从生产者消费者窥探线程同步(下)
Posted 丑旦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从生产者消费者窥探线程同步(下)相关的知识,希望对你有一定的参考价值。
欢迎转载,转载请注明出处。尊重他人的一丢丢努力,谢谢啦!
阅读本篇之前,如果你还没有看过从生产者消费者窥探线程同步(上)
,那不妨先戳一下,两篇一起嚼才更好呢。
上一篇分析了使用BlockQueue和synchronized来实现生产者消费者模式。这一篇来看一下其他的实现,闲言少叙。
(3)Lock实现
核心:Lock的用法中规中矩,有点类似于非静态同步方法,只是前者是对lock对象显式加锁,而后者是对当前对象隐式加锁。
我相信大多数人在第一次接触Lock锁的时候,内心都会有这样的疑惑:明明提供了lock就能实现加锁解锁,而这多出来的Condition是干鸡毛的?怎么用?适用场合是啥?
事实上,Java 5之所以提供了Condition接口(可通过Lock.newCondition()来产生),主要是用来解决线程间的通信问题,通过condition的signalAll()和await()方法可以很方便地实现线程间的“广播”或者“悄悄话”。咦那不对吖,用Lock自身的方法岂不更方便?何必又引进Condition呢?
很不幸的是,Lock只是接口,它并不是Object的子类,而这个接口里面也没有提供类似于wait()和notify()的方法。虽然Condition也是个接口,但人家里面提供了signalAll()和await()哇。想来它的这种设计,可能基于这样的考虑:让锁的实现更加细颗粒度,更加精准。
怎么理解呢?不妨先来看张图。
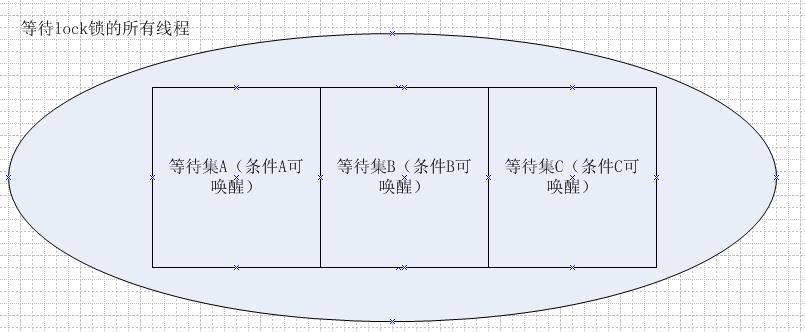
椭圆代表了等待lock锁的所有线程集合,而集合A、B和C则是执行不同任务的线程,此刻它们都在原地休整,等待任务的重新开始。
假设Lock里面提供了notify()方法,现在前一个线程执行完毕,Lock的notify()被调用了,它的方法受体是整个椭圆,接下来的场景就是椭圆内的所有线程立刻打了鸡血,原地复活,都去争夺唯一的一把锁,那可真是人仰马翻哭声震天,惨烈程度可想而知。并且很有可能出现的情况是,我只想让执行任务A的线程获取锁资源,偏偏被执行任务B的线程拿到了,然而B检查了一下发现自己并不具备运行的条件,那怎么办?只好放弃锁继续等待呗。这样的情况显然不是我们想看到的。
而Condition很好地处理了这个问题。现在仍然是椭圆里所有的线程都在等待,线程S在使用完锁资源之后,发现目前的条件适合A运行,那就调用A对应Condition实例的notify()方法,于是A内的线程开始躁动,然而B和C却是静悄悄的,就像不知道这回事一样。A中的小a拿到锁之后,离开就开始生产活动,小a在执行结束的时候,发现目前的条件适合B运行,于是她就不动声色地调用B对应Condition实例的notify()方法,然后自己又回去等待休息。B集合中的线程听到调动号令,自然要开始新一轮的争抢,无辜的C集合依然在漫长的等待,等待…
说了这么多,不妨通过代码来看一下。
public class StorageLock {
public static Integer MAX = 50;
public static List<Product> list = new ArrayList<>();
public static Lock lock = new ReentrantLock();
public static Condition notEmpty = lock.newCondition();
public static Condition notFull = lock.newCondition();
public static void main(String[] args) {
// TODO Auto-generated method stub
ExecutorService s = Executors.newCachedThreadPool();
for (int i = 0; i < 20; i++) {
s.submit(new Producer(10));
s.submit(new Consumer(5));
}
}
public static void produce(Integer num) {
lock.lock();
try {
while (list.size() + num > MAX) {
try {
System.out.println("数量过大,无法生产");
//队列太满了,生产的就先等一下吧,自动释放lock
notFull.await();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
for (int i = 0; i < num; i++) {
list.add(new Product(i, ""));
}
System.out.println("生产后,存储量为: " + list.size());
//生产后,队列里面有产品,消费的赶紧去消费吧。
notEmpty.signalAll();
} finally {
lock.unlock();
}
}
public static void consume(Integer num) {
lock.lock();
try {
while (list.size() < num) {
System.out.println("数量过大,无法消费");
try {
//消费的太多,没那么多货呃,那先等等吧,自动释放lock
notEmpty.await();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
for (int i = 0; i < num; i++) {
list.remove(0);
}
System.out.println("消费后,存储量为: " + list.size());
//消费完了,仓库里有空间,要生产的赶紧去生产吧
notFull.signalAll();
} finally {
lock.unlock();
}
}
}部分输出:
生产后,存储量为: 10
消费后,存储量为: 5
生产后,存储量为: 15
消费后,存储量为: 10
生产后,存储量为: 20
消费后,存储量为: 15
消费后,存储量为: 10
生产后,存储量为: 20
...
这里采用了两个条件notEmpty和notFull,来控制不同角色的线程,前者控制消费行为,后者控制生产行为。当然,你也可以只是用一个条件来控制,比如把程序换成这样:
public static void produce(Integer num) {
lock.lock();
try {
while (list.size() + num > MAX) {
try {
System.out.println("数量过大,无法生产");
notFull.await();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
for (int i = 0; i < num; i++) {
list.add(new Product(i, ""));
}
System.out.println("生产后,存储量为: " + list.size());
notFull.signalAll();
} finally {
lock.unlock();
}
}
public static void consume(Integer num) {
lock.lock();
try {
while (list.size() < num) {
System.out.println("数量过大,无法消费");
try {
notFull.await();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
for (int i = 0; i < num; i++) {
list.remove(0);
}
System.out.println("消费后,存储量为: " + list.size());
notFull.signalAll();
} finally {
lock.unlock();
}
}
部分输出:
生产后,存储量为: 10
生产后,存储量为: 20
消费后,存储量为: 15
消费后,存储量为: 10
消费后,存储量为: 5
消费后,存储量为: 0
数量过大,无法消费
...结果也完全没问题,只是每执行一次signalAll(),所有线程都来竞争锁资源,增加了锁获取的难度。
(4)不常用的PV实现
PV,高中同学的外号就叫PV,算一算毕业许久,还真有点想念他们呐。
相比于synchronized,信号量Semaphore和互斥量Mutex使用的就少多了。而他们的侧重点也有所不同。synchronized偏重对资源的直接控制。而Semaphore更像是控制访问资源的并发量,它基于CAS(compareAndSwap,一种非阻塞的同步手段)实现,支持公平和不公平机制。Mutex,多用在链表中的锁传递,且这个类不在java.util路径下暂且不提。
拿著名的厕所理论来说吧。假如有5个人要上厕所,厕所有3个坑位。
现在这5个人死脑筋,都要用靠近窗户风景好的那个1号坑,谁也不让谁,只好请synchronized来裁决,synchronized对1号坑位加了锁,你拿到钥匙就去,否则就干等着。
假如这5个人比较现实,都说无所谓用几号坑。但是坑位只有3个,不能全部都进去,也是谁都不让谁,只好请Semaphore来裁决,Semaphore决定发号牌,注意不是对坑位加锁,领到号牌的进去,没领到的干等着。至于进去之后的事,Semaphore就不管了。这个时候进去的A和B看见唯一的公共厕纸质量炒鸡好,都争着去抢,又发生了竟态,就导致另外一个同步问题了。
说了这么多,相信对他们的区别已经有所了解,如果不,请仔细体味后,再继续往下看。
public class StorageSemaphore {
public static Integer MAX = 50;
public static List<Product> list = new ArrayList<>();
// 公平锁,所谓的公平锁,就是讲究顺序,先申请先得。反之不公平锁,就是与大家机会均等,与顺序无关。
public static Semaphore semaphore = new Semaphore(3, true);
public static void main(String[] args) {
// TODO Auto-generated method stub
ExecutorService s = Executors.newCachedThreadPool();
for (int i = 0; i < 200; i++) {
s.submit(new Producer(10));
s.submit(new Consumer(5));
}
}
public static void produce(Integer num) {
try {
semaphore.acquire();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// synchronized (StorageSemaphore.class) {
while (list.size() + num < MAX) {
for (int i = 0; i < num; i++) {
list.add(new Product(i, ""));
}
System.out.println(Thread.currentThread().getName() + "\\t已经生产数:"
+ num + "\\t现仓储量为:" + list.size());
}
System.out.println("要生产的数量:" + num + "\\t库存量:" + list.size()
+ "\\t暂时不能执行生产任务!");
// }
semaphore.release();
}
public static void consume(Integer num) {
try {
semaphore.acquire();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// synchronized (StorageSemaphore.class) {
while (list.size() > num) {
for (int i = 0; i < num; i++) {
list.remove(0);
}
System.out.println(Thread.currentThread().getName() + "\\t已经消费数:"
+ num + "\\t现仓储量为:" + list.size());
}
System.out.println("要消费的数量:" + num + "\\t库存量:" + list.size()
+ "\\t暂时不能执行消费任务!");
// }
semaphore.release();
}
}
部分运行结果:
...
pool-1-thread-107 已经消费数:5 现仓储量为:35
pool-1-thread-108 已经消费数:5 现仓储量为:30
pool-1-thread-110 已经消费数:5 现仓储量为:36
pool-1-thread-111 已经生产数:10 现仓储量为:36
pool-1-thread-109 已经生产数:10 现仓储量为:46
pool-1-thread-112 已经消费数:5 现仓储量为:41
pool-1-thread-113 已经消费数:5 现仓储量为:36
pool-1-thread-115 已经生产数:10 现仓储量为:46
...敏感的同学可能已经注意到了,怎么出现36和41这样的数据呢,我们代码中无论生产和消费都是5的倍数呀(注意不同的机器上运行效果可能不一样,请多运行几次,肯定会有类似情况)。唯一的解释就是出现了内部争夺”厕纸”的情况。不妨把注释同步的部分去掉,再运行一下看看。
这次无论你运行多少次,输出都不会有异常的数据。那,完美了?
并没有。狂汗…
先来看个问题,前面我们已经分析过使用if()会导致的后果,而在这段程序里如果你使用if(),得到的效果其实是一样的。究其原因,这里的程序并没有使用拥塞控制策略,也就是说一个线程如果不满足生产条件,那么它将结束自己,而不是循环中等待条件合适后继续生产,所以也就没什么区别了。若有疑问的话,可以自己动手尝试验证。
除了加synchronized同步块之外,那就没有别的办法了?我们还有个互斥量Mutex没用呢。下面用binary semaphore来模拟一下。将上面代码的public static Semaphore semaphore = new Semaphore(3, true);修改为public static Semaphore semaphore = new Semaphore(1, true);,其他的都不用动,同步问题就解决了。
但问题到这里并没有结束,上面已经说过,程序里没有采用拥塞控制,虽然解决了同步,但它用的实际上是一种抛弃策略:想生产的不能保证都能生产到,该消费的也不保证都能消费到。这是它的弊端,但这并不影响它满足生产者消费者模式的6个条件(啥条件?忘记的话,请回到上一篇查看)。
如果你精力充沛,完全可以在synchronized里面添加对象的notify()和wait()操作(天呐,人生都如此艰难了,何必为难自己呐…),不过要注意多重锁极易造成死锁,倒不如放弃semaphore直接使用synchronized来得直接。
(5)总是被误用的volatile
volatile很诱人,也很容易被用错。关于它,你只要记住一句话:volatile能保证从主内存读取到最新的值,但它并不是线程安全的。
这里还是说一下,Java内存模型讨论的线程安全一般都是围绕这原子性、可见性、有序性这三个方面来考虑的(速记规则:”可有缘”)。
volatile的内存同步机制保证了可见性,本身的禁止指令重排语义保证了有序性,但致命的是,它保证不了原子性。
一般说来JVM提供的原子操作,只有8个,分别是lock、unlock、read、load、assign、use、store和write(速记规则”allrsuuw”)。
常用的synchronized三个条件统统满足,也是jvm比较倚重的锁实现方式。相比volatile来说,synchronized在字节码层面提供了monitorenter(lock)和monitorexit(unlock)操作,从而保证了操作的原子性。
回到我们的话题。
得,直接看代码吧。
public class StorageVolatile {
public static Integer MAX = 50;
public static volatile List<Product> list = new ArrayList<>();
public static void main(String[] args) {
// TODO Auto-generated method stub
ExecutorService s = Executors.newCachedThreadPool();
for (int i = 0; i < 200; i++) {
s.submit(new Producer(5));
s.submit(new Consumer(10));
}
}
public static void produce(Integer num) {
if (list.size() + num > MAX) {
System.out.println(Thread.currentThread().getName()
+ " 我是生产,我在等待... ");
} else {
for (int i = 0; i < num; i++) {
list.add(new Product(i, ""));
}
System.out.println(Thread.currentThread().getName() + " 库存: "
+ list.size());
}
}
public static void consume(Integer num) {
if (list.size() < num) {
System.out.println(Thread.currentThread().getName()
+ " 我是消费,我在等待... ");
} else {
for (int i = 0; i < num; i++) {
list.remove(i);
}
System.out.println(Thread.currentThread().getName() + " 库存: "
+ list.size());
}
}
}部分输出
pool-1-thread-1 库存: 5
pool-1-thread-1 库存: 10
pool-1-thread-1 库存: 15
pool-1-thread-1 库存: 20
pool-1-thread-1 库存: 10
pool-1-thread-1 库存: 10
pool-1-thread-1 库存: 12
pool-1-thread-1 库存: 12
pool-1-thread-1 库存: 17
pool-1-thread-4 我是消费,我在等待...
pool-1-thread-1 库存: 13
pool-1-thread-4 库存: 18从输出可以发现,我们的生产和消费都是5的倍数,结果却出现了12,17这样的“异类”,也印证了我们的分析。
要用它来实现生产者和消费者模式,就必须借助synchronized或者lock锁,那样的话实际上又回到前三种方案了,感兴趣的娃娃请自行尝试吧。
(6)温和而低调的ThreadLocal
从实现原理上说,ThreadLocal与生产者消费者模式根本就不搭界。把它放在此处说,算是探究线程同步的延伸。
如果说前面的synchronized、Lock,还是BlockQueue(内部也是Lock实现的)、semaphore等PV操作,甚至是volatile关键字,它们都是从或者试图从(volatile就不是安全的)资源的访问权限上(存在竟态)来处理线程同步问题,那ThreadLocal则提供了另外一种完全不同的思路:从资源本身下手消除竟态。
具体来说,就是ThreadLocal为每个线程都提供了一份单独的资源,维护在它的静态内部类ThreadLocalMap中,和平共处互不干扰。它的思路就是,你们不是吃不饱吗你们不是抢吗,来,我就给你们每个人各搞一份,这下都满足了吧,你们这群难伺候的程序,汗…
ThreadLocal类本身使用起来也很方便,主要是get()和set()操作。所以在遇到不需要保证资源一致性的并发场景时,使用ThreadLocal类不失为一种优雅的解决方案。
那它到底该怎么使用呢?不妨来看一下代码(与生产者消费者模式无关)。
public class StorageThreadLocal {
public static Integer MAX = 50;
public static List<Product> listInit = new ArrayList<Product>();
public static ThreadLocal<List<Product>> list = new ThreadLocal<List<Product>>() {
@Override
protected List<Product> initialValue() {
// TODO Auto-generated method stub
return new ArrayList<Product>();
}
};
public static void main(String[] args) {
// TODO Auto-generated method stub
ExecutorService s = Executors.newCachedThreadPool();
for (int i = 0; i < 20; i++) {
s.submit(new Producer(10));
s.submit(new Consumer(10));
}
}
public static void produce(Integer num) {
List<Product> listP = list.get();
while (listP.size() + num <= MAX) {
listP.add(new Product(1, ""));
System.out.println(Thread.currentThread().getName() + " 库存: "
+ listP.size());
}
list.set(listP);
}
public static void consume(Integer num) {
List<Product> listC = list.get();
while (listC.size() < num) {
listC.remove(0); System.out.println(Thread.currentThread().getName() + " 库存: "
+ listC.size());
}
list.set(listC);
}
}部分输出:
pool-1-thread-1 库存: 1
pool-1-thread-1 库存: 2
pool-1-thread-1 库存: 3
pool-1-thread-1 库存: 4
pool-1-thread-1 库存: 5
pool-1-thread-1 库存: 6
pool-1-thread-1 库存: 7
pool-1-thread-1 库存: 8
pool-1-thread-3 库存: 1
pool-1-thread-3 库存: 2
pool-1-thread-3 库存: 3
pool-1-thread-2 库存: 1
pool-1-thread-2 库存: 2
pool-1-thread-2 库存: 3
pool-1-thread-2 库存: 4
pool-1-thread-2 库存: 5
pool-1-thread-2 库存: 6
pool-1-thread-2 库存: 7
pool-1-thread-2 库存: 8
pool-1-thread-2 库存: 9
pool-1-thread-2 库存: 10
pool-1-thread-2 库存: 11
pool-1-thread-2 库存: 12
pool-1-thread-2 库存: 13
...很明显,各个线程都有自己队列,大家互不干涉内政,和和气气,愉快生产,再也没有脸红耳赤的尴尬场面了…
总结:
常见的线程同步方案大概就这几种吧,而它们也分别代表了文章开头说的线程同步的三种实现方式,阻塞方式(synchronized、java.util.concurrent包中提供的各种集合(Lock同步))、非阻塞方式(Lock的内部实现)和本身就是安全的代码(ThreadLocal)。各有各的应用特点和应用场景,总的来说,synchronized的效率要高于Lock,毕竟是JVM原生的,但也是应用最广泛最泛滥的;而ThreadLocal的实现机理与前两者都不同,不好直接做比较。
回到生产者和消费者模式上,虽然文中给了四种实现方式,但PV操作的实现必须借助synchronized,所以还是要以前三种为主。
一窥之见,难免疏漏,有不到或待商榷之处,还请来往诸君在留言区热心提出,热烈讨论,热情补充,大家一块学习一起进步,何尝不是人生一乐事呢。
以上是关于从生产者消费者窥探线程同步(下)的主要内容,如果未能解决你的问题,请参考以下文章