。
CRF++是著名的条件随机场开源工具,也是目前综合性能最佳的CRF工具,其实现NER的算法流程为:
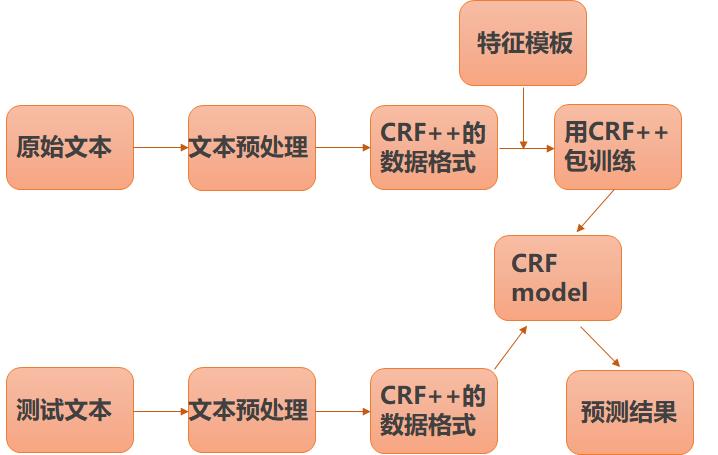
CRF++的数据格式:即句子中的每个字有一个标签,可用BMEWO做标注体系,B代表实体的首部,M代表实体的中部,E代表实体的尾部,W代表单个的实体,O代表非实体。
特征模板:通常是人工定义的一些二值特征函数,试图挖掘命名实体内部以及上下文的构成特点。对于句子中的给定位置来说,提特征的位置是一个窗口,即上下文位置。而且,不同的特征模板之间可以进行组合来形成一个新的特征模板。对句子中的各个位置提取特征时,满足条件的特征取值为1,不满足条件的特征取值为0,然后把特征喂给CRF进行训练。
CRF的优点在于其为一个位置进行标注的过程中可以利用到此前已经标注的信息,利用Viterbi解码来得到最优序列。训练阶段建模标签的转移,进而在预测阶段为测试句子的各个位置做标注。
BiLSTM-CRF
循环神经网络可以有效处理许多NLP任务(如CWS、POS、NER)。原理简单概述是将词从one-hot表示映射到低维空间中成为稠密的embedding,随后将句子的embedding序列输入到RNN中,然后Softmax来预测每个词的标签。
同上述CRF++数据格式一样,BiLSTM-CRF 可采用BIO标注集,如B-PER、I-PER代表人名首字、人名非首字,B-LOC、I-LOC代表地名首字、地名非首字,B-ORG、I-ORG代表组织机构名首字、组织机构名非首字,O代表该字不属于命名实体的一部分。
在说BiLSTM-CRF之前先说一下BiLSTM,单独的LSTM也可以做NER任务。通过词嵌入将句子输入双向LSTM后接Softmax分类,输出各个时刻的最大概率,则每个词对应的标记也就随之确定。但这种方法对每个词打标签的过程中是独立的分类,不能直接利用上一时刻已经预测的标签,进而导致预测出的标签序列可能是非法的,例如标签B-PER后面是不可能紧跟着I-LOC的,Softmax不会利用到这个信息,所以后面需再接一个CRF层,使得标注过程不再是对各个词独立分类。
CRF层通过加入一些约束来保证最终预测结果是有效的,这些约束可以在训练数据时被CRF层自动学习得到。可能的约束条件有:句子开头应该是“B-”或“O”,而不是“I-”,诸如此类。有了这些约束,错误的预测序列将会大大减少。完整的网络结构如下:

先通过状态分数(BiLSTM的输出)和转移分数(CRF层的转移分数矩阵)来计算句子对应的真实标记得分,然后优化模型的损失函数,损失函数由两部分组成,真实标记的分数和所有标记的总分数,真实标记的分数应该是所有标记中分数最高的,在训练阶段,BiLSTM-CRF模型的参数值将随着训练过程的迭代不断更新,使得真实标记所占的比值越来越大,最后在预测阶段使用动态规划的Viterbi算法来求解最优路径。
以上是关于基于统计的中文实体识别方法简述的主要内容,如果未能解决你的问题,请参考以下文章