Java提取网站后台数据进行处理并排名
Posted nanner
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java提取网站后台数据进行处理并排名相关的知识,希望对你有一定的参考价值。
Java提取网站后台数据进行处理并排名
一、网页分析
截取的网站链接为:https://www.tiobe.com/tiobe-index/
打开网站后,可以看到这个网站的编程语言排名情况。我们选择下图中的图表,这个图表中有2001-2019年的编程语言每个月的使用率,我需要它的数据。
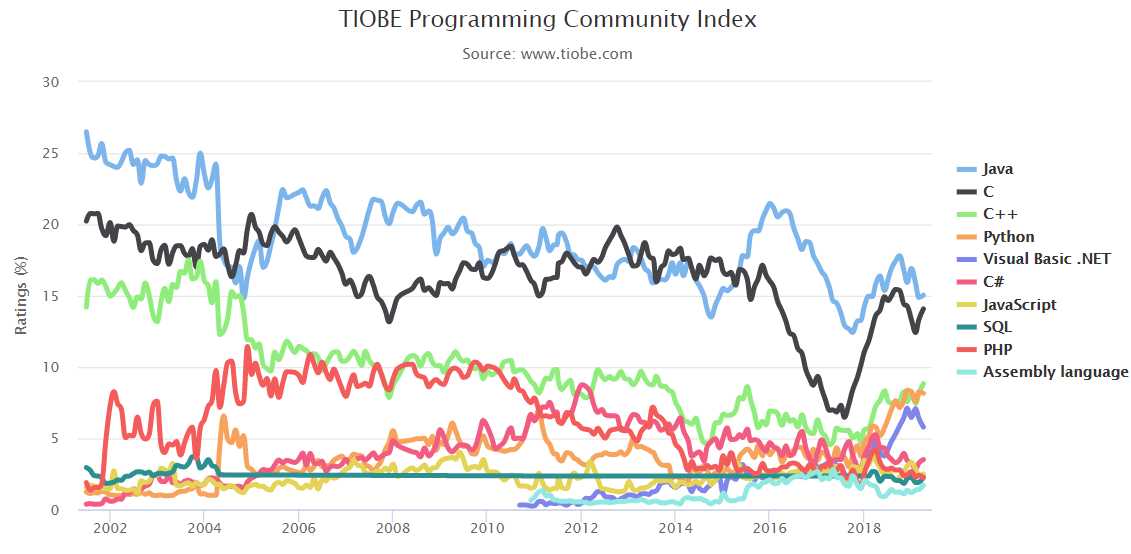
二、数据提取
在网页点右键,点击查看源码:首先我们要编程把源码下载到记事本里,看一下核心代码
1 URL url = new URL(website); 2 // 根据链接(字符串格式),生成一个URL对象 3 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); 4 // 打开URL 5 BufferedReader reader =new 6 BufferedReader(new InputStreamReader(urlConnection.getInputStream(), encoding)); 7 // 得到输入流 8 Save.saveStr("",file,false); 9 //清空记事本文件的内容 10 while ((str = reader.readLine())!= null) { 11 //每次读取一行,放入记事本中 12 Save.saveStr(str,file,true); 13 Save.saveStr("\\r\\n",file,true); 14 }
下载完成后,我们打开这个文件,看一看这个文件里的内容,只截取一部分
三、数据处理
首先找到我们需要的数据(对应上图的排名的数据),利用正则表达式将数据提取出来。
上图是对应的数据,现在利用正则表达式来提取核心代码如下:
1 //正则表达式要匹配的数据 2 Pattern dataCompile = Pattern.compile("Date.UTC[(]\\\\d{4}, \\\\d{1,2}, \\\\d{1,2}[)],\\\\d{1,2}.\\\\d{3}|name : ‘\\\\w++(\\\\W{0,2})? ( \\\\w++)(\\\\w++)?‘,data"); 3 String s; 4 try { 5 //读入后放入记事本文档中 6 System.out.println("处理数据中......"); 7 Save.saveStr("",file,false); 8 while ((s = in.readLine())!=null){ 9 Matcher dataNeed = dataCompile.matcher(s); 10 while (dataNeed.find()){ 11 Save.saveStr(dataNeed.group(),file,true); 12 Save.saveStr("\\r\\n",file,true); 13 }catch (Exception e){ 14 e.printStackTrace(); 15 }
处理完成后,打开保存的文件,可以看到一下结果,这里仍然只截取一小部分。
这个数据中有时间和使用率,这些是我绘图所需要的,这里依然使用正则表达式将他们全部读取出来放入一个类中。
看一下这个类的核心代码
1 public class Data{ 2 3 private String language; //存放语言名称 4 5 private double data; //存放使用率 6 7 private String month; //存放月 8 9 //省略字段的属性 10 }
用这个类来存放数据,用着则表达式来提取文本中的数据,将数据放在这个类实例化的对象中。分别存放这个语言的名字和某一个时间的排名,每一个对象存放一个数据,提取后把这些对象放进10行12列的数组中。然后根据数据的大小进行排序,比如我绘制2002年的数据,排好序了之后的情况如图
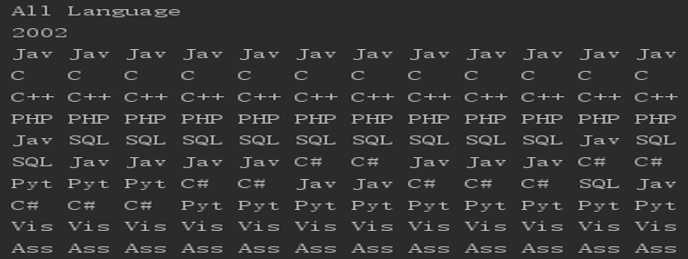
这是对应的使用率
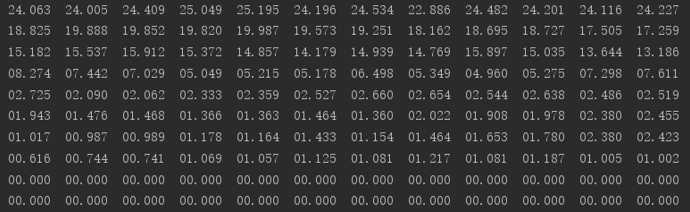
0代表这个时间的数据缺失,由于网站数据的问题,会缺少某一时间的数据,这里设置了一个循环标记,用标记来匹配正则表达式匹配到的月份,如果两个结果不相等则代表这个月数据缺失,当发现数据缺失的时候,会自动为这个月的使用率补0。
另外有看到有两个jav,其实下面的jav是javascript语言,我只截取了名字的三个长度,方便清楚的看到排名情况。这里简单的解释一下。
主窗口的设计省略,在选择不同的信息时会出现不同控件。
下面说绘图,绘图在Java的JPanel中绘图。我们要想自由绘图,就需要重写JPanel类中的public void paintComponent(Graphics g)方法然后调用g.drawLine()函数,对排好序的数据进行绘制。图形是根据他们在某一时间固定的排名进行绘制的。
四、程序运行结果
算法实现后首先来看一下运行结果,我还是绘制2002年的排名结果,以便更好对应上图中的排名情况。横轴是月份,竖轴是排名,看效果。
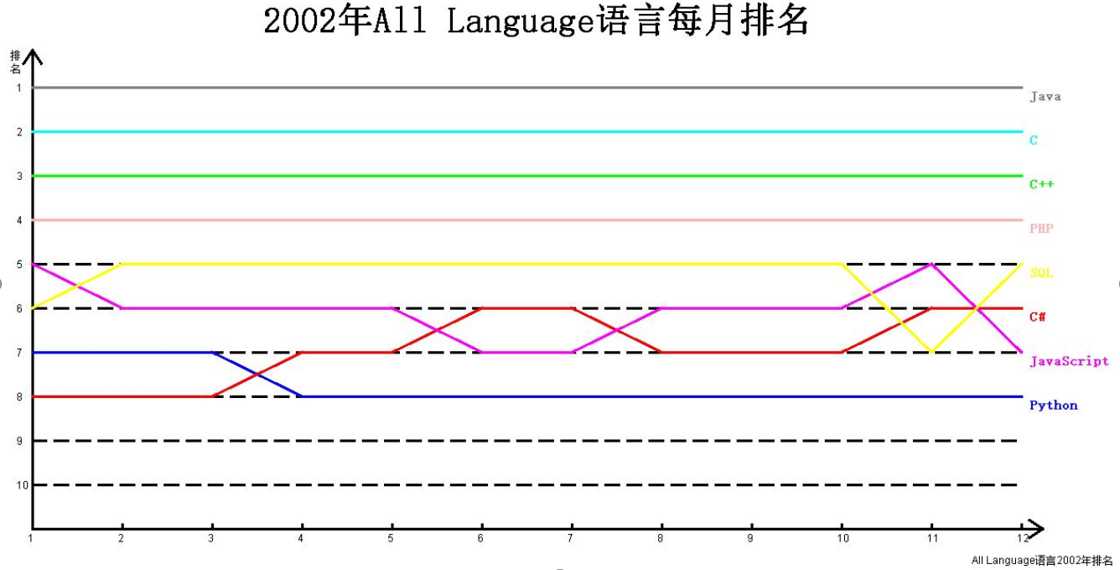
x轴以月为单位时,可以绘制2001 – 2019 年的数据,某一时刻缺少数据时,可以自动跳过。
x轴以年为单位时,可以绘制2001 – 2019 年每一年年平均使用率排名或者每一年每一个月的排名情况。
首先来看2001-2019年年平均使用率情况

这个是数组里的使用率数据。
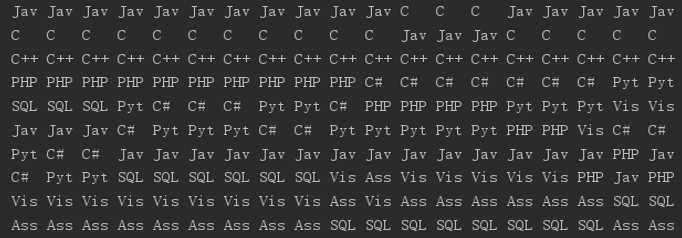
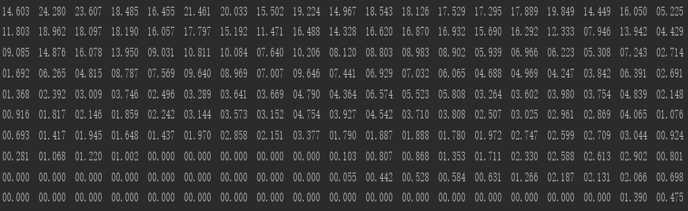
看一下具体某个月份的排名情况
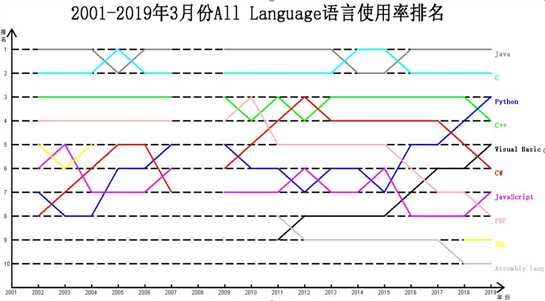
有一些数据空缺是因为某一年的3月份没有数据,我们把排名情况的数据截图下来,可以看到,2001、2008年这两年3月的数据都是0,上文已经说过,0代表数据缺少。
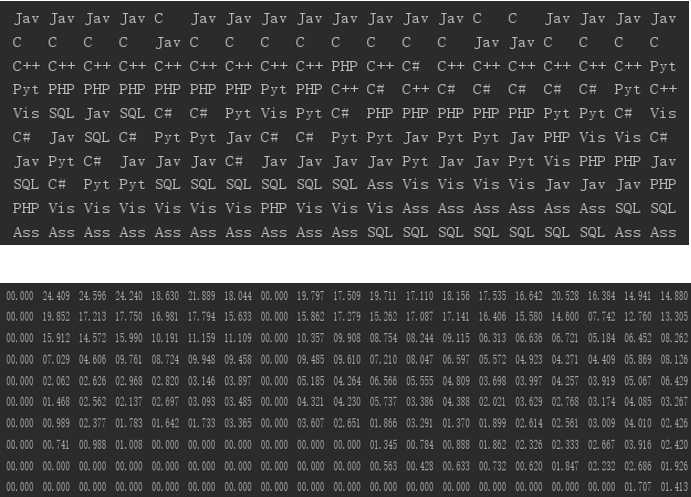
可以看到,上图中没有绘制数据的的时间的使用率均为0。
五、实现保存功能
当点击保存按钮时可以把自己绘制的图形保存至计算机中,首先来看核心代码:
1 //文件选择框,点击确定时,返回选择文件的路径。 2 public static String fileSave(Component parent,String name) { 3 JFileChooser fileChooser = new JFileChooser(); 4 fileChooser.setSelectedFile(new File(name)); 5 int result = fileChooser.showSaveDialog(parent); 6 if (result == JFileChooser.APPROVE_OPTION) { 7 File file = fileChooser.getSelectedFile(); 8 return file.getAbsolutePath(); 9 } 10 else 11 return null; 12 }
这部分的是实现文件保存,但是我们需要路径,所以用JfileChooser类来选择路径,选择好路径并且完成命名后返回路径的字符串给上部分代码中的file,考虑到重名问题,做了一些处理,比如我要保存名字为"hello.jpg"的文件,当文件存在时,会自动保存为"hello1.jpg"。
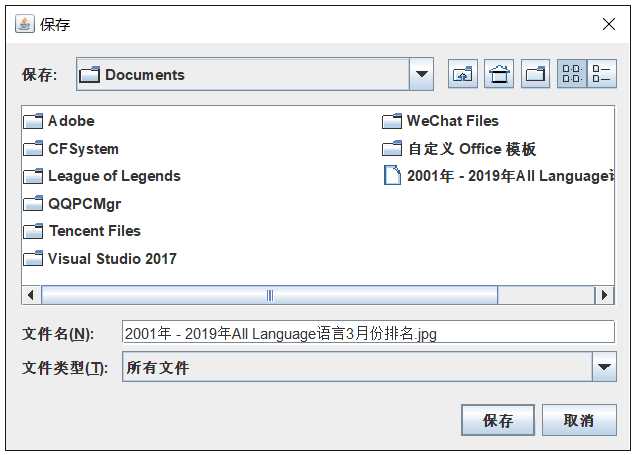
来看一下保存的结果。
![]()
打开它
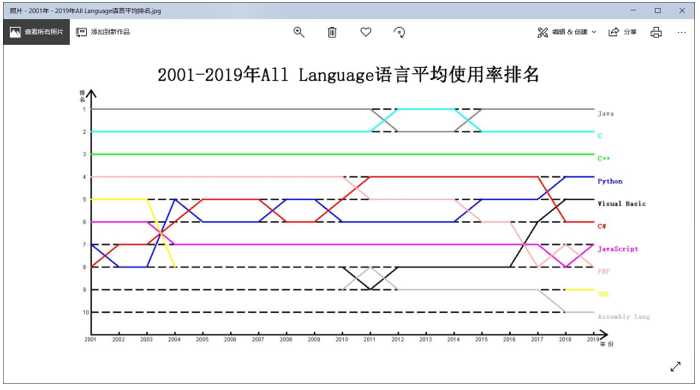
完成。
源代码连接为:https://github.com/LiangMengnan/Data-statistics
以上是关于Java提取网站后台数据进行处理并排名的主要内容,如果未能解决你的问题,请参考以下文章