基于MBT的自动化测试工具——GraphWalker介绍和实际使用
Posted loleina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于MBT的自动化测试工具——GraphWalker介绍和实际使用相关的知识,希望对你有一定的参考价值。
GraphWalker是一个开源的基于模型的自动化测试工具,它可以用来通过图形测试模型来自动生成测试用例。
本文主要描述了使用yed画出FSM, EFSM模型图(常见的流程图),然后使用GraphWalker命令生成手工自动化用例,最终通过python将手工用例读取后自动执行并生成执行报告。
一: GraphWalker概述
GraphWalker就是一个基于测试模型的用例生成工具。它主要应用于FSM, EFSM模型。可以用来它可以直接读取FSM, EFSM图形模型、json模型、生成测试用例。那什么是MBT呢? MBT中文名称为基于模型的测试, 基于模型的测试属于软件测试领域的一种测试方法。MBT步骤如下:首先由被测系统(SUT, system under test )的一些(通常是功能)方面描述,构建出被测系统的模型。再根据模型或模型中的一部分部分生成测试用例。进而进行软件测试。常见的MBT中模型通常有下列几种:
- 前置后置条件模型: Pre and post condition models (State based, OCL)
- 基于转换的模型: Transition based models (FSM, EFSM)
- 随机模型:Stochastic models (Markov chains)
- .数据流模型: Data-flowmodels(Lustre)
二:工具下载:
1、画图工具YED
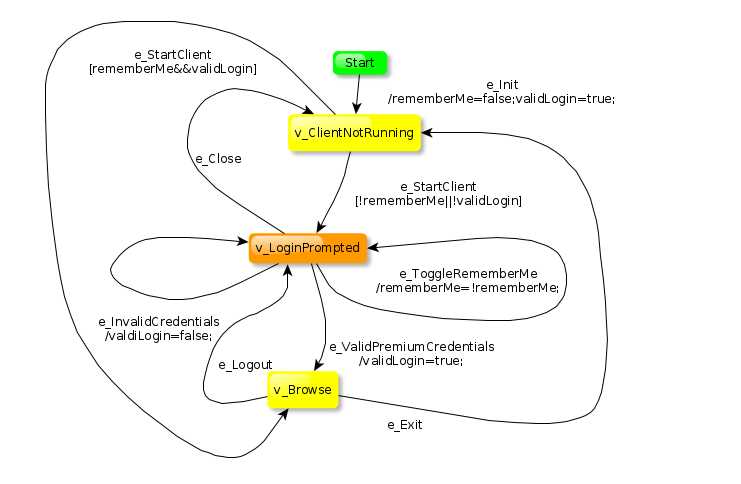
工具下载官网地址:https://www.yworks.com/products/yed,用该工具画出来的图大致如下:
2、 GraphWalker的jar包下载:
https://graphwalker.github.io/
三:学习笔记整理 (关键知识点)
1、顶点:如上图所示,所有的顶点比如Start,V_ClientNotRuning.一个顶点称为节点,通常表示为一个框表示我们想要检查的预期状态。在任何实现代码/测试中,可以通过断言或者数据校验改结果。常见有以下几种顶点:
-
Start顶点:start顶点不是必需的。如果使用,则必须有1个(且只有1个)顶点名称为:start.从start顶点出发只能有1个边。start顶点不会包括在任何生成的测试路径中,它只表示一个开始位。
- BLOCKED顶点: 包含此关键字的顶点或边将在生成路径时排除。如果它是一个边,它将简单地从图中删除。如果它是一个顶点,顶点将被删除与其内外边缘。
-
SHARED顶点: 意味着GraphWalker可以跳出当前模型,到任何其他模型到具有相同SHARED名称的顶点。 语法是: SHARED:SOME_NAME
- INIT顶点: 只有一个顶点可以有这个关键字。在模型中使用数据时,需要初始化数据。这就是这个关键字。允许在更多的顶点中使用INIT而不只是一个。 语法是: INIT:loggedIn = false; rememberMe = true;
2、边:如上图的e_Init。表示从一个顶点到另一个顶点的方法。这是为了达到下一个状态需要做的任何动作。它可以选择一些菜单选项,单击按钮等测试动作。GraphWalker只接受单向有向边(箭头)。边
的函数下有时候会有不同的字符串,比如[rememberMe&vaildLogin]和/rememberMe=false; vaildLogin=true; 表示不同的规则,基于表有如下规则:
-
守卫(Guards):他们的角色与if语句相同,并且使边有资格或者没有资格被访问。
守卫guard是一个用方括号括起来的javascript条件表达式只有一个。[rememberMe&vaildLogin]
- 操作(Action):它放在正斜杠之后。Action可以有多个,每个语句必须以分号结尾。
/rememberMe=false; vaildLogin=true ;action是动作代码,它的执行结果将作为数据传递给守卫。
3、路径生成器:生成器是决定如何遍历模型的算法。不同的生成器将生成不同的测试序列,并且它们将以不同的方式遍历模型。多个发生器可以串联。常见有以下几种:
- random( some stop condition(s) ):以完全随机的方式浏览模型。也称为“醉汉走路”或“随机步行”。该算法通过随机从顶点选择出边,并且在下一个顶点时重复此过程。
- quick_random( some stop condition(s) ):尝试运行通过模型的最短路径,但以快速的方式。
- a_star( a stop condition that names a vertex or an edge ):将生成到特定顶点或边的最短路径。
4、结束条件:常见有以下几种:
- edge_coverage( an integer representing percentage of desired edge coverage ):边覆盖率达到某个值时,模型遍历结束。停止标准是一个百分比数字。当在执行期间达到所穿过的边的百分比时,停止测试。如果一个边被遍历超过一次,当计算百分比覆盖率时,它仍然计为1
- vertex_coverage( an integer representing percentage of desired vertex coverage ):顶点覆盖率达到某个值时,模型遍历结束。停止标准是一个百分比数字。当在执行期间达到所遍历的顶点的百分比时,停止测试。如果顶点遍历超过一次,当计算百分比覆盖率时,它仍然计为1。
- requirement_coverage( an integer representing percentage of desired requirement coverage ):需求覆盖率达到某个值时,模型遍历结束。停止标准是一个百分比数字。当在执行期间达到所需求的百分比时,测试停止。如果需求遍历超过一次,在计算百分比覆盖率时仍会计为1。
- dependency_edge_coverage( an integer representing dependency treshold ):高于依赖阈值的边都被覆盖时,模型遍历结束。每个边可以设置一个依赖值dependency(0-100之间的百分比数字)。停止标准是一个百分比数字。当在执行期间,所有高于或等于依赖值边被遍历完全时,停止测试。如果一个边被遍历超过一次,当计算百分比覆盖率时,它仍然计为1。
- reached_vertex( the name of the vertex to reach ):停止标准是指定的顶点。当在执行期间到达顶点时,测试停止。
- reached_edge( the name of the edge to reach ):停止标准是指定的边。当在执行期间到达这条边时,测试停止。
5、GraphWalker提供3种工作方式:
- 作为第三方库,可被java测试程序直接调用。如果是使用java语言来编写自动化测试框架,可以考虑使用这种工作方式。
- 作为可执行程序,以offline模式,加载model,直接运行。接口测试常用此方法一次获取完整的手工测试用例。
- 作为可执行程序,以online模式,作为service,提供服务。改方法方便读取自动化测试用例,但是每获取一次需要调用一次service,有点麻烦。
6、学习参考文档:
- 官网:http://graphwalker.github.io/
- 中文翻译:https://cloud.tencent.com/developer/article/1004579
四:初体验
以2.1的图为例,是官网的的demo图。下载地址:http://graphwalker.github.io/Model_design/,找到图片后双击即可下载:Login.graphml
1、可执行程序,以offline模式生成自动化用例,路径生成器使用常用的quick_random,结束条件使用vertex_coverage100%覆盖,在jar包目录下执行命令java -jar graphwalker-cli-3.4.2.jar offline -m Login.graphml "quick_random(vertex_coverage(100))" ,如下会生成对应的自动化用例。

也可以把这些用例保存在txt文件中:java -jar graphwalker-cli-3.4.2.jar offline -m Login.graphml "quick_random(vertex_coverage(100))" > login_test_case.txt
2、可执行程序,以online模式生成自动化用例,使用相同的结束条件和路径生成器,
第一步执行命令:java -jar graphwalker-cli-3.4.2.jar -d all online -s RESTFUL -m Login.graphml "quick_random(vertex_coverage(100))" ,结果如下:

第二步:简单的在web浏览器访问:http://localhost:8887/graphwalker/getNext

再访问一次:

五:实际使用心得
目前测试工作中,常用的就是状态机测试和模块间的数据流测试。这个工具就非常适合这两类图的测试。在生成手工用例后,怎么转变成自动化测试用例是考虑的主要问题。下面以实际工作中的一个状态机为例
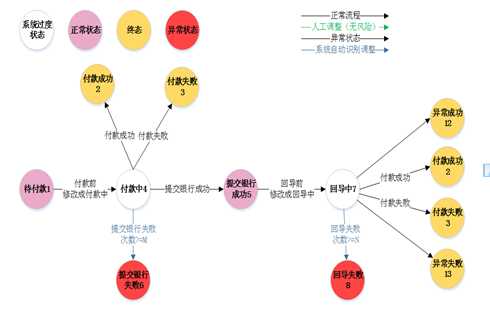
第一步 : 把工作中的状态机图,使用yed转换成graph图。
状态机如下:
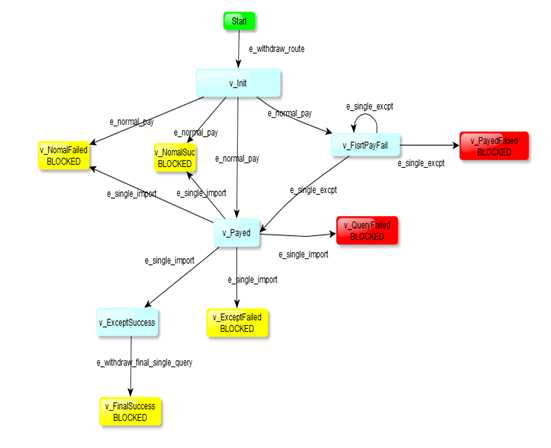
yed 画图之后:
第二步:执行graphwalker命令生成测试用例,报错 java -jar graphwalker-cli-3.4.2.jar offline -m rtp_status.graphml "quick_random(edge_coverage(100))" > bpn_status_test_case.txt。
执行报错:报错原因:因为状态机内存在终点,导致算法执行不下去报错失败。那这就不适应有终点的状态机了?

突然想起一句名言: 我是环绕着一个圆圈而行的。越接近终点也就越接近起点——-(狄斯)。人丑多读书还是有点用处的,灵机一动,那就干脆把所有终点再指定起点,起点又算是一笔新的数据,讲图改造后如下:
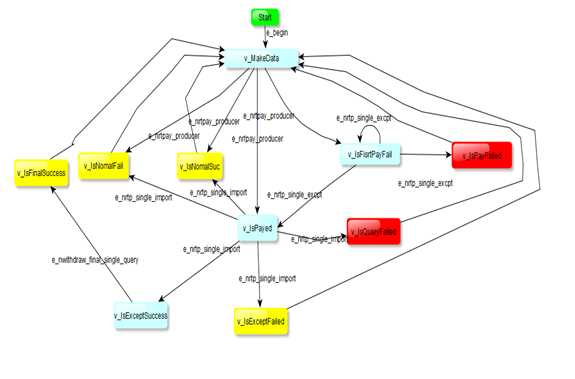
虽然变丑了,但是再执行不会报错。目的达到了(每次执行的产生的用例是不完全一致的)。用例如下图:
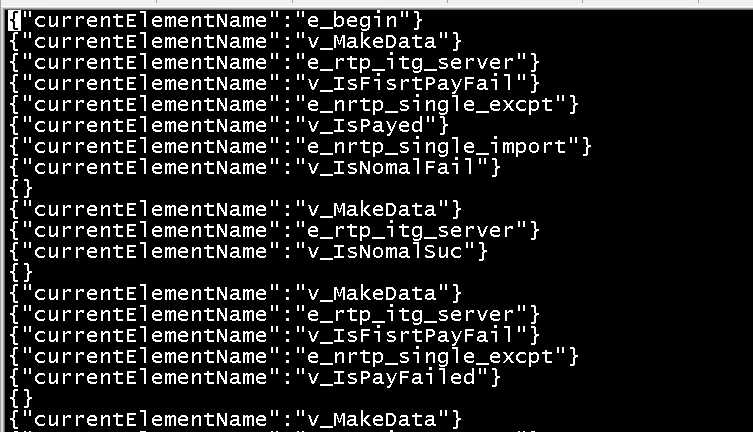
第三步:思考怎么转变成自动化用例。
思考问题:
- 生成的用例集,怎么区分每一条用例。
从终点到顶点V_MakeData的边都没有标签,那python读取文件时,可以根据两个{}之前确定是一条用例。
- python读取每一个顶点和每一个边,意味着什么?
边意味着执行某个程序,顶点意味着检查表的数据状态。那在画图时,确定好边和顶点的描述,做好string和代码对象的映射,读取到边,就启动程序,读取到顶点,就执行某个表的校验函数即可。
- 怎么设计整体架构?综上问题描述,大致思路整理如下:
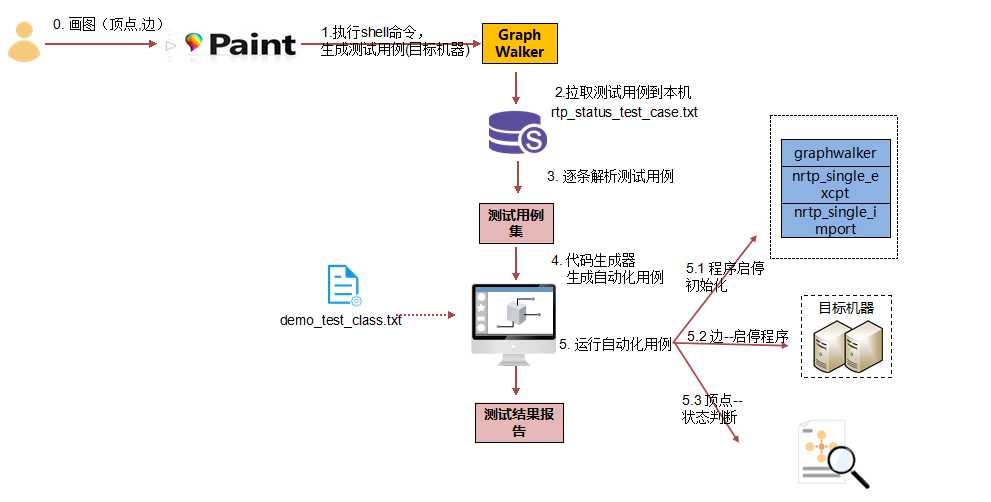
第四步:代码实现:
1、主要业务流程:

2、生成python自动化用例使用的方法,考虑到其实执行的步骤是明确的,唯一会变化的就是执行命令每次产生的用例不一致。那每次替换用例case就可以了。做成了文件替换动态生成自动化用例的模式。
3、自动化用例剩下如下:

4、说明:
在编写自动化生成用例前,已存在构建好的python自动化pyuint测试框架,我这边结合起来使用就很方便。这个技术结合pyunit框架做效果更好。
六:总结
这个工具的学习来源于其他部门测试同事的分享,他们把这个工具应用于web平台的类似登陆系统的测试,觉得确实好用。虽然这个工具和理念很早就已经有了,貌似2016年左右就已经很流行了,但不影响去深入的学习和研究。学习和研究工具的目的,最终都是把它应用到实际项目之中。类似这种状态机测试,如果这时在一个地方增加了一个状态。那我只需要改下图,再补充好对应顶点和边的部分代码,就可以获取全流程的状态机测试用例。
这个工具还是很强大的,特别是在数据流的各种处理上,有时间还是建议去看下官网,毕竟介绍更详细。
以上是关于基于MBT的自动化测试工具——GraphWalker介绍和实际使用的主要内容,如果未能解决你的问题,请参考以下文章