linux中的文件处理grepsedawk
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux中的文件处理grepsedawk相关的知识,希望对你有一定的参考价值。
1.grepgrep [options] pattern [file…]
options:表示选项
pattern:要匹配的模式。
file:表示一系列的文件名
选项:
-c 只输出匹配行的计数
-i 不区分大小写(用于单字符)
-n 显示匹配的行号
-v 不显示不包含匹配文本的所以有行
-s 不显示错误信息
-E 使用扩展正则表达式
grep -c 关键字 文件名 ##显示出现的关键字的行数
grep -n 关键字 文件名 ##显示该关键字的行
grep -n2 关键字 文件名 ##显示该关键字行的上下各两行
grep -A2 关键字 文件名 ##显示后两行
grep -B2 关键字 文件名 ##显示前两行

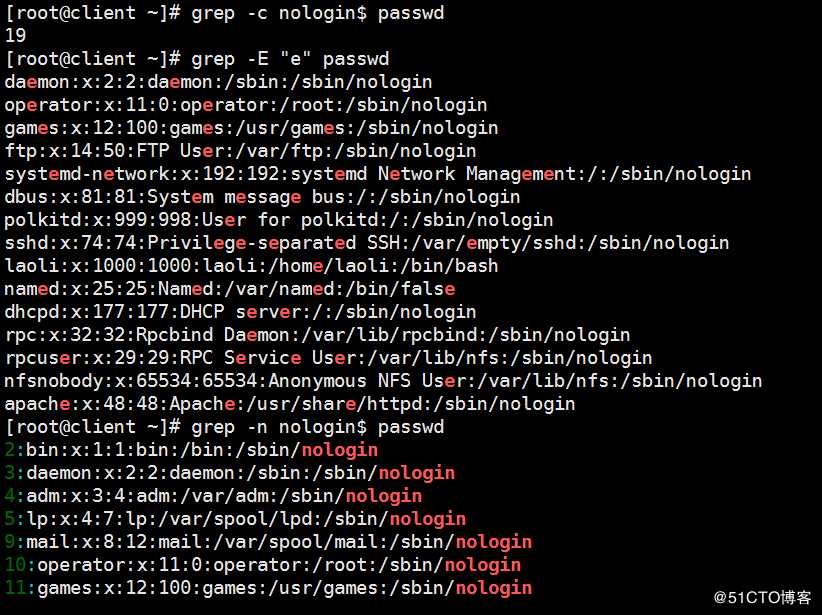
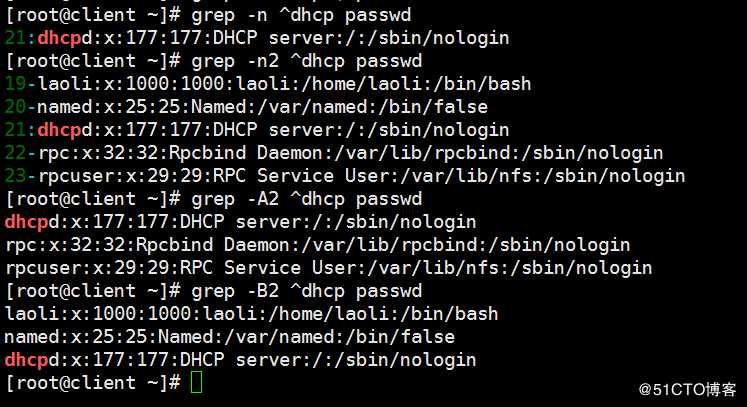
扩展的(Extend)正则表达式(注意要使用扩展的正则表达式要加-E选项,或者直接使用egrep):
匹配字符:这部分和基本正则表达式一样
- 字符出现 [0-任意次 ]
\? 字符出现 [ 0-1次 ]
+ 字符出现 [ 1-任意次]
{n} 字符出现 [ n次 ]
{m,n} 字符出现 [ 最少出现m次,最多出现n次]
{0,n} 字符出现 [ 0-n次]
{m,} 字符出现 [ 至少m次]
(xy){n}xy 关键字出现[n次]
.* 关键字之间匹配任意字
3.grep中的正则表达式
^hello ##以hello开头
hello$ ##以hello结尾
‘h....o‘ ##‘h开头,o结尾,中间4个字符‘
‘h.....‘ ##‘h开头,后面5个字符‘
‘.....o‘ ##‘o结尾,前面5个字符‘
- sed
stream editor:用来操作的纯ASC||码的文本,处理时把当前行存入临时缓冲区,成为模式空间,可以指定仅仅处理哪些行,sed符合条件的处理。不符合条件的不处理。
sed命令格式:
sed [options] ‘command‘ files
sed [options] -f scriptfile files ##用指定文件做sed命令
sed对字符处理:
p 显示
d 删除
a 添加
c 替换
w 写入
i 插入
p模式操作:
sed -n ‘/#/p‘ fstab 显示有#行的内容
sed -n ‘/#/!p‘ fstab 除了#的行都显示
sed -n ‘/^#/!p‘ fstab 除了#开头的行都显示
sed -n ‘/^#/p‘ fstab 显示#开头的行
sed -n ‘/#$/p‘ fstab 显示#结尾的行
sed -n ‘/^UUID/p‘ fstab 显示UUID开头的行
sed -n ‘/^UUID/!p‘ fstab 除了UUID开头的行都显示
sed -n ‘2,6p‘ fstab 显示第2行到第6行的内容
sed ‘2,6!p‘ fstab 除了2-6行都显示
d模式操作:
sed ‘/^UUID/d‘ fstab 除UUID开头的行的内容
sed ‘/^UUID/!d‘ fstab 删除除UUID开头外的行的内容
sed ‘/^$/d‘ fstab 删除空行
sed ‘3,8d‘ fstab ##删除3-8行,不显示,但文件本身并无变化
a模式操作:
sed ‘/^UUID/a\hello sed\n westos‘ fstab ##在UUID的最后一行中加入hello sed 换行 westos
c模式操作:
sed ‘/^UUID/c\hello‘ fstab ##将UUID开头的内容换为hello
i模式操作:
sed ‘/^UUID/i\hello sed\n westos‘ fstab ##将UUID开头的内容之前加入hello sed 换行 westos
w模式操作:
sed ‘/^#/w /mnt/testfile‘ fstab ##将fstab中以#为开头的行整合到/mnt/testfile中
sed -n ‘/^#/w /mnt/testfile‘ fstab ##不显示
sed ‘6r/mnt/linux‘ fstab ##将/mnt/linux中的所有内容整合到fstab的第六行中
c模式操作 :
sed ‘/^#/chello\nlinux‘ fstab ##将#开头的行的内容用‘hello\nlinux’替换
sed的其他用法:
sed ‘G‘ passwd ##每打印一行同时打印空行
sed ‘$!G‘ passwd ##最后一行不随后打印空行
sed ‘=‘ passwd ##打印每一行之前先打印行号,第二行打印内容
sed ‘=‘ passwd |sed ‘N;s/\n/ /‘ ##将换行换成空格
sed -n ‘$p‘ data ##显示最后一行
awk
awk ‘{print NR}‘ passwd ##打印每行行号
awk -F : ‘{print NF}‘ passwd ##打印每行有几列
awk -F : ‘{print $1,$2}‘ passwd ##打印第1列与第二列,空格连接
awk -F : ‘{print $1":"$2}‘ passwd ##打印第1列与第2列,二者用:连接
awk -F : ‘BEGIN{print "name passwd"}{print $1":"$2}END{print "end"}‘ passwd
##第一行前加入字符name passwd 最后一行字符加入end
awk -F : ‘BEGIN{print "name passwd"}/bash$/{print $1":"$2}END{print "end"}‘ passwd ##结果是以bash结尾的行
awk -F : ‘BEGIN{n=0}/bash$/{n++}END{print n}‘ passwd ##对以bash结尾的行进行计数
awk -F : ‘BEGIN{n=0}{n++}END{print n}‘ passwd ##对passwd有几行进行计数
使用一条命令抓取ifconfig返回的ip:
ifconfig ens33|awk ‘/inet\>/{print $2}‘
先使用awk ‘/inet‘ 抓取以inet开头的一行,然后打印其中的第二列
以上是关于linux中的文件处理grepsedawk的主要内容,如果未能解决你的问题,请参考以下文章