Hive架构倾斜优化sql及常见问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive架构倾斜优化sql及常见问题相关的知识,希望对你有一定的参考价值。
Hive架构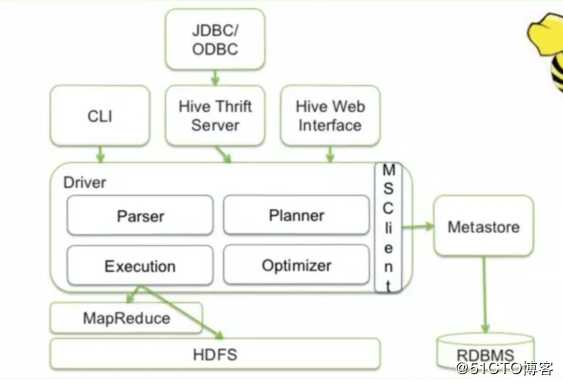
hive架构如图所示,client跟driver交互,通过parser、planner、optimizer,最后转为mapreduce运行,具体步骤如下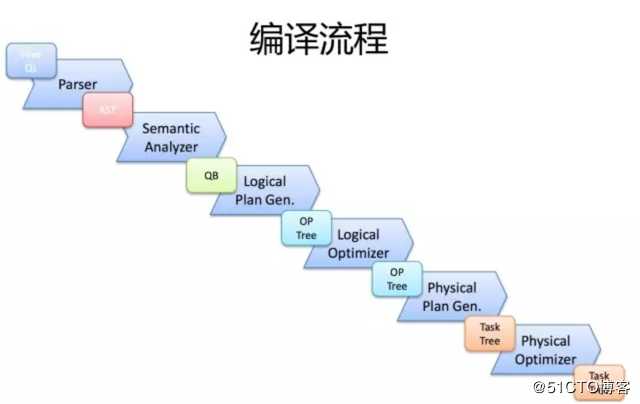
- driver输入一条sql,会由parser转为抽象语法树AST,这个是没有任务元数据信息的语法树;
- 语法分析器再把AST转为一个一个的QueryBlock,一个QueryBlock包含输入、输出、计算逻辑,也就是说一个子程序就是QueryBlock
- planner遍历所有的QueryBlock,转为一个个的Operator(算子,比如tablescanOperator),最后形成OperatorTree;
- 优化器对OperatorTree进行优化,包含谓词下推、剪枝等;
- 然后遍历OperatorTree,分割成多个mapreduce作业,形成物理计划
- 之后进行物理优化,比如是否进行map join等
Hive 数据倾斜优化
- 对于group by可以有两个优化点
map聚合:set hive.map.aggr=true,会在map端对相同key先聚合一下;
分发为两道作业:set hive.groupby.skewindata=true,会对原来的一道作业分为两道作业,第一道随机分配key,第二道再按key分配
注意:对于部分聚合函数有用,比如sum和count,但是完全聚合函数无用,比如avg - 对于join也有两个优化点
map join:新版hive中默认开启set hive.auto.convert.join=true ,join的左表如果足够小,会直接把左表内容加载到内存中
两道作业:set hive.optimize.skewjoin = true;set hive.skewjoin.key = skew_key_threshold (default = 100000)这个两道作业跟groupby不一样,这个是说把超过10万行的数据单独启一道map join,最后再把结果聚合
hive常见问题
- hive不支持非等值join
错误:select from a inner join b on a.id<>b.id
替代方法:select from a inner join b on a.id=b.id and a.id is null; - hive不支持非join连接
错误:select from dual a,dual b where a.key = b.key;
正确:select from dual a join dual b on a.key = b.key; - hive不支持or
错误:select from a inner join b on a.id=b.id or a.name=b.name
替代方法:select from a inner join b on a.id=b.id union all select * from a inner join b on a.name=b.name - hive内部表和外部表的区别
创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径, 不对数据的位置做任何改变。
删除表时:在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据 - sortby、orderby、distributeby
order by会引发全局排序;会导致所有的数据集中在一台reducer节点上,然后进行排序,这样很可能会超过单个节点的磁盘和内存存储能力导致任务失败。
distribute by + sort by就是该替代方案,被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。
以上是关于Hive架构倾斜优化sql及常见问题的主要内容,如果未能解决你的问题,请参考以下文章