7.编写mapreduce案例
Posted braveym
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7.编写mapreduce案例相关的知识,希望对你有一定的参考价值。
在写一个mapreduce类之前先添加依赖包
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.it19gong</groupId> <artifactId>testmaven</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>testmaven</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.mrunit</groupId> <artifactId>mrunit</artifactId> <version>1.1.0</version> <classifier>hadoop2</classifier> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-api</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-auth</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-minicluster</artifactId> <version>2.6.0</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>2.6.0</version> <scope>provided</scope> </dependency> </dependencies> </project>
新建一个WordCountMapper类
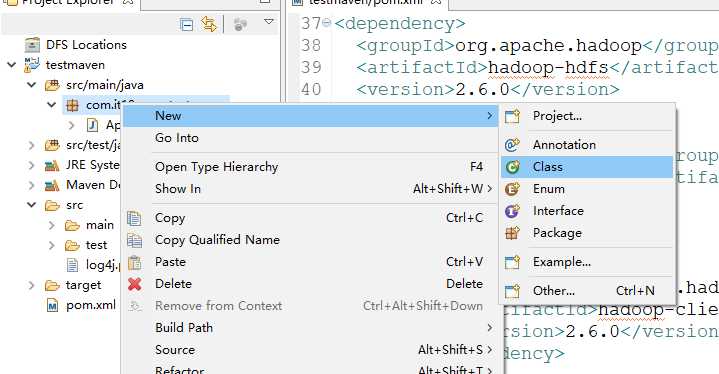
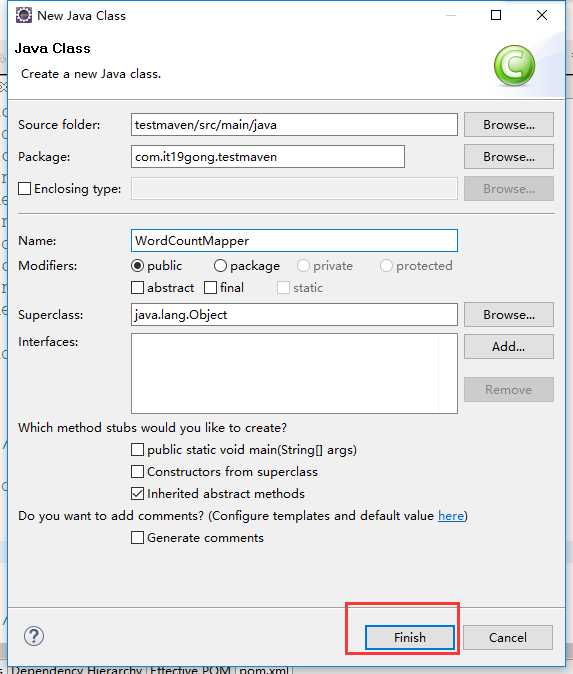
package com.it19gong.testmaven; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //拿到一行数据转换为string String line = value.toString(); //将这一行切分出各个单词 String[] words = line.split(" "); //遍历数组,输出<单词,1> for(String word:words) { context.write(new Text(word), new IntWritable(1)); } } }
定义WordCountReducer类
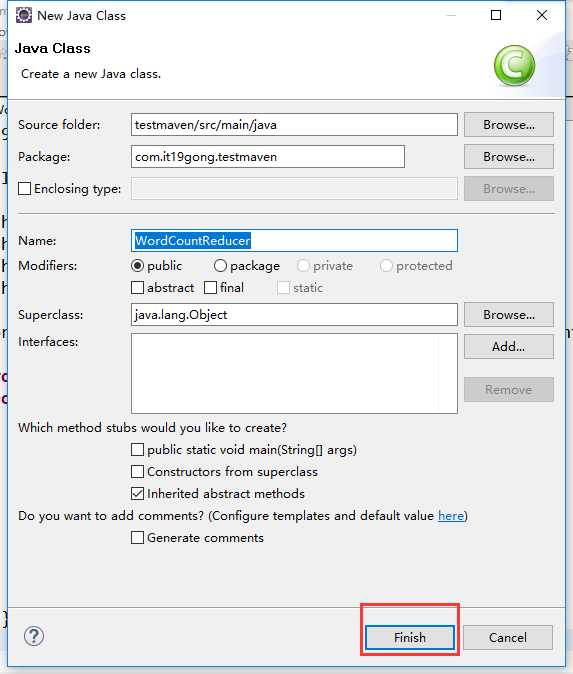
package com.it19gong.testmaven; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //定义一个计数器 int count = 0; //遍历这一组kv的所有v,累加到count中 for(IntWritable value:values){ count += value.get(); } context.write(key, new IntWritable(count)); } }
定义WordCountRunner类
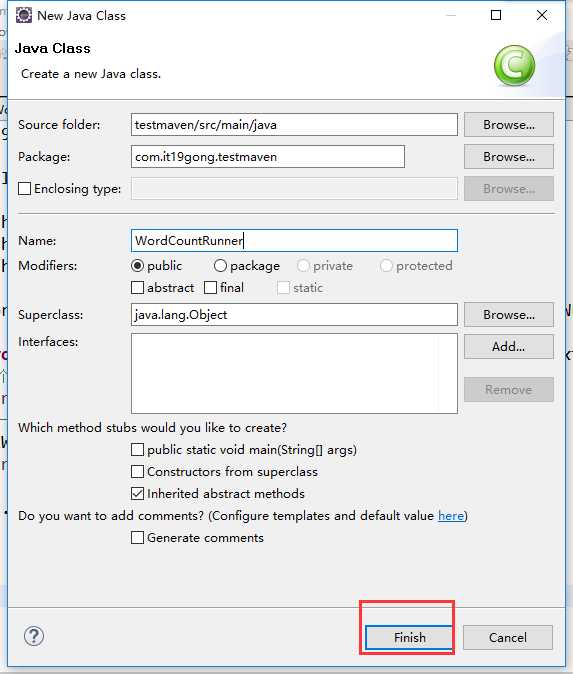
package com.it19gong.testmaven;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountRunner {
//把业务逻辑相关的信息(哪个是mapper,哪个是reducer,要处理的数据在哪里,输出的结果放哪里……)描述成一个job对象
//把这个描述好的job提交给集群去运行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
//指定我这个job所在的jar包
// wcjob.setJar("/home/hadoop/wordcount.jar");
wcjob.setJarByClass(WordCountRunner.class);
wcjob.setMapperClass(WordCountMapper.class);
wcjob.setReducerClass(WordCountReducer.class);
//设置我们的业务逻辑Mapper类的输出key和value的数据类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(IntWritable.class);
//设置我们的业务逻辑Reducer类的输出key和value的数据类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(IntWritable.class);
//指定要处理的数据所在的位置
// FileInputFormat.setInputPaths(wcjob, "hdfs://hdp-server01:9000/wordcount/data/big.txt");
FileInputFormat.setInputPaths(wcjob, new Path(args[0]));
//指定处理完成之后的结果所保存的位置
// FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://hdp-server01:9000/wordcount/output/"));
FileOutputFormat.setOutputPath(wcjob, new Path(args[1]));
//向yarn集群提交这个job
boolean res = wcjob.waitForCompletion(true);
System.exit(res?0:1);
}
}
打成架包
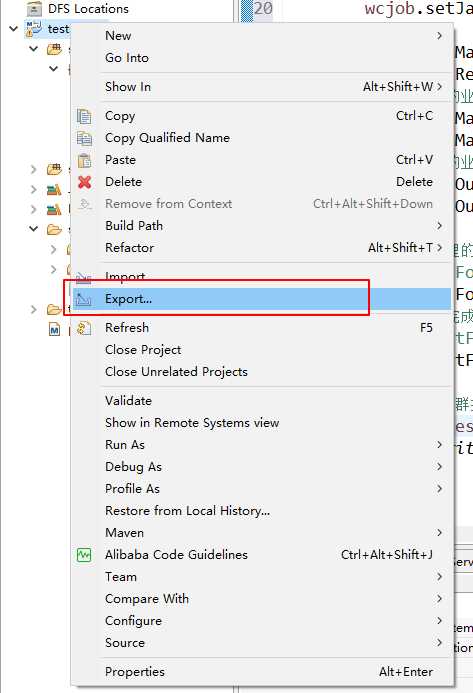
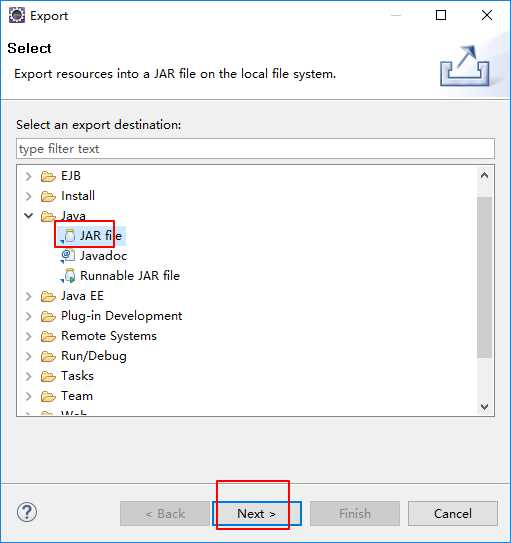
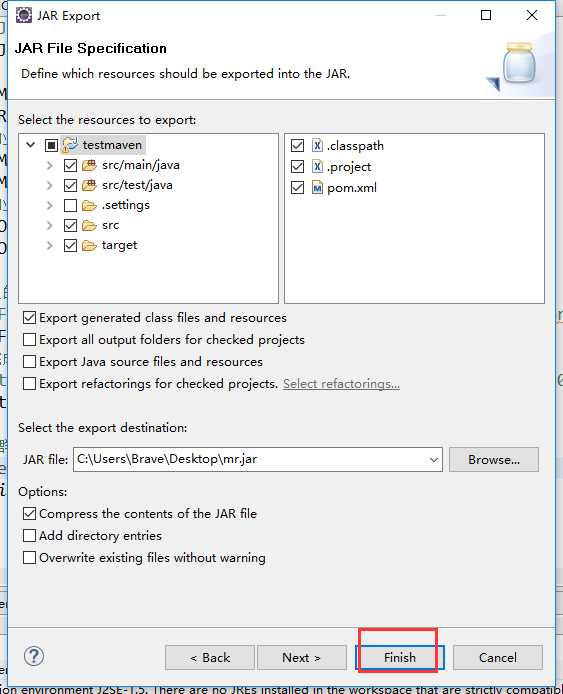
把打包好的架包上传到集群
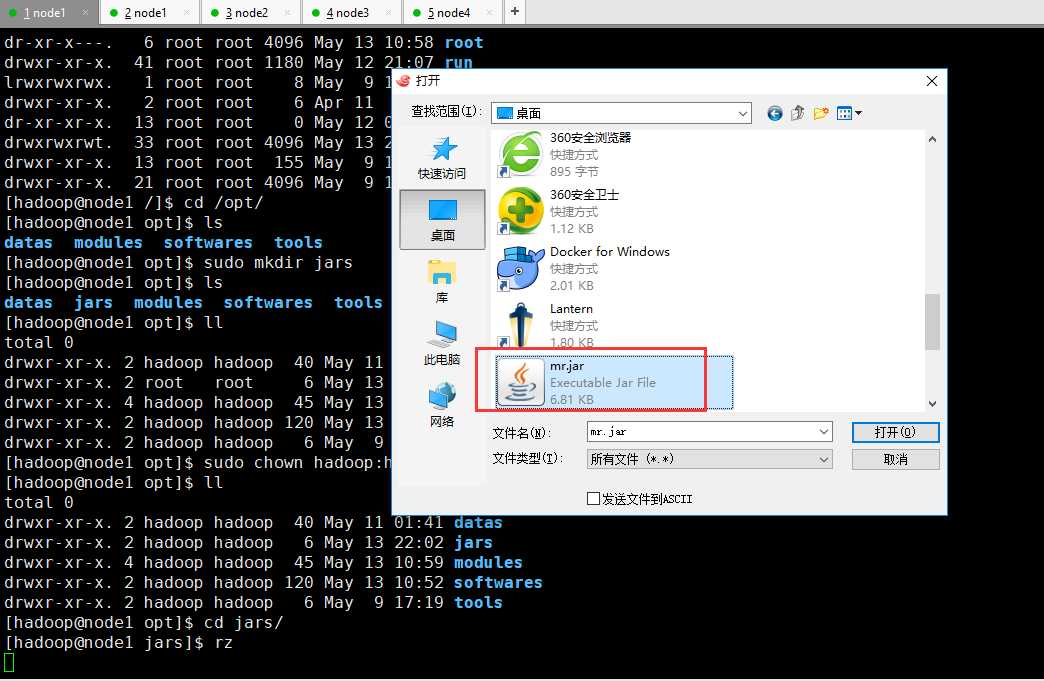
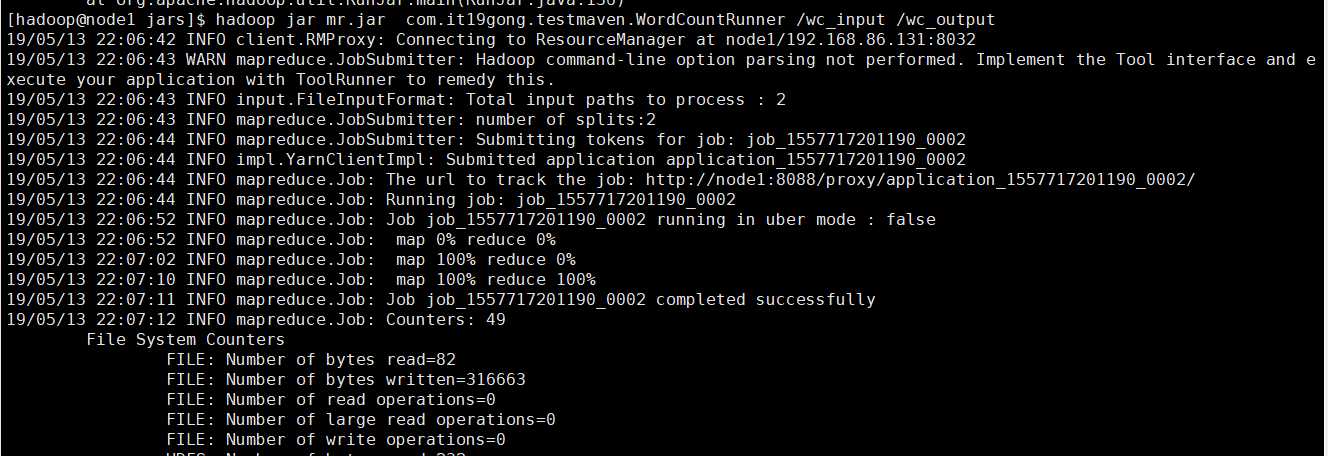
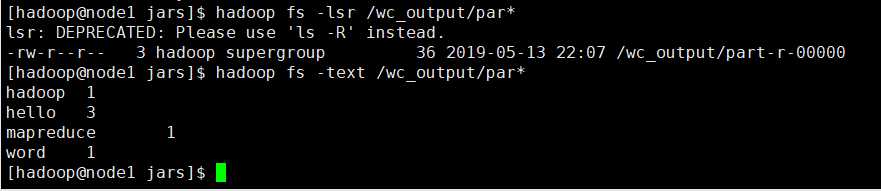
然后在集群上运行一个wordcount小案例
hadoop jar mr.jar com.it19gong.testmaven.WordCountRunner /wc_input /wc_output
以上是关于7.编写mapreduce案例的主要内容,如果未能解决你的问题,请参考以下文章