Task5(2天)模型调参
Posted hero1best
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Task5(2天)模型调参相关的知识,希望对你有一定的参考价值。
- 使用网格搜索法对5个模型进行调优(调参时采用五折交叉验证的方式),并进行模型评估,记得展示代码的运行结果。 时间:2天
1.利用GGridSearchCV调参
1.1参数选择
首先选择5个模型要调的参数,这里是根据以前在知乎看的一张图片(感谢大佬!)
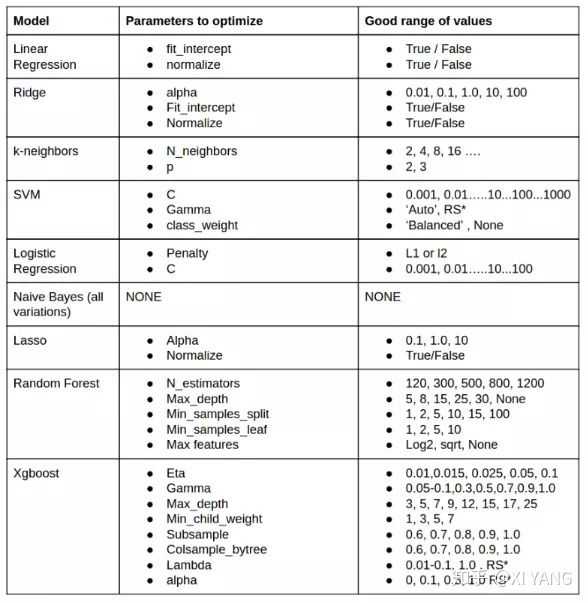
parameters_log = {‘C‘:[0.001,0.01,0.1,1,10]}
parameters_svc = {‘C‘:[0.001,0.01,0.1,1,10]} #这两个模型本来分数就不行,就少选择写参数来搜索
parameters_tree = {‘max_depth‘:[5,8,15,25,30,None],‘min_samples_leaf‘:[1,2,5,10], ‘min_samples_split‘:[2,5,10,15]}
parameters_forest = {‘max_depth‘:[5,8,15,25,30,None],‘min_samples_leaf‘:[1,2,5,10],
‘min_samples_split‘:[2,5,10,15],‘n_estimators‘:[7,8,9,10]} #这两个模型过拟合很厉害,参数多点
parameters_xgb = {‘gamma‘:[0,0.05,0.1,0.3,0.5],‘learning_rate‘:[0.01,0.015,0.025,0.05,0.1],
‘max_depth‘:[3,5,7,9],‘reg_alpha‘:[0,0.1,0.5,1.0]} #这个模型表现挺好,多调试一点
parameters_total = {‘log_clf‘:parameters_log,‘svc_clf‘:parameters_svc,‘tree_clf‘:parameters_tree,
‘forest_clf‘:parameters_forest,‘xgb_clf‘:parameters_xgb}
1.2划分验证集
本来想用sklearn的模块划分的,但是好像不能传入数组,就是手动划分前1000个样本
X_val = X_train_scaled[:1000] y_val = y_train[:1000]
1.3模型用字典集合
from sklearn.model_selection import GridSearchCV def gridsearch(X_val,y_val,models,parameters_total): models_grid = {} for model in models: grid_search = GridSearchCV(models[model],param_grid=parameters_total[model],n_jobs=-1,cv=5,verbose=10) grid_search.fit(X_val,y_val) models_grid[model] = grid_search.best_estimator_ return models_grid
1.4查看参数
models_grid
{‘log_clf‘: LogisticRegression(C=0.1, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class=‘warn‘,
n_jobs=None, penalty=‘l2‘, random_state=None, solver=‘warn‘,
tol=0.0001, verbose=0, warm_start=False),
‘svc_clf‘: SVC(C=10, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=‘ovr‘, degree=3, gamma=‘auto_deprecated‘,
kernel=‘rbf‘, max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False),
‘tree_clf‘: DecisionTreeClassifier(class_weight=None, criterion=‘gini‘, max_depth=5,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=5, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter=‘best‘),
‘forest_clf‘: RandomForestClassifier(bootstrap=True, class_weight=None, criterion=‘gini‘,
max_depth=15, max_features=‘auto‘, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=10, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=7, n_jobs=None,
oob_score=False, random_state=None, verbose=0,
warm_start=False),
‘xgb_clf‘: XGBClassifier(base_score=0.5, booster=‘gbtree‘, colsample_bylevel=1,
colsample_bytree=1, gamma=0.5, learning_rate=0.05, max_delta_step=0,
max_depth=5, min_child_weight=1, missing=None, n_estimators=100,
n_jobs=1, nthread=None, objective=‘binary:logistic‘, random_state=0,
reg_alpha=1.0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1)}
2.参数优化前后对比
models_grid = gridsearch(X_val,y_val,models,parameters_total)
results_test_grid,results_train_grid = metrics(models_grid,X_train_scaled,X_test_scaled,y_train,y_test)
左边优化前,右边优化后
训练集上: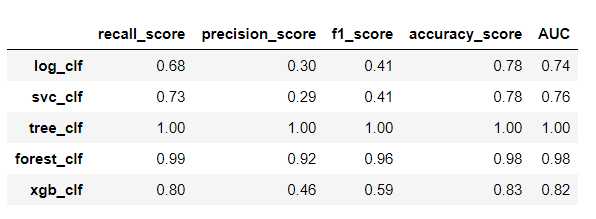
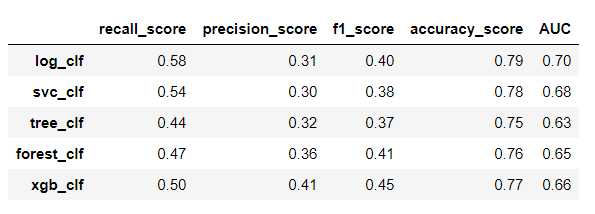
测试集上: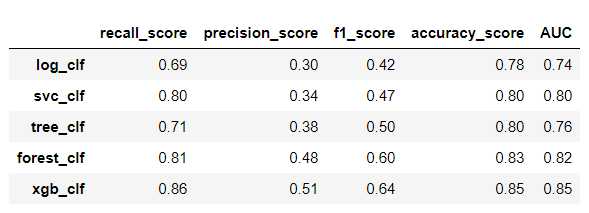
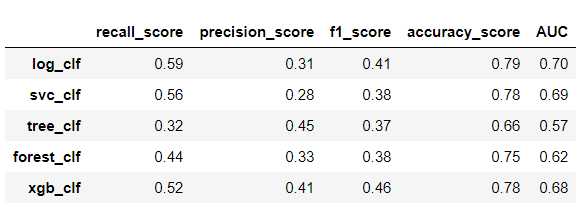
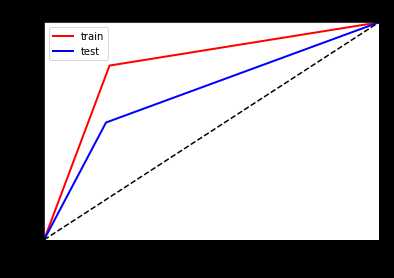
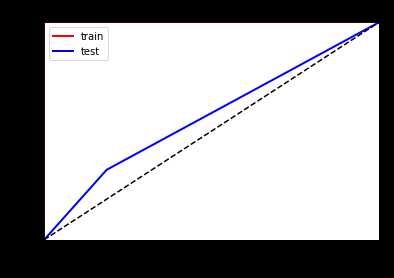
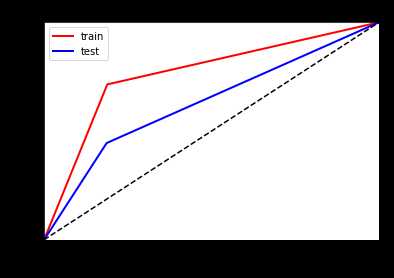
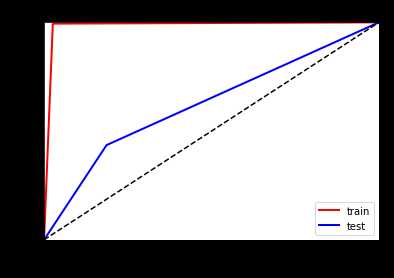
可以看到明显的防止了树模型的过拟合,但是其他评估数据提升不是很大!!
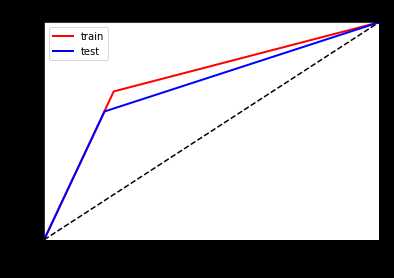
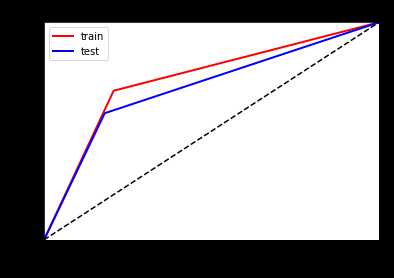
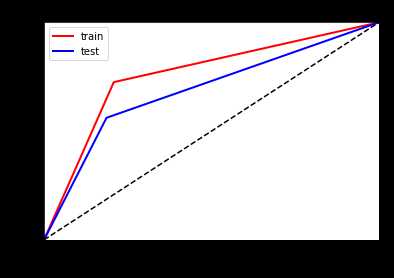
看一下ROC曲线对比
左边优化前,右边优化后
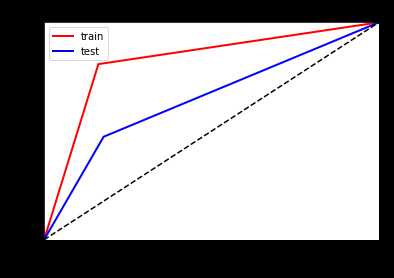
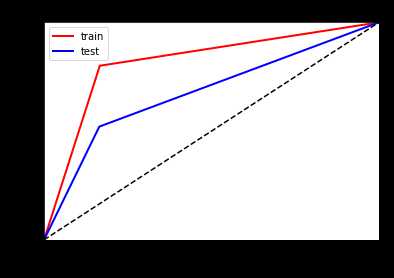
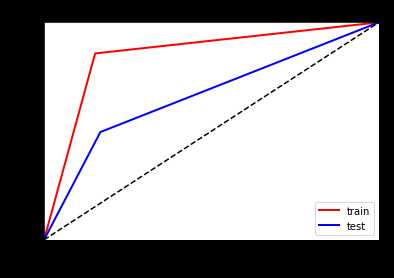
以上是关于Task5(2天)模型调参的主要内容,如果未能解决你的问题,请参考以下文章