全志H3平台DMA框架
Posted dlijun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全志H3平台DMA框架相关的知识,希望对你有一定的参考价值。
1 概要
Dmaengine是linux内核dma驱动框架,针对DMA驱动的混乱局面内核社区提出了一个全新的框架驱动,目标在统一dma API让各个模块使用DMA时不用关心硬件细节,同时代码复用提高,并且实现异步的数据传输,降低机器负载。
1.1 基本结构
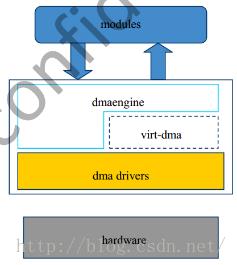
dmaengine向其他模块提供接口;virt-dma,Virtual DMA向dmaengine提供初始化函数,传输各阶段状态登记链表,desc_free函数等;dma drivers为具体DMA控制器的驱动代码,其通过dma_async_device_register()注册到dmaengine。
2 代码架构
lli: linked list ltem, the DMA block descriptor
2.1 源码分析
linux-3.4/drivers/dma
dmaengine.c


注册dma类,在调用dma_async_device_register注册具体平台的DMA设备时会用到。
sunxi-dma.c

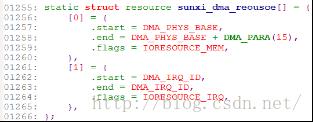
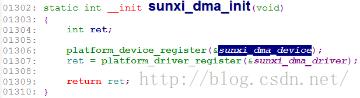
sunxi_probe解析:
1.1 ret = request_irq(irq, sunxi_dma_interrupt, IRQF_SHARED,dev_name(&pdev->dev), sunxi_dev);//注册中断
1.2 clk_get(&pdev->dev, "dma"); //获取时钟
drivers/clk/sunxi/ clk-sun8iw7.c
SUNXI_CLK_PERIPH (dma,0,0,0,0,0,0,0,0,0,0,BUS_RST0,BUS_GATE0,0,0,6, 6,0,&clk_lock,NULL, 0)
struct periph_init_data sunxi_periphs_init[] = {
{"dma",0,ahb1mod_parents,ARRAY_SIZE(ahb1mod_parents),&sunxi_clk_periph_dma}
}
drivers/clk/sunxi/clk-periph.h 定义SUNXI_CLK_PERIPH宏
sunxi_init_clocks -> sunxi_clk_register_periph -> clk_register(NULL, &periph->hw);
1.3 dma_pool_create, 创建一个一致内存块池,其参数name是DMA池的名字,用于诊断用,参数dev是将做DMA的设备,参数size是DMA池里的块的大小,参数align是块的对齐要求,是2的幂,参数allocation返回没有跨越边界的块数(或0)。
1.4 vchan_init初始化virt_dma_chan
1.5初始化sunxi_dev->dma_dev结构成员后,调用dma_async_device_register(&sunxi_dev->dma_dev)注册到dmaengine
1.5.1 get_dma_id(device) //建立idr机制,分配一个新idr entry,将返回值存储在&sunxi_dev->dma_dev->dev_id中。
1.5.2 在DMA完全准备好之前,已经有客户端在等待channel时,遍历所有的channel,调用dma_chan_get(chan)
1.5.3 list_add_tail_rcu(&device->global_node, &dma_device_list) //将& dma_device. global_node加入静态链表中。
1.5.4 dma_channel_rebalance
1.5.4.1 chan->device->device_alloc_chan_resources(chan); <=> sunxi_alloc_chan_resources //无实际作用,最后返回0
1.5.4.2 balance_ref_count
1.6最后调用sunxi_dma_hw_init(sunxi_dev);使能时钟, -> clk_prepare_enable(sunxi_dev->ahb_clk);
2.2 数据结构关系图
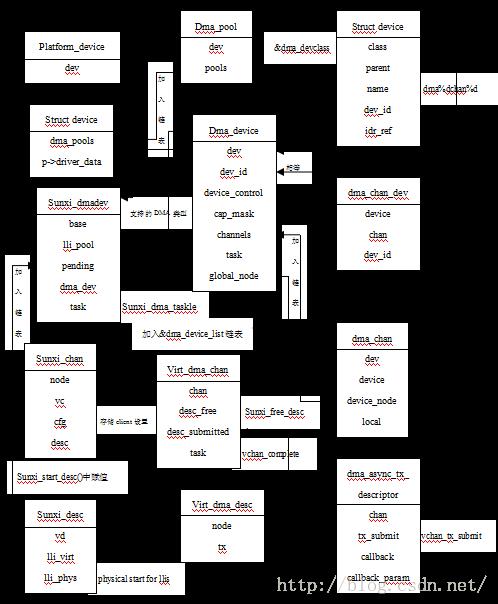
dma_device结构体集成DMA控制器的核心函数,实现最底层的具体操作; 新建立的sunxi_chan对应每个通道,该结构体一面存放用户配置的cfg成员,另外就是包含virt_dma_chan,它用virt-dma提供的函数初始,并将vc->chan.device_node链接到dma_device结构体的channels链表中,后续实际的DMA通道的申请就是申请vc->chan通道,而vc->chan在内核中建立相应的文件节点,即chan->dev,生成的节点如下:
/sys/devices/platform/sunxi_dmac/dma/dma0chan0
在准备一次传输时,e.g chan->device->device_prep_dma_sg 即调用sunxi_prep_dma_sg,创建sunxi_desc结构体并初始化,该结构体可以理解为通道中具体运载工具,在传输完成后销毁。
在不同的传输阶段,会将Virt_dma_desc.node链入不同的virt_dma_chan链表中,如desc_submitted,desc_issued,desc_completed。
其他模块在调用dmaengine提供的接口来使用DMA时,是通过遍历&dma_device_list链表找到相应的dma device。
在sunxi_start_desc函数中,会将txd->lli_phys写入DMA寄存器中,之前设置的相应参数,如slave_id,起始地址等,将由DMA控制器来解析,选择等。
2.3 对外接口函数
include/linux/ dmaengine.h
#define dma_request_channel(mask, x, y) __dma_request_channel(&(mask), x, y)
struct dma_chan *__dma_request_channel(dma_cap_mask_t *mask, dma_filter_fn fn, void *fn_param) // mask,所有申请的传输类型的掩码;fn, DMA驱动私有的过滤函数;fn_param,传入的私有参数
1.从dma_device_list全局链表中找到可用的dma_device
2. private_candidate(mask, device, fn, fn_param);//根据mask判断device是否符合要求,在满足条件的情况下,a.如果所有的通道都是公有的,在没有用户使用的情况下执行b,否则冲突,返回NULL;b.遍历dam_device.channels链表中的dma_chan,找到第一个client_count为0的chan.具体代码如下:
static struct dma_chan *private_candidate(dma_cap_mask_t *mask, struct dma_device *dev,
dma_filter_fn fn, void *fn_param)
{
struct dma_chan *chan;
if (!__dma_device_satisfies_mask(dev, mask)) {
pr_debug("%s: wrong capabilities\\n", __func__);
return NULL;
}
/* devices with multiple channels need special handling as we need to
* ensure that all channels are either private or public.
*/
if (dev->chancnt > 1 && !dma_has_cap(DMA_PRIVATE, dev->cap_mask))
list_for_each_entry(chan, &dev->channels, device_node) {
/* some channels are already publicly allocated */
if (chan->client_count)
return NULL;
}
list_for_each_entry(chan, &dev->channels, device_node) {
if (chan->client_count) {
pr_debug("%s: %s busy\\n",
__func__, dma_chan_name(chan));
continue;
}
if (fn && !fn(chan, fn_param)) {
pr_debug("%s: %s filter said false\\n",
__func__, dma_chan_name(chan));
continue;
}
return chan;
}
return NULL;
}3.找到合适的chan之后,
dma_cap_set(DMA_PRIVATE, device->cap_mask);// to disable balance_ref_count as this channel will not be published in the general-purpose allocator
device->privatecnt++;
err = dma_chan_get(chan);//a.获取dma channel’s parent driver模块,即该模块计数加1;
b. int desc_cnt = chan->device->device_alloc_chan_resources(chan);// <=> sunxi_alloc_chan_resources//设置schan->cyclic = false;
c. balance_ref_count(chan)//其目的是确保dma channel’s parent driver模块数与client数一致
include/linux/ dmaengine.h
static inline int dmaengine_slave_config(struct dma_chan *chan,struct dma_slave_config *config)
<=> dmaengine_device_control(chan, DMA_SLAVE_CONFIG,(unsigned long)config);
<=> chan->device->device_control(chan, cmd, arg);
<=> sunxi_control <=> sunxi_set_runtime_config(chan, (struct dma_slave_config *)arg); //最终将用户配置的相关参数存储到sunxi_chan.cfg中。
static inline struct dma_async_tx_descriptor *dmaengine_prep_dma_cyclic(
struct dma_chan *chan, dma_addr_t buf_addr, size_t buf_len,
size_t period_len, enum dma_transfer_direction dir,
unsigned long flags)
{
return chan->device->device_prep_dma_cyclic(chan, buf_addr, buf_len,period_len, dir, flags, NULL);
}
dmaengine_submit (struct dma_async_tx_descriptor *desc)
<=> drivers/dma/ virt-dma.c : vchan_tx_submit
cookie = dma_cookie_assign(tx);//递增cookie
list_add_tail(&vd->node, &vc->desc_submitted);//加入desc_submitted队列
static inline void dma_async_issue_pending(struct dma_chan *chan)
{
chan->device->device_issue_pending(chan);
}
<=> sunxi_issue_pending
a.vchan_issue_pending(&schan->vc) ->
list_splice_tail_init(&vc->desc_submitted, &vc->desc_issued);
__list_splice(list, head->prev, head);//
INIT_LIST_HEAD(list);//清空list
b. if (list_empty(&schan->node))
list_add_tail(&schan->node, &sdev->pending);//将schan->node加入链表sdev->pending
c. tasklet_schedule(&sdev->task);//调度sdev->task,执行sunxi_dma_tasklet ->
sunxi_start_desc // virt_dma_desc结构变量vd为空时停止本次DMA传输;否则,设置对应channel的中断号,DMA操作模式,将txd->lli_phys写入寄存器,正式DMA传输。
drivers/dma/ dmaengine.c
void dma_release_channel(struct dma_chan *chan)
1.dma_chan_put
chan->client_count--;
module_put(dma_chan_to_owner(chan));
if (chan->client_count == 0)
chan->device->device_free_chan_resources(chan); <=> sunxi_free_chan_resources ->
vchan_free_chan_resources: 获取所有的desc_submitted、desc_issued、desc_completed descriptors之后,调用vchan_dma_desc_free_list(vc, &head):
while (!list_empty(head)) {
struct virt_dma_desc *vd = list_first_entry(head,struct virt_dma_desc, node);
list_del(&vd->node);
dev_dbg(vc->chan.device->dev, "txd %p: freeing\\n", vd);
vc->desc_free(vd); // <=> sunxi_free_desc,释放virt_dma_desc
}2.判断--chan->device->privatecnt为0时,
dma_cap_clear(DMA_PRIVATE, chan->device->cap_mask)
3 使用流程
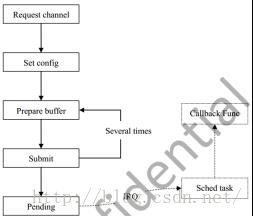
注意事项:
回调函数里不允许休眠,以及调度;
回调函数时间不宜过长;
Pending并不是立即传输而是等待软中断的到来,cyclic模式除外;
在dma_slave_config中的slave_id对于devices必须要指定.
4 实例分析
drivers/char/dma_test/ sunxi_dma_test.c

创建sunxi_dma_test类及其属性文件test、help
当向test输入0时,即调用dma_test_main(0) -> case_memcpy_single_chan()
1.buf_group *buffers = NULL; buffers = init_buf();//分配好内存
typedef struct {
unsigned int src_va;
unsigned int src_pa;
unsigned int dst_va;
unsigned int dst_pa;
unsigned int size;
}buf_item;
typedef struct {
unsigned int cnt;
buf_item item[BUF_MAX_CNT];
}buf_group;
2. chan = dma_request_channel(mask , NULL , NULL); //根据mask申请一个可用的通道
3. sg_alloc_table(&src_sg_table, buffers->cnt, GFP_KERNEL) // Allocate and initialize an sg table
使用scatterlist的原因就是系统在运行的时候内存会产生很多碎片,比如4k,100k的,1M的,有时候对应磁盘碎片,总之就是碎片。而在网络 和磁盘操作中很多时候需要传送大块的数据,尤其是使用DMA的时候,因为DMA操作的物理地址必须是连续的。假设要1M内存,此时可以分配一个整的1M内 存,也可以把10个10K的和9个100K的组成一块1M的内存,当然这19个块可能是不连续的,也可能其中某些或全部是连续的,总之情况不定,为了描述 这种情况,就引入了scatterlist,其实看成一个关于内存块构成的链表就OK了。
sg_set_buf(sg, phys_to_virt(buffers->item[i].src_pa), buffers->item[i].size);
sg_dma_address(sg) = buffers->item[i].src_pa;
4. dmaengine_slave_config(chan , &config); //配置参数,如传输方向,slave_id等。
5. tx = chan->device->device_prep_dma_sg(chan, dst_sg_table.sgl, buffers->cnt,
src_sg_table.sgl, buffers->cnt, DMA_PREP_INTERRUPT | DMA_CTRL_ACK);
准备一次多包传输,散列形式,返回一个传输描述符指针。
<=> sunxi_prep_dma_sg: //
a. vchan_tx_prep,初始化virt_dma_desc;
b. sunxi_alloc_lli//调用dma_pool_alloc从sunxi_dmadev.lli_pool内存块池分配内存。
c. sunxi_cfg_lli //配置sunxi_dma_lli相应参数,如flag,源地址,目的地址,数据长度等。
6.设置回调函数
dma_info.chan = chan;
init_waitqueue_head(&dma_info.dma_wq);
atomic_set(&dma_info.dma_done, 0);
tx->callback = __dma_callback; //唤醒中断;设置pinfo->dma_done为1。
tx->callback_param = &dma_info;
7.加入传输队列, cookie = dmaengine_submit(tx);
8.开始传输,dma_async_issue_pending(chan);
9.等待传输结束,ret = wait_event_interruptible_timeout(dma_info.dma_wq,atomic_read(&dma_info.dma_done)==1, timeout);
10.DMA传输完成后,产生中断,其中断处理函数为sunxi_dma_interrupt,
ch->desc = NULL;
vchan_cookie_complete(&desc->vd);
sunxi_start_desc(ch);// vchan_cookie_complete会释放virt_dma_desc,故会正常退出此次DMA传输。
vchan_cookie_complete解析:
a. dma_cookie_complete(&vd->tx);//设置cookie
b. list_add_tail(&vd->node, &vc->desc_completed);
c. tasklet_schedule(&vc->task); -> vchan_complete
list_splice_tail_init(&vc->desc_completed, &head);
list_del(&vd->node);
vc->desc_free(vd); ó sunxi_free_desc //释放virt_dma_desc
if (cb)
cb(cb_data);//执行回调函数
11. dma_release_channel(chan);
实例源码:
sunxi_dma_test.c
/*
* drivers/char/dma_test/sunxi_dma_test.c
*
* Copyright(c) 2013-2015 Allwinnertech Co., Ltd.
* http://www.allwinnertech.com
*
* Author: liugang <liugang@allwinnertech.com>
*
* sunxi dma test driver
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 2 of the License, or
* (at your option) any later version.
*/
#include "sunxi_dma_test.h"
/* wait queue for waiting dma done */
wait_queue_head_t g_dtc_queue[DTC_MAX];
atomic_t g_adma_done = ATOMIC_INIT(0); /* dma done flag */
//int size_available[] = {SZ_4K, SZ_64K, SZ_256K, SZ_512K, SZ_512K + SZ_64K, SZ_512K + SZ_256K, SZ_1M};
int size_available[] = {SZ_4K, SZ_16K, SZ_32K, SZ_64K, SZ_128K, SZ_256K, SZ_512K};
static void __dma_test_init_waitqueue(void)
{
u32 i = 0;
for(i = 0; i < DTC_MAX; i++)
init_waitqueue_head(&g_dtc_queue[i]);
}
static void __dma_callback(void *dma_async_param)
{
chan_info *pinfo = (chan_info *)dma_async_param;
wake_up_interruptible(&pinfo->dma_wq);
atomic_set(&pinfo->dma_done, 1);
}
buf_group *init_buf(void)
{
buf_group *pbuf = kmalloc(sizeof(buf_group), GFP_KERNEL);
int i, buf_cnt = (get_random_int()%BUF_MAX_CNT) + 1;
int size, index;
if (!pbuf)
return NULL;
for (i = 0; i < buf_cnt; i++) {
index = get_random_int() % ARRAY_SIZE(size_available);
size = size_available[index];
printk("%s(%d): buf %d, index %d, size 0x%x\\n", __func__, __LINE__, i, index, size);
pbuf->item[i].src_va = (u32)dma_alloc_coherent(NULL, size, (dma_addr_t *)&pbuf->item[i].src_pa, GFP_KERNEL);
if (!pbuf->item[i].src_va)
break;
pbuf->item[i].dst_va = (u32)dma_alloc_coherent(NULL, size, (dma_addr_t *)&pbuf->item[i].dst_pa, GFP_KERNEL);
if (!pbuf->item[i].dst_va) {
dma_free_coherent(NULL, size, (void *)pbuf->item[i].src_va, (dma_addr_t)pbuf->item[i].src_pa);
break;
}
memset((void *)pbuf->item[i].src_va, 0x54, size);
memset((void *)pbuf->item[i].dst_va, 0xab, size);
pbuf->item[i].size = size;
}
pbuf->cnt = i;
if(0 == pbuf->cnt)
return NULL;
printk("%s(%d): buf cnt %d, buffers:\\n", __func__, __LINE__, pbuf->cnt);
for (i = 0; i < pbuf->cnt; i++)
printk(" src: va 0x%08x, pa 0x%08x; dst: va 0x%08x, pa 0x%08x\\n",
pbuf->item[i].src_va, pbuf->item[i].src_pa, pbuf->item[i].dst_va, pbuf->item[i].dst_pa);
return pbuf;
}
void deinit_buf(buf_group *pbuf)
{
int i;
if (!pbuf)
return;
for (i = 0; i < pbuf->cnt; i++) {
dma_free_coherent(NULL, pbuf->item[i].size, (void *)pbuf->item[i].src_va, (dma_addr_t)pbuf->item[i].src_pa);
dma_free_coherent(NULL, pbuf->item[i].size, (void *)pbuf->item[i].dst_va, (dma_addr_t)pbuf->item[i].dst_pa);
}
kfree(pbuf);
}
int check_result(buf_group *pbuf)
{
int i, j;
if (!pbuf)
return -EINVAL;
for (i = 0; i < pbuf->cnt; i++) {
if(memcmp((void *)pbuf->item[i].src_va, (void *)pbuf->item[i].dst_va, pbuf->item[i].size)) {
printk("%s(%d) err: buffer %d memcmp failed!\\n", __func__, __LINE__, i);
printk(" src buffer: ");
for (j = 0; j < 16; j++)
printk("%d ", *((char *)pbuf->item[i].src_va + j));
printk("\\n");
printk(" dst buffer: ");
for (j = 0; j < 16; j++)
printk("%d ", *((char *)pbuf->item[i].dst_va + j));
printk("\\n");
return -EIO;
}
}
return 0;
}
int case_memcpy_single_chan(void)
{
struct sg_table src_sg_table, dst_sg_table;
struct dma_async_tx_descriptor *tx = NULL;
struct dma_slave_config config;
struct dma_chan *chan;
struct scatterlist *sg;
buf_group *buffers = NULL;
long timeout = 5 * HZ;
chan_info dma_info;
dma_cap_mask_t mask;
dma_cookie_t cookie;
int i, ret = -EINVAL;
buffers = init_buf();
if (!buffers) {
pr_err("%s(%d) err: init_buf failed!\\n", __func__, __LINE__);
return -EBUSY;
}
dma_cap_zero(mask);
dma_cap_set(DMA_SG, mask);
dma_cap_set(DMA_MEMCPY, mask);
chan = dma_request_channel(mask , NULL , NULL);
if (!chan) {
pr_err("%s(%d) err: dma_request_channel failed!\\n", __func__, __LINE__);
goto out1;
}
if (sg_alloc_table(&src_sg_table, buffers->cnt, GFP_KERNEL)) {
pr_err("%s(%d) err: alloc src sg_table failed!\\n", __func__, __LINE__);
goto out2;
}
if (sg_alloc_table(&dst_sg_table, buffers->cnt, GFP_KERNEL)) {
pr_err("%s(%d) err: alloc dst sg_table failed!\\n", __func__, __LINE__);
goto out3;
}
/* assign sg buf */
sg = src_sg_table.sgl;
for (i = 0; i < buffers->cnt; i++, sg = sg_next(sg)) {
sg_set_buf(sg, phys_to_virt(buffers->item[i].src_pa), buffers->item[i].size);
sg_dma_address(sg) = buffers->item[i].src_pa;
}
sg = dst_sg_table.sgl;
for (i = 0; i < buffers->cnt; i++, sg = sg_next(sg)) {
sg_set_buf(sg, phys_to_virt(buffers->item[i].dst_pa), buffers->item[i].size);
sg_dma_address(sg) = buffers->item[i].dst_pa;
}
config.direction = DMA_MEM_TO_MEM;
config.src_addr = 0; /* not used for memcpy */
config.dst_addr = 0;
config.src_addr_width = DMA_SLAVE_BUSWIDTH_4_BYTES;
config.dst_addr_width = DMA_SLAVE_BUSWIDTH_4_BYTES;
config.src_maxburst = 8;
config.dst_maxburst = 8;
config.slave_id = sunxi_slave_id(DRQDST_SDRAM, DRQSRC_SDRAM);
dmaengine_slave_config(chan , &config);
tx = chan->device->device_prep_dma_sg(chan, dst_sg_table.sgl, buffers->cnt,
src_sg_table.sgl, buffers->cnt, DMA_PREP_INTERRUPT | DMA_CTRL_ACK);
/* set callback */
dma_info.chan = chan;
init_waitqueue_head(&dma_info.dma_wq);
atomic_set(&dma_info.dma_done, 0);
tx->callback = __dma_callback;
tx->callback_param = &dma_info;
/* enqueue */
cookie = dmaengine_submit(tx);
/* start dma */
dma_async_issue_pending(chan);
/* wait transfer over */
ret = wait_event_interruptible_timeout(dma_info.dma_wq, atomic_read(&dma_info.dma_done)==1, timeout);
if (unlikely(-ERESTARTSYS == ret || 0 == ret)) {
pr_err("%s(%d) err: wait dma done failed!\\n", __func__, __LINE__);
goto out4;
}
ret = check_result(buffers);
out4:
sg_free_table(&src_sg_table);
out3:
sg_free_table(&dst_sg_table);
out2:
dma_release_channel(chan);
out1:
if (buffers)
deinit_buf(buffers);
if(ret)
printk("%s(%d) err: test failed!\\n", __func__, __LINE__);
else
printk("%s(%d): test success!\\n", __func__, __LINE__);
return ret;
}
int case_memcpy_multi_chan(void)
{
struct dma_async_tx_descriptor *tx = NULL;
struct dma_slave_config config;
chan_info dma_chanl[DMA_MAX_CHAN], *pchan_info;
int buf_left, cur_trans, start_index;
int i, ret = -EINVAL, chan_cnt = 0;
long timeout = 5 * HZ;
dma_cap_mask_t mask;
dma_cookie_t cookie;
buf_group *buffers = NULL;
buffers = init_buf();
if (!buffers) {
pr_err("%s(%d) err: init_buf failed!\\n", __func__, __LINE__);
return -EBUSY;
}
/* request channel */
dma_cap_zero(mask);
dma_cap_set(DMA_MEMCPY, mask);
for(i = 0; i < ARRAY_SIZE(dma_chanl); i++, chan_cnt++) {
if(chan_cnt == buffers->cnt) /* channel enough */
break;
pchan_info = &dma_chanl[i];
pchan_info->chan = dma_request_channel(mask , NULL , NULL);
if(!pchan_info->chan)
break;
init_waitqueue_head(&pchan_info->dma_wq);
atomic_set(&pchan_info->dma_done, 0);
}
buf_left = buffers->cnt;
again:
start_index = buffers->cnt - buf_left;
for(i = 0; i < chan_cnt; ) {
pchan_info = &dma_chanl[i];
config.direction = DMA_MEM_TO_MEM;
config.src_addr = 0; /* not used for memcpy */
config.dst_addr = 0;
config.src_addr_width = DMA_SLAVE_BUSWIDTH_4_BYTES;
config.dst_addr_width = DMA_SLAVE_BUSWIDTH_4_BYTES;
config.src_maxburst = 8;
config.dst_maxburst = 8;
config.slave_id = sunxi_slave_id(DRQDST_SDRAM, DRQSRC_SDRAM);
dmaengine_slave_config(pchan_info->chan, &config);
tx = pchan_info->chan->device->device_prep_dma_memcpy(pchan_info->chan,
buffers->item[start_index + i].dst_pa,
buffers->item[start_index + i].src_pa,
buffers->item[start_index + i].size,
DMA_PREP_INTERRUPT | DMA_CTRL_ACK);
tx->callback = __dma_callback;
tx->callback_param = pchan_info;
cookie = dmaengine_submit(tx);
if(++i == buf_left)
break;
}
cur_trans = i;
/* start dma */
for(i = 0; i < cur_trans; i++)
dma_async_issue_pending(dma_chanl[i].chan);
for(i = 0; i < cur_trans; i++) {
ret = wait_event_interruptible_timeout(dma_chanl[i].dma_wq, atomic_read(&dma_chanl[i].dma_done)==1, timeout);
if(unlikely(-ERESTARTSYS == ret || 0 == ret)) {
pr_err("%s(%d) err: wait dma done failed!\\n", __func__, __LINE__);
ret = -EIO;
goto end;
}
}
buf_left -= cur_trans;
if(buf_left)
goto again;
ret = check_result(buffers);
end:
for(i = 0; i < chan_cnt; i++)
dma_release_channel(dma_chanl[i].chan);
if (buffers)
deinit_buf(buffers);
if(ret)
printk("%s(%d) err: test failed!\\n", __func__, __LINE__);
else
printk("%s(%d): test success!\\n", __func__, __LINE__);
return ret;
}
static int dma_test_main(int id)
{
u32 uret = 0;
switch(id) {
case DTC_MEMCPY_SINGLE_CHAN:
uret = case_memcpy_single_chan();
break;
case DTC_MEMCPY_MULTI_CHAN:
uret = case_memcpy_multi_chan();
break;
default:
uret = __LINE__;
break;
}
if(0 == uret)
printk("%s: test success!\\n", __func__);
else
printk("%s: test failed!\\n", __func__);
return uret;
}
const char *case_name[] = {
"DTC_MEMCPY_SINGLE_CHAN",
"DTC_MEMCPY_MULTI_CHAN",
};
ssize_t test_store(struct class *class, struct class_attribute *attr,
const char *buf, size_t size)
{
int id = 0;
if(strict_strtoul(buf, 10, (long unsigned int *)&id)) {
pr_err("%s: invalid string %s\\n", __func__, buf);
return -EINVAL;
}
pr_info("%s: string %s, test case %s\\n", __func__, buf, case_name[id]);
if(0 != dma_test_main(id))
pr_err("%s: dma_test_main failed! id %d\\n", __func__, id);
else
pr_info("%s: dma_test_main success! id %d\\n", __func__, id);
return size;
}
ssize_t help_show(struct class *class, struct class_attribute *attr, char *buf)
{
ssize_t cnt = 0;
cnt += sprintf(buf + cnt, "usage: echo id > test\\n");
cnt += sprintf(buf + cnt, " id for case DTC_MEMCPY_SINGLE_CHAN is %d\\n", (int)DTC_MEMCPY_SINGLE_CHAN);
cnt += sprintf(buf + cnt, " id for case DTC_MEMCPY_MULTI_CHAN is %d\\n", (int)DTC_MEMCPY_MULTI_CHAN);
cnt += sprintf(buf + cnt, "case description:\\n");
cnt += sprintf(buf + cnt, " DTC_MEMCPY_SINGLE_CHAN: case for single channel\\n");
cnt += sprintf(buf + cnt, " DTC_MEMCPY_MULTI_CHAN: case for multi channel\\n");
return cnt;
}
static struct class_attribute dma_test_class_attrs[] = {
__ATTR(test, 0220, NULL, test_store), /* not 222, for CTS, other group cannot have write permission */
__ATTR(help, 0444, help_show, NULL),
__ATTR_NULL,
};
static struct class dma_test_class = {
.name = "sunxi_dma_test",
.owner = THIS_MODULE,
.class_attrs = dma_test_class_attrs,
};
static int __init sw_dma_test_init(void)
{
int status;
pr_info("%s enter\\n", __func__);
/* init dma wait queue */
__dma_test_init_waitqueue();
status = class_register(&dma_test_class);
if(status < 0)
pr_info("%s err, status %d\\n", __func__, status);
else
pr_info("%s success\\n", __func__);
return 0;
}
static void __exit sw_dma_test_exit(void)
{
pr_info("sw_dma_test_exit: enter\\n");
class_unregister(&dma_test_class);
}
module_init(sw_dma_test_init);
module_exit(sw_dma_test_exit);
MODULE_LICENSE ("GPL");
MODULE_AUTHOR ("liugang");
MODULE_DESCRIPTION ("sunxi dma test driver");
sunxi_dma_test.h
/*
* drivers/char/dma_test/sunxi_dma_test.h
*
* Copyright(c) 2013-2015 Allwinnertech Co., Ltd.
* http://www.allwinnertech.com
*
* Author: liugang <liugang@allwinnertech.com>
*
* sunxi dma test driver
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 2 of the License, or
* (at your option) any later version.
*/
#ifndef __SUNXI_DMA_TEST_H
#define __SUNXI_DMA_TEST_H
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/module.h>
#include <linux/types.h>
#include <linux/fcntl.h>
#include <linux/gfp.h>
#include <linux/interrupt.h>
#include <linux/init.h>
#include <linux/ioport.h>
#include <linux/in.h>
#include <linux/string.h>
#include <linux/delay.h>
#include <linux/errno.h>
#include <linux/netdevice.h>
#include <linux/etherdevice.h>
#include <linux/skbuff.h>
#include <linux/platform_device.h>
#include <linux/dma-mapping.h>
#include <linux/slab.h>
#include <asm/io.h>
#include <asm/pgtable.h>
#include <asm/dma.h>
#include <linux/kthread.h>
#include <linux/delay.h>
#include <asm/dma-mapping.h>
#include <linux/wait.h>
#include <linux/random.h>
#include <linux/dmaengine.h>
#include <linux/dma/sunxi-dma.h>
enum dma_test_case_e {
DTC_MEMCPY_SINGLE_CHAN,
DTC_MEMCPY_MULTI_CHAN,
DTC_MAX
};
extern wait_queue_head_t g_dtc_queue[];
extern atomic_t g_adma_done;
#define BUF_MAX_CNT 8
#define DMA_MAX_CHAN 6
typedef struct {
unsigned int src_va;
unsigned int src_pa;
unsigned int dst_va;
unsigned int dst_pa;
unsigned int size;
}buf_item;
typedef struct {
unsigned int cnt;
buf_item item[BUF_MAX_CNT];
}buf_group;
typedef struct {
struct dma_chan *chan; /* dma channel handle */
wait_queue_head_t dma_wq; /* wait dma transfer done */
atomic_t dma_done; /* dma done flag, used with dma_wq */
}chan_info;
#endif /* __SUNXI_DMA_TEST_H */
以上是关于全志H3平台DMA框架的主要内容,如果未能解决你的问题,请参考以下文章