linux⑧ mysql数据库,redis 数据库
Posted lw1095950124
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux⑧ mysql数据库,redis 数据库相关的知识,希望对你有一定的参考价值。
目录
- 一. mysql 数据库
- 二.redis 数据库
- 三.redis 发布/订阅
- 四. redis 数据持久化
- 五. redis 主从同步
- 六.redis-cluster 集群搭建
一. mysql 数据库
1.安装方式
①yum安装
②源代码编译安装
③rpm包安装

yum安装的前提条件,是准备好yum源,可以选择163源,清华源,阿里云源,等等等
1.安装mariadb的yum源有俩,一个是阿里云的yum源,可能版本较低,并且软件包很小,功能很少
yum install mariadb-server mariadb -y
二个是mariadb官方的yum源 ,配置方式是什么?就是如何定制yum源?
方法:在/etc/yum.repos.d目录下,建立一个repo文件就是yum仓库
创建一个 mariadb.repo文件,写入如下内容
[mariadb]
name = MariaDB
baseurl = http://yum.mariadb.org/10.1/centos7-amd64
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck=1
2.安装mariadb,查看官方的版本号,和软件包信息
systemctl start mariadb #启动mariadb数据库
3.在安装好mysql之后,进行初始化
mysql_secure_installation
4.进行mysql数据库编码统一,修改/etc/my.cnf配置如下
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci
log-error=/var/log/mysqld.log
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# Settings user and group are ignored when systemd is used.
# If you need to run mysqld under a different user or group,
# customize your systemd unit file for mariadb according to the
# instructions in http://fedoraproject.org/wiki/Systemd
[mysqld_safe]
log-error=/var/log/mariadb/mariadb.log
pid-file=/var/run/mariadb/mariadb.pid
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
2.授权mysql进行远程登录
#授予 所有权限 在 所有的库下的所有的表 对 root 用户 以及所有的主机,设置远程登录的密码 111111 grant all privileges on *.* to [email protected]"%" identified by "111111"; #立即刷新权限表 flush privileges;
3.主从复制
主从复制技术,保证了,数据库的读写分离,并发性更好, 并且保障数据安全,防止单点数据库故障数据丢失
①环境准备
环境准备,准备2台服务器,安装好2个数据库 192.168.226.128 是主库 192.168.226.130 是从库
②主库配置
1.主库配置
编辑主库的/etc/my.cnf 写入如下配置
[mysqld]
server-id=1
log-bin=s18mysql-bin
2.该了配置文件,重启数据库
systemctl restart mariadb
3.创建一个用于远程复制数据的账户
create user ‘yazhou‘@‘%‘ identified by ‘yazhouhao‘;
4.授予yazhou这个账号,从库的身份
grant replication slave on *.* to ‘yazhou‘@‘%‘;
5。锁住主库,防止数据写入,影响实验
flush table with read lock;
6.导出当前所有的数据,发送给从库
mysqldump -uroot -p --all-databases > /opt/all.sql
7.发送这个数据给从库
scp /opt/all.sql [email protected]:/opt/
8.查看主库的binlog状态
9.进行解锁
unlock table;
③从库配置
查看slave从库的配置如下:
1.修改从库的配置文件/etc/my.cnf
写入如下配置
server-id=10
2.导入主库的数据库
#导入数据的第一种方式
mysql -uroot -p < /opt/all.sql
#导入数据的第二种方式
先登录mysql
然后
MariaDB [s18utf8]> source /opt/all.sql;
3.此时主从数据库已经在同一个起始点了,开始数据同步
这是一段sql,在mysql中执行的
change master to master_host=‘192.168.226.128‘,
master_user=‘yazhou‘,
master_password=‘yazhouhao‘,
master_log_file=‘s18mysql-bin.000001‘,
master_log_pos=709;
4.开启从库同步(在mysql中输入的命令)
start slave ;
5.检测是否主从成功 ,
show slave status\\G
检查这2个参数
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
6.此时已经可以在主库写入数据,从库实时写入了
7.配置mysql主从复制,读写分离
修改从库的/etc/my.cnf 添加只读参数
read-only=true
8.在主库上创建一个普通用户,在从库上进行登录,查看是否可以读写数据库
create user "ywy"@"%" identified by "ywyacd";
9.给这个普通用户查看数据库的权限
grant select on *.* to [email protected]"%" ;
二.redis 数据库
1.介绍
Redis 是一个开源(BSD许可)的, 内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件
redis是c语言编写的,支持数据持久化,是key-value类型数据库。
应用在缓存,队列系统中
redis支持数据备份,也就是master-slave模式
redis官方声称1秒钟可以执行10万个命令 redis为什么这么快,
1是完全基于内存的数据库 2.redis是完全用c写的单线程的数据库 世界上用redis数据库集群最多的公司,新浪微博 ,新浪微博的评论数,点赞数,转发数,都是存在于redis中 redis-cluster
2.安装
(yum, 编译,rpm)
编译安装: 1.下载redis源代码 wget http://download.redis.io/releases/redis-4.0.10.tar.gz 2.解压缩,进行编译安装 tar -zxf redis-4.0.10.tar.gz cd redis-4.0.10.tar.gz #进行编译且安装 make && make install 最终生成redis可执行命令,默认放在了/usr/local/bin 3.默认redis装好后在 /usr/local/bin/ 目录下 4.更改redis的配置文件,启动redis,支持密码,和更改端口方式 touch redis.s18.conf 内容如下 (s18luffy) [[email protected] redis-4.0.10]# cat redis.s18.conf bind 192.168.226.128 #redis启动地址 protected-mode yes #开启redis安全模式 port 6800 #更改redis端口 daemonize yes #redis后台启动 pidfile /var/run/redis_6379.pid loglevel notice logfile "" requirepass haohaio #设置redis的密码 5.登录redis客户端 redis-cli -h 192.168.226.128 -p 6800 参数解释 -h 指定主机地址 -p 指定redis端口 登录之后通过auth指令 验证密码 使用ping命令,确保redis正常可用回复了一个pong
3.基本命令
keys * 查看所有key type key 查看key类型 expire key seconds 过期时间 ttl key 查看key过期剩余时间 -2表示key已经不存在了 persist 取消key的过期时间 -1表示key存在,没有过期时间 exists key 判断key存在 存在返回1 否则0 del keys 删除key 可以删除多个 dbsize 计算key的数量
4.数据类型
redis是一种高级的key:value存储系统,其中value支持五种数据类型
字符串(strings) 散列(hashes) 列表(lists) 集合(sets) 有序集合(sorted sets)
① strings类型
set 设置key get 获取key append 追加string mset 设置多个键值对 mget 获取多个键值对 del 删除key incr 递增+1 decr 递减-1
127.0.0.1:6379> set name ‘yu‘ #设置key OK 127.0.0.1:6379> get name #获取value "yu" 127.0.0.1:6379> set name ‘yuchao‘ #覆盖key OK 127.0.0.1:6379> get name #获取value "yuchao" 127.0.0.1:6379> append name ‘ dsb‘ #追加key的string (integer) 10 127.0.0.1:6379> get name #获取value "yuchao dsb" 127.0.0.1:6379> mset user1 ‘alex‘ user2 ‘xiaopeiqi‘ #设置多个键值对 OK 127.0.0.1:6379> get user1 #获取value "alex" 127.0.0.1:6379> get user2 #获取value "xiaopeiqi" 127.0.0.1:6379> keys * #找到所有key 1) "user2" 2) "name" 3) "user1" 127.0.0.1:6379> mget user1 user2 name #获取多个value 1) "alex" 2) "xiaopeiqi" 3) "yuchao dsb" 127.0.0.1:6379> del name #删除key (integer) 1 127.0.0.1:6379> get name #获取不存在的value,为nil (nil) 127.0.0.1:6379> set num 10 #string类型实际上不仅仅包括字符串类型,还包括整型,浮点型。
redis可对整个字符串或字符串一部分进行操作,而对于整型/浮点型可进行自增、自减操作。 OK 127.0.0.1:6379> get num "10" 127.0.0.1:6379> incr num #给num string 加一 INCR 命令将字符串值解析成整型,将其加一,
最后将结果保存为新的字符串值,可以用作计数器 (integer) 11 127.0.0.1:6379> get num "11" 127.0.0.1:6379> decr num #递减1 (integer) 10 127.0.0.1:6379> decr num #递减1 (integer) 9 127.0.0.1:6379> get num "9"
②list类型
lpush 从列表左边插 rpush 从列表右边插 lrange 获取一定长度的元素 lrange key start stop ltrim 截取一定长度列表 lpop 删除最左边一个元素 rpop 删除最右边一个元素 lpushx/rpushx key存在则添加值,不存在不处理
lpush duilie ‘alex‘ ‘peiqi‘ ‘ritian‘ #新建一个duilie,从左边放入三个元素 llen duilie #查看duilie长度 lrange duilie 0 -1 #查看duilie所有元素 rpush duilie ‘chaoge‘ #从右边插入chaoge lpushx duilie2 ‘dsb‘ #key存在则添加 dsb元素,key不存在则不作处理 ltrim duilie 0 2 #截取队列的值,从索引0取到2,删除其余的元素 lpop #删除左边的第一个 rpop #删除右边的第一个
③ sets 集合类型
redis的集合,是一种无序的集合,集合中的元素没有先后顺序。
1 sadd/srem 添加/删除 元素 2 sismember 判断是否为set的一个元素 3 smembers 返回集合所有的成员 4 sdiff 返回一个集合和其他集合的差异 5 sinter 返回几个集合的交集 6 sunion 返回几个集合的并集
sadd zoo wupeiqi yuanhao #添加集合,有三个元素,不加引号就当做字符串处理 smembers zoo #查看集合zoo成员 srem zoo wupeiqi #删除zoo里面的alex sismember zoo wupeiqi #返回改是否是zoo的成员信息,不存在返回0,存在返回1 sadd zoo wupeiqi #再把wupeiqi加入zoo smembers zoo #查看zoo成员 sadd zoo2 wupeiqi mjj #添加新集合zoo2 sdiff zoo zoo2 #找出集合zoo中有的,而zoo2中没有的元素 sdiff zoo2 zoo #找出zoo2中有,而zoo没有的元素 sinter zoo zoo1 #找出zoo和zoo1的交集,都有的元素 sunion zoo zoo1 #找出zoo和zoo1的并集,所有的不重复的元素
④有序集合
都是以z开头的命令
用来保存需要排序的数据,例如排行榜,成绩,工资等。
1.排序
排序学生的成绩(添加) 127.0.0.1:6379> ZADD mid_test 70 "alex" (integer) 1 127.0.0.1:6379> ZADD mid_test 80 "wusir" (integer) 1 127.0.0.1:6379> ZADD mid_test 99 "yuyu"
排行榜,zreverange 倒叙 zrange正序 127.0.0.1:6379> ZREVRANGE mid_test 0 -1 withscores 1) "yuyu" 2) "99" 3) "wusir" 4) "80" 5) "xiaofneg" 6) "75" 7) "alex" 8) "70" 127.0.0.1:6379> ZRANGE mid_test 0 -1 withscores 1) "alex" 2) "70" 3) "xiaofneg" 4) "75" 5) "wusir" 6) "80" 7) "yuyu" 8) "99"
2.移除
移除有序集合mid_test中的成员,xiaofeng给移除掉 127.0.0.1:6379> ZREM mid_test xiaofneg (integer) 1 127.0.0.1:6379> ZRANGE mid_test 0 -1 withscores 1) "alex" 2) "70" 3) "wusir" 4) "80" 5) "yuyu" 6) "99"
3.集合总数
返回有序集合mid_test的基数 127.0.0.1:6379> ZCARD mid_test (integer) 3
4.某个成员的值
返回成员的score值 127.0.0.1:6379> ZSCORE mid_test alex "70"
5, 成员的排名
zrank返回有序集合中,成员的排名。默认按score,从小到大排序。 127.0.0.1:6379> ZRANGE mid_test 0 -1 withscores 1) "alex" 2) "70" 3) "wusir" 4) "80" 5) "yuyu" 6) "99" 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> ZRANK mid_test wusir (integer) 1 127.0.0.1:6379> ZRANK mid_test yuyu (integer) 2
⑤ 哈希数据结构
哈希结构就是 k1 -> k1 : v1 如同字典 套字典 { k1 : { k2: v2 } } ,取出v2 必须 k1,取出k2
hashes即哈希。哈希是从redis-2.0.0版本之后才有的数据结构。
hashes存的是字符串和字符串值之间的映射,比如一个用户要存储其全名、姓氏、年龄等等,就很适合使用哈希。
1 hset 设置散列值 2 hget 获取散列值 3 hmset 设置多对散列值 4 hmget 获取多对散列值 5 hsetnx 如果散列已经存在,则不设置(防止覆盖key) 6 hkeys 返回所有keys 7 hvals 返回所有values 8 hlen 返回散列包含域(field)的数量 9 hdel 删除散列指定的域(field) 10 hexists 判断是否存在
redis hash是一个string类型的field和value的映射表 语法 hset key field value hset news1 title "first news title" #设置第一条新闻 news的id为1,添加数据title的值是"first news title" hset news1 content "news content" #添加一个conntent内容 hget news1 title #获取news:1的标题 hget news1 content #获取news的内容 hmget news1 title content #获取多对news:1的 值 hmset news2 title "second news title" content "second Contents2" #设置第二条新闻news:2 多个field hmget news2 title content #获取news:2的多个值 hkeys news1 #获取新闻news:1的所有key hvals news1 #获取新闻news:1的所有值 hlen news1 #获取新闻news:1的长度 hdel news1 title #删除新闻news:1的title hlen news1 #看下新闻news:1的长度 hexists news1 title #判断新闻1中是否有title,不存在返回0,存在返回1
三.redis 发布/订阅
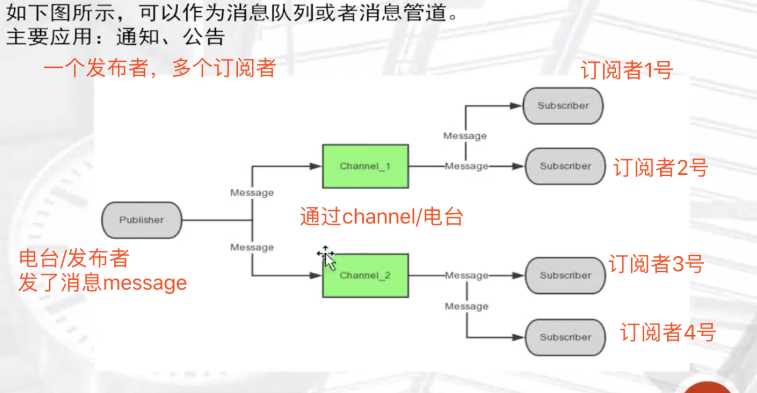
①常用命令
PUBLISH channel msg
将信息 message 发送到指定的频道 channel
SUBSCRIBE channel [channel ...]
订阅频道,可以同时订阅多个频道
UNSUBSCRIBE [channel ...]
取消订阅指定的频道, 如果不指定频道,则会取消订阅所有频道
PSUBSCRIBE pattern [pattern ...]
订阅一个或多个符合给定模式的频道,每个模式以 * 作为匹配符,比如 it* 匹配所
有以 it 开头的频道( it.news 、 it.blog 、 it.tweets 等等), news.* 匹配所有
以 news. 开头的频道( news.it 、 news.global.today 等等),诸如此类
PUNSUBSCRIBE [pattern [pattern ...]]
退订指定的规则, 如果没有参数则会退订所有规则
PUBSUB subcommand [argument [argument ...]]
查看订阅与发布系统状态
注意:使用发布订阅模式实现的消息队列,当有客户端订阅channel后只能收到后续发布到该频道的消息,
之前发送的不会缓存,必须Provider和Consumer同时在线。
②实例
窗口1, 订阅 wang* 频道的,redis-cli启动窗口
127.0.0.1:6379> PSUBSCRIBE wang* Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "wang*" 3) (integer) 1 1) "pmessage" 2) "wang*" 3) "wangbaoqiang" 4) "jintian zhennanshou "
窗口2,也订阅了 wang*频道,redis-cli启动窗口
127.0.0.1:6379> PSUBSCRIBE wang* Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "wang*" 3) (integer) 1 1) "pmessage" 2) "wang*" 3) "wangbaoqiang" 4) "jintian zhennanshou "
窗口3,发布者向频道发布消息
[[email protected] ~]# redis-cli 127.0.0.1:6379> PUBLISH wangbaoqiang "jintian zhennanshou " (integer) 2
四. redis 数据持久化
当进程挂掉,或者机器挂掉,只要内存数据被释放,redis的数据,默认是会丢的
1.rdb持久化模式
rdb持久化模式,是基于内存数据快照的方式,通过save指令,
强制快照数据到本地,存储为一个二进制文件
1.开启rdb功能,需要修改redis-rdb.conf
内容如下
daemonize yes
port 6379
logfile /data/6379/redis.log
dir /data/6379
dbfilename dbmp.rdb
bind 127.0.0.1
save 900 1
save 300 10
save 60 10000
2.开启redis服务端,支持rdb功能
redis-server redis-rdb.conf
3.登录redis,写入数据,手动执行save触发持久化,会生成一个二进制的数据文件 dbmp.rdb
2. aof 持久化模式
将修改类的redis命令,记录到一个日志中,以保证数据不丢 ,
下次重启,再执行这个文件,数据就回来了
1.开启aof的方式,修改redis-aof.conf配置如下 daemonize yes port 6379 logfile /data/6379/redis.log dir /data/6379 appendonly yes appendfsync everysec 2.指定aof配置文件启动 redis-server redis-aof.conf
3. 切换rdb 持久化 到 aof 持久化
1.准备一个支持rdb的数据库 ,启动rdb方式的redis,准备一个新的配置文件,支持rdb redis-new-rdb.conf daemonize yes port 6379 logfile /opt/6379/redis.log dir /opt/6379 dbfilename dbmp.rdb save 900 1 save 300 10 save 60 10000 2.通过命令切换为aof模式,仅仅是临时生效,切换到aof,切换后还得修改配置文件 127.0.0.1:6379> CONFIG set appendonly yes #开启AOF功能 OK 127.0.0.1:6379> CONFIG SET save "" #关闭RDB功能 OK 3.还得修改redis的配置文件,让他下次重启也是aof 修改redis-new-rdb.conf 为如下配置,以后重启也是aof了 daemonize yes port 6379 logfile /opt/6379/redis.log dir /opt/6379 appendonly yes appendfsync everysec 重启redis数据库
4.至此redis已经切换到 aof模式下了
五. redis 主从同步
1.手动版
1.redis是支持多实例的数据库 在一台机器上,可以运行多个隔离的数据库环境
实现多实例就是准备多个配置文件
准备3个配置文件,实现 一主两从的 redis数据库架构
准备3个配置文件,仅仅是端口的区分就行
-rw-r--r-- 1 root root 154 4月 4 15:20 redis-6379.conf
port 6379
daemonize yes
pidfile /data/6379/redis.pid
loglevel notice
logfile "/data/6379/redis.log"
dbfilename dump.rdb
dir /data/6379
protected-mode no
-rw-r--r-- 1 root root 154 4月 4 15:21 redis-6380.conf
port 6380
daemonize yes
pidfile /data/6380/redis.pid
loglevel notice
logfile "/data/6380/redis.log"
dbfilename dump.rdb
dir /data/6380
protected-mode no
slaveof 127.0.0.1 6379
-rw-r--r-- 1 root root 154 4月 4 15:21 redis-6381.conf
port 6381
daemonize yes
pidfile /data/6381/redis.pid
loglevel notice
logfile "/data/6381/redis.log"
dbfilename dump.rdb
dir /data/6381
protected-mode no
slaveof 127.0.0.1 6379
2. 分别启动三个redis数据库实例
redis-server redis-6379.conf
redis-server redis-6380.conf
redis-server redis-6381.conf
3. 查看三个数据库的身份信息,检测主从状态
#通过命令查看数据库身份信息
127.0.0.1:6379> info Replication
4. 测试写入主库 6379数据,查看两个从库的信息,确认6380和6381同步6379数据即为正常
5. 演示干掉主库,手动切换主从故障
1.手动检查进程,杀死主库,演示故障
2.手动切换某一个从库,去掉它的slave身份,
就是redis-cli -p 6380 登录6380后,输入 slaveof on one 去掉自己的slave身份
3.将6381从新指引到6380为从库
redis-cli -p 6381 登录 6381数据库
然后slaveof 127.0.0.1 6380
2.自动版(哨兵功能)
sentinel主要功能如下: 1. 不时的监控redis是否良好运行,如果节点不可达就会对节点进行下线标识
2. 如果被标识的是主节点,sentinel就会和其他的sentinel节点“协商”,
如果其他节点也人为主节点不可达,就会选举一个sentinel节点来完成自动故障转义
3. 在master-slave进行切换后,master_redis.conf、slave_redis.conf
和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,
sentinel.conf的监控目标会随之调换
官网地址:http://redisdoc.com/ redis-cli info #查看redis数据库信息 redis-cli info replication #查看redis的复制授权信息 redis-cli info sentinel #查看redis的哨兵信息
1.环境配置 准备3个redis数据库实例 准备3个配置文件 redis-6379.conf port 6379 daemonize yes logfile "6379.log" dbfilename "dump-6379.rdb" dir "/var/redis/data/" redis-6380.conf port 6380 daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/var/redis/data/" slaveof 127.0.0.1 6379 // 从属主节点 redis-6381.conf port 6381 daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/var/redis/data/" slaveof 127.0.0.1 6379 // 从属主节点 2. 分别启动三个redis数据库实例 [[email protected] s18msredis]# redis-server redis-6379.conf [[email protected] s18msredis]# redis-server redis-6380.conf [[email protected] s18msredis]# redis-server redis-6381.conf 3. 检测它们的身份信息 1158 redis-cli -p 6381 info replication 1159 redis-cli -p 6380 info replication 1160 redis-cli -p 6379 info replication 4. 此时再准备三个哨兵,就是三个值班的,检测redis主从状态 三个哨兵配置文件如下 redis-26379.conf port 26379 dir /var/redis/data/ logfile "26379.log" // 当前Sentinel节点监控 127.0.0.1:6379 这个主节点 // 2代表判断主节点失败至少需要2个Sentinel节点节点同意,少数服从多数 // s18ms是主节点的别名 sentinel monitor s18ms 127.0.0.1 6379 2 //每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过30000毫秒30s且没有回复,则判定不可达 sentinel down-after-milliseconds s18ms 30000 //当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点, 原来的从节点会向新的主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为1 sentinel parallel-syncs s18ms 1 //故障转移超时时间为180000毫秒 sentinel failover-timeout s18ms 180000 daemonize yes redis-26380.conf 配置信息仅仅和26379端口的不同 redis-26381.conf 配置信息仅仅和26379端口的不同 5. 分别启动三个哨兵 [[email protected] s18msredis]# redis-sentinel redis-26379.conf [[email protected] s18msredis]# redis-sentinel redis-26380.conf [[email protected] s18msredis]# redis-sentinel redis-26381.conf 6. 查看哨兵的身份信息 [[email protected] s18msredis]# redis-cli -p 26379 info sentinel # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=s18ms,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3 此时哨兵配置已经正确,三个哨兵,检测着一主两从 7. 自动主从故障切换演练 1.干掉6379,查看6380和6381的身份信息 2.正确的是 哨兵会选举6380为新的master,然后6381为6380的新salve 3.当6379重新复活之后,哨兵会自动的,添加到主从架构中
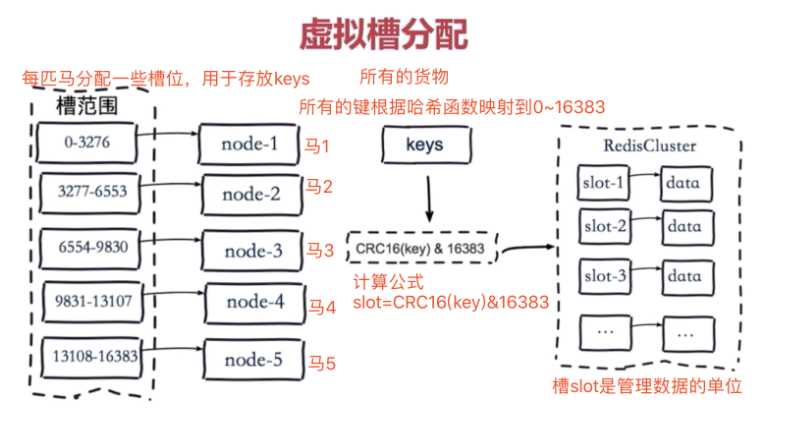
六.redis-cluster 集群搭建
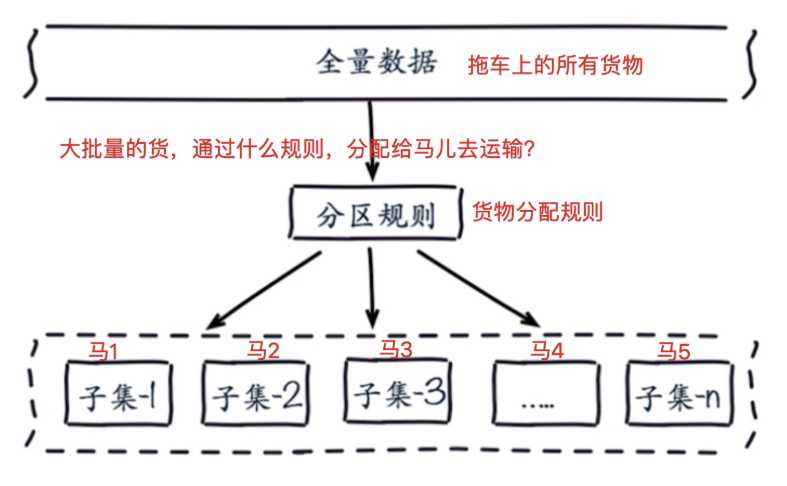
Redis Cluster采用虚拟槽分区 虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有的数据映射到一个固定范围内的整数集合,整数定义为槽(slot)。 Redis Cluster槽的范围是0 ~ 16383。 槽是集群内数据管理和迁移的基本单位。采用大范围的槽的主要目的是为了方便数据的拆分和集群的扩展, 每个节点负责一定数量的槽。
1.环境准备,准备6个节点(6匹马儿),指的就是启动6个redis数据库实例 这个6个配置文件仅仅就是端口的不同 redis-7000.conf port 7000 daemonize yes dir "/opt/redis/data" logfile "7000.log" dbfilename "dump-7000.rdb" cluster-enabled yes cluster-config-file nodes-7000.conf cluster-require-full-coverage no #以下5个配置文件,仅仅是端口的不同 redis-7001.conf redis-7002.conf redis-7003.conf redis-7004.conf redis-7005.conf 2. 分别启动6个redis数据库实例 [[email protected] s18cluster]# redis-server redis-7000.conf [[email protected] s18cluster]# redis-server redis-7001.conf [[email protected] s18cluster]# redis-server redis-7002.conf [[email protected] s18cluster]# redis-server redis-7003.conf [[email protected] s18cluster]# redis-server redis-7004.conf [[email protected] s18cluster]# redis-server redis-7005.conf 3. 检查redis集群状态 #进行redis-cluster集群槽位的分配 #redis官方提供了ruby语言的脚本,进行自动的槽位分配 perl python ruby 都是脚本语言 4. 安装准备ruby语言的环境,用于自动化创建redis集群 wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz #解压缩ruby源码包 cd ruby-2.3.1/ #进入ruby源码包,进行编译且安装 ./configure --prefix=/opt/ruby/ make && make install #当ruby编译安装完成后 配置PATH可以快捷使用ruby 5. 通过ruby的软件包管理工具安装redis模块(gem就是类似于python的pip工具) wget http://rubygems.org/downloads/redis-3.3.0.gem #通过gem安装这个redis包 gem install -l redis-3.3.0.gem 6. 找到ruby创建redis集群的脚本工具 [[email protected] s18cluster]# find /opt -name redis-trib.rb /opt/redis-4.0.10/src/redis-trib.rb 7. 此时就可以通过ruby来创建redis的集群工具了,进行槽位分配 /opt/redis-4.0.10/src/redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 8. 此时redis集群已经ok redis-cli -p 7000 -c #-c 开启集群模式 9. 当你在不同的节点中,创建redis的key,只要redis的key经过了重定向,分配到不同的节点中,代表集群搭建ok
工作原理: redis客户端任意访问一个redis实例,如果数据不在该实例中,通过重定向引导客户端访问所需要的redis实例
以上是关于linux⑧ mysql数据库,redis 数据库的主要内容,如果未能解决你的问题,请参考以下文章