Spark任务提交方式和执行流程
Posted xiaoenduke
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark任务提交方式和执行流程相关的知识,希望对你有一定的参考价值。
转自:http://www.cnblogs.com/frankdeng/p/9301485.html
一、Spark中的基本概念
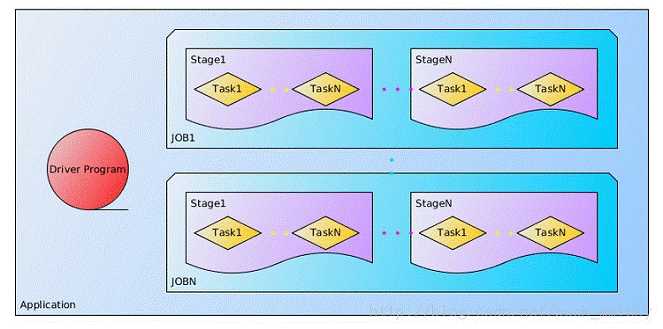
(1)Application:表示你的应用程序
(2)Driver:表示main()函数,创建SparkContext。由SparkContext负责与ClusterManager通信,进行资源的申请,任务的分配和监控等。程序执行完毕后关闭SparkContext
(3)Executor:某个Application运行在Worker节点上的一个进程,该进程负责运行某些task,并且负责将数据存在内存或者磁盘上。在Spark on Yarn模式下,其进程名称为 CoarseGrainedExecutor Backend,一个CoarseGrainedExecutor Backend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task,这样,每个CoarseGrainedExecutorBackend能并行运行Task的数据就取决于分配给它的CPU的个数。
(4)Worker:集群中可以运行Application代码的节点。在Standalone模式中指的是通过slave文件配置的worker节点,在Spark on Yarn模式中指的就是NodeManager节点。
(5)Task:在Executor进程中执行任务的工作单元,多个Task组成一个Stage
(6)Job:包含多个Task组成的并行计算,是由Action行为触发的
(7)Stage:每个Job会被拆分很多组Task,作为一个TaskSet,其名称为Stage
(8)DAGScheduler:根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler,其划分Stage的依据是RDD之间的依赖关系
(9)TaskScheduler:将TaskSet提交给Worker(集群)运行,每个Executor运行什么Task就是在此处分配的。
以上是关于Spark任务提交方式和执行流程的主要内容,如果未能解决你的问题,请参考以下文章