Python爬虫-Scrapy-CrawlSpider与ItemLoader
Posted yangshaolun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫-Scrapy-CrawlSpider与ItemLoader相关的知识,希望对你有一定的参考价值。
一、CrawlSpider

根据官方文档可以了解到, 虽然对于特定的网页来说不一定是最好的选择, 但是 CrwalSpider 是爬取规整的网页时最常用的 spider, 而且有很好的可塑性.
除了继承自 Spider 的属性, 它还拓展了一些其他的属性. 对我来说, 最常用的就是 rules 了.
爬虫一般来说分为垂直爬取和水平爬取, 这里拿 猫眼电影TOP100 举例. 垂直爬取就是从目录进入到内容详情后爬取, 即从当前页进入某一影片的详情页面; 水平爬取就是从这一页目录翻到下一页目录后爬取, 即从当前页到排名第十一至二十的页面. 不论是哪一种爬取, 都离不开 url, 即你想要去到的页面的链接, 而 rules 就为我们提供了一套提取链接的规则, 以及得到链接后应该怎么做.
来看一下 rules 中 Rule 的定义, class scrapy.spiders.Rule(link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None), 这里也只说我自己经常用到的.
1. link_extractor:
class scrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(), tags=(‘a‘, ‘area‘), attrs=(‘href‘,), canonicalize=False, unique=True,
process_value=None, deny_extensions=None, restrict_css=(), strip=True)
提取链接的规则在这里定义, 并且提取出链接后会生成一个 scrapy.Request 对象. allow里是正则表达式, 过滤掉不符合要求的链接; restrict_xpath 和 restrict_css定义获取链接的区域.
2. callback:
回调函数, 请求得到相应后用什么方法处理, 和 Request 中的 callback 一样, 但是此处以字符串形式表示而不是方法引用.
3. follow:
请求得到响应后是否继续用本套rules规则来提取链接. 布尔值类型, 如果callback为None, 则默认为True, 否则为False.
这里的 rules 功能类似于 Spider类里的 parse() 方法, 请求 start_urls 中的链接, 并且返回新的 Request.
二、ItemLoader

Items 为抓取的数据提供了容器, 而 Item Loaders 提供填充容器的机制, 并且其API更加便捷好用.
之前用 Spider 类的时候, 一般都是直接使用 scrapy.item 的, 当网页高度规整的时候我们改用了 CrawlSpider 类. 当获取到高度规整的数据时, 我们想要进行处理, 这时候 Item Loader 就发挥其作用了.
定义: class scrapy.loader.ItemLoader(item=None, selector=None, response=None, parent=None, **context)
item: 自己定义的容器.
selector: Selector 对象, 提取填充数据的选择器.
response: Response 对象, 可以构造选择器的响应, 因为 scrapy 里的响应可以直接使用 xpath 或 css, 这里把它当成选择器也差不多.
ItemLoader 的使用:
1 from scrapy.loader import ItemLoader 2 from qoutes.items import QuoteItem 3 import time 4 5 def parse_item(self, response): 6 quotes = response.css(‘.quote‘) 7 for quote in quotes: 8 loader = ItemLoader(item=QuoteItem(), selector=quote) 9 loader.add_css(‘author‘, ‘.author::text‘) 10 loader.add_css(‘tags‘, ‘.tag::text‘) 11 loader.add_xpath(‘text‘, ‘.//*[@class="tag"]/text()‘) 12 loader.add_value(‘addtime‘, time.ctime()) 13 yield loader.load_item()
相较于 Item 的字典类使用方法, ItemLoader 显得更简单明了, 这样的代码有着更好的可维护性以及自描述性.
这里有两个小问题特别说一下, 是我自己刚开始使用 ItemLoader 时犯的错.
第一个就是, 使用 ItemLoader 后不需要调用 extract() 了, item里的值类型为 list.
第二个就是, 当页面中有多个 item, 循环遍历时是使用 selector=‘你的选择器‘. 如果使用 response=‘你的响应‘ 的话, 你会发现返回的 item 内容要么出错要么重复.
处理器: 结合数据以及对数据进行格式化和清洗的函数
例:
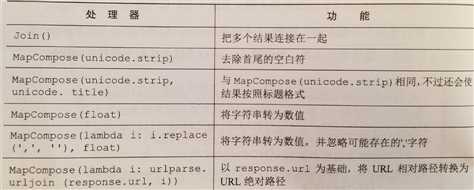
上图中的 "unicode" 应替换为 "str".
对我来说, 最常用就是 MapCompose 搭配匿名函数, 可以更加灵活的处理数据. MapCompose 和 Python 内置的 map 类似, 根据所给函数来遍历处理可迭代对象中的每个值.
使用方法也挺简单, 只需要在编写填充机制的时候加上处理器即可, 如: loader.add_css(‘tags‘, ‘.tag::text‘, MapCompose(str.title)).
定义 ItemLoader 的子类:
就我而言, 定义子类最大的意义就是可以对每个已获得的数据使用指定的处理器.
刚刚说过, ItemLoader 会对 xpath 或 css 提取出来的结果做出类似 extract() 的处理, 所以结果都会以列表的形式返回. 有时候列表里就一个以字符串形式表示的值, 我们希望直接得到字符串, 这时可以使用处理器 TakeFirst(), 返回列表第一个非空值, 类似于 extract_first(). 如果所有的结果要做这样的处理, 那在编写填充机制的时候依次添加处理器就显得过于麻烦了. 此时我们就可以定义一个 ItemLoader 的子类.
通过重写 default_input_processor 和 default_input_processor 便可以达到目的.
例:
1 class NewLoader(ItemLoader): 2 default_input_processor = TakeFirst() 3 default_output_processor = str.title()
需要注意的是处理器执行的顺序, 最先执行编写填充机制时加的处理器, 接着是 default_input_processor, 然后是defualt_output_processor.
所有的处理在使用之前都需要导入.
以上便是我目前对 Scrapy 中 CrawlSpider 与 ItemLoader 的了解.
以上是关于Python爬虫-Scrapy-CrawlSpider与ItemLoader的主要内容,如果未能解决你的问题,请参考以下文章