Docker容器技术的核心原理
Posted jozsm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Docker容器技术的核心原理相关的知识,希望对你有一定的参考价值。
1 前言
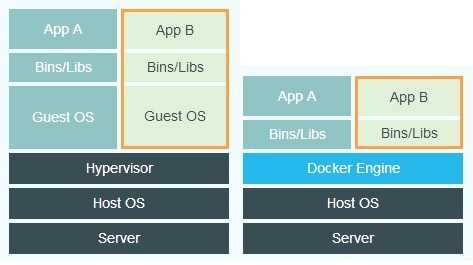
上图是百度的虚拟机和Docker容器的对比图,看着好像都差不多。那么虚拟机技术都这么成熟了,为什么Docker会火起来呢,Docker对比虚拟机等传统技术有什么优势?Docker又是通过什么方式来实现容器的一致性呢?这篇文章我们就通过探究Docker的核心原理,来侧面回答这个疑问。
2 docker容器技术
Docker的核心技术包含以下几点:
? Linux namespace
? Linux cgroup
? rootfs
? 镜像分层
下面我会依次介绍这些技术的原理。
注:本篇基于linux的docker来阐述。其他操作系统的docker容器实现原理不尽相同,各位可回想一下在win10下安装docker时,是不是要求必须启动hyper-V服务了?这个是win10自带的虚拟化服务,也就是说docker在win10下采用了虚拟化技术,并且借助创建MobyLinuxVM虚拟机来实现win10下的容器化。
2.1 隔离:Namespace
这里我们先观察一下已经搭建好的集群容器的情况:
# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
business-manager-666f454f7f-bg2bt 1/1 Running 0 27s 172.30.76.4 192.168.0.21
business-manager-666f454f7f-kvn5z 1/1 Running 0 27s 172.30.76.5 192.168.0.21
business-manager-666f454f7f-ncjp7 1/1 Running 0 27s 172.30.9.4 192.168.0.22
data-product-6664c6dcb9-7sxnz 1/1 Running 0 7m17s 172.30.76.2 192.168.0.21
data-product-6664c6dcb9-j2f48 1/1 Running 0 7m17s 172.30.76.3 192.168.0.21
data-product-6664c6dcb9-p5xkw 1/1 Running 0 7m17s 172.30.9.3 192.168.0.22上图可知,我们有两个Pod跑在192.168.0.22这台宿主机上,pod里实际跑的正是我们打包的docker容器。我们在宿主机上执行docker ps,就可以看到上述两个容器(k8s还将DNS等其他模块的部分组件调度在这台机上,所以docker ps显示的容器不止2个):
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS
e411e063c652 reg.miz.so/aura/business-manager "/bin/sh -c 'nohup .…" 31 minutes ago Up 31 minutes
e081a599315c kubernetes/pause "/pause" 31 minutes ago Up 31 minutes
e07627a10c38 reg.miz.so/jo-demo/data-product "/bin/sh -c 'echo 19…" 37 minutes ago Up 37 minutes
6ff85402a1da kubernetes/pause "/pause" 38 minutes ago Up 38 minutes
1c92cc7a7f44 ist0ne/exechealthz-amd64 "/exechealthz '--cmd…" 3 hours ago Up 3 hours
937128a888f2 ist0ne/dnsmasq-metrics-amd64 "/dnsmasq-metrics --…" 3 hours ago Up 3 hours
4e926555a6f2 kubernetes/pause "/pause" 3 hours ago Up 3 hours 接下来我们进入其他一个容器执行ps,查看容器里都有些什么进程:
# kubectl exec -ti business-manager-666f454f7f-ncjp7 sh
$ ps -efj
UID PID PPID PGID SID C STIME TTY TIME CMD
root 1 0 1 1 0 14:47 ? 00:00:03 ./business-manager -conf /business-manager/config/config.json
root 22 0 22 22 0 15:25 pts/0 00:00:00 sh
root 28 22 28 22 0 15:29 pts/0 00:00:00 ps -efj 进入business-manager这个应用的容器内部,ps查看所有的进程,pid=1的是我们的应用程序,pid=22和28的分别是我们这一步操作执行的sh程序和ps程序。了解linux系统的同学应该知道,pid=1的不是内核的init进程吗(不一定非得是这个进程,但内核总得维护一个“1号”进程,它的作用是作为父进程来启动其他的进程,并且接收那些被应用“遗弃”的孤儿进程)?
那么init进程哪去了呢?
其实上面显示的1号进程,是docker容器的障眼法,这个business-manager进程就是跑在宿主机上的一个特殊的进程,我们查看下宿主机的真实进程情况:
# ps -efj|grep business-manager
root 38156 38138 38156 38156 0 14:47 ? 00:00:03 ./business-manager -conf /business-manager/config/config.json
root 47393 3471 47392 3471 0 15:34 pts/2 00:00:00 grep --color=auto business-manager上面这个pid=33156的才是宿主机上对应business-manager容器的真实进程。
容器(指容器里的应用),是linux系统里的一个特殊进程,docker通过linux namespace技术对应用进程进行了隔离,使的应用只能看到指定的有限的系统信息,这就使应用“以为”自己在一个独立的操作系统环境下。
Linux namespace,跟K8S、C++的namespace的功能是类似的,目的都是将一组资源限定在一个有限的可见范围内。Linux namespace支持以下几项资源隔离:
|名称|宏定义|隔离内容|
| :------- | ----: | :---: |
|Cgroup|CLONE_NEWCGROUP|资源限制Cgroup root directory (since Linux 4.6)|
|IPC|CLONE_NEWIPC|IPC资源System V IPC, POSIX message queues (since Linux 2.6.19)|
|Network|CLONE_NEWNET|网络Network devices, stacks, ports, etc. (since Linux 2.6.24)|
|Mount|CLONE_NEWNS|文件系统Mount points (since Linux 2.4.19)|
|PID|CLONE_NEWPID|进程号Process IDs (since Linux 2.6.24)|
|User|CLONE_NEWUSER|用户User and group IDs (started in Linux 2.6.23 and completed in Linux 3.8)|
|UTS|CLONE_NEWUTS|主机名Hostname and NIS domain name (since Linux 2.6.19)|
这些隔离属性,基本涵盖了一个小型操作系统的运行要素,包含主机名、网络、文件系统等。
要使用上述namespace很容易,在调用内核api clone()函数创建新的进程时,加上上述参数即可。这正是Docker在创建容器(现在大家知道了,就是创建我们的应用程序进程)时所要做的事情。
2.2 限制:Cgroup
Linux的Cgroup机制,是Docker利用的又一大利器。上一节我们知道,容器其实就是宿主机里的一个被框进来的进程,它不能看到外面,但它与宿主机上其他的进程共享了内核资源,所以接下来我们需要对它所能使用的资源作限制,这就是Cgroup机制所提供的。
Cgroup的使用,比较简单粗暴,它利用一组目录和文件的组合,来实现配置和控制。这些目录和文件在/sys/fs/cgroup目录下:
# cd /sys/fs/cgroup/
# ls
blkio cpu cpuacct cpu,cpuacct cpuset devices freezer hugetlb memory net_cls net_cls,net_prio net_prio perf_event pids systemd上述文件夹各自对一些资源进行控制。要使用cgroup很简单,在对应目录下创建一个新的文件夹,cgroup会自动为我们生成相关的一些配置文件:
# cd cpu
# mkdir JoTest
# cd JoTest/
# ls
cgroup.clone_children cgroup.procs cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.event_control cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks我们可以修改period和quota文件,配置进程能够占用的CPU百分比,然后将需要应用这组限制的进程的ID写入tasks文件,即可完成cpu的限制。
2.3 rootfs
Namespace对应用进行了隔离,而cgroup则完成了资源的分配和限制,现在一个针对应用程序的沙盒已经成型。接下来就是考虑开篇提到的一致性问题了?一致性主要是为了解决应用跑在不同的宿主机上不受宿主机环境的差异影响的问题。容器技术出来之前,手动或脚本迁移应用的时候,往往会遇到新的宿主机缺少某个关键组件、或是某些依赖版本差异甚至是操作系统内核差异等因素导致的不一致问题。现在我们来看看docker是怎么解决这个问题的。
对于单个应用程序进程来说,对环境的依赖,关键体现在对操作系统所提供的文件系统的依赖,所以docker所要做的就是通过以下3步给你一套想要的文件系统:
? 通过mount namespace(2.1章节)将应用的文件系统隔离开
? 将应用所需要的文件系统(比如centos:7的所有文件)拷贝到某个目录D下
? 调用chroot将应用的根目录调整为目录D(mount namespace的隔离作用在这里体现出来了,chroot只对在当前namespace下的应用生效,应用在这个“根目录”下可以随便折腾,而不会影响到真实的宿主机根目录。)
上面这3步所构造出来的文件系统,我们称之为rootfs(根文件系统)。应用程序执行“cd /"指令进入的根目录,将被限定在上述目录D下。下面我们简单验证一下这个rootfs。
这里我们在容器的根目录新建一个文件jo1,然后在宿主机上查找这个文件,定位到如下位置:
# cd /var/lib/docker/overlay2/b2231f9f15050ae8d609726d308c2ead60114df3fc5404a24c688d805d4a9883/merged/
# ls
anaconda-post.log bin business-manager data dev etc home jo1 lib lib64 lost+found media mnt opt proc root run sbin srv sys tmp usr var可以看到,上面这个文件夹正是我们的容器所在的“根目录”。
我们也可以用mount指令查看当前宿主机的挂载情况,限于篇幅,这里就不展开解析mount了,下面是mount的输出节选:
# mount|grep overlay2
overlay on /var/lib/docker/overlay2/be512d9faf97c7d860fa16ecc4ecd5057e12feffc8b0804115923f0795bb9f75/merged type overlay (rw,relatime,seclabel,lowerdir=/var/lib/docker/overlay2/l/ZSXN3J4UXRRBMRG3F3RNUZGWUB:/var/lib/docker/overlay2/l/2CCAOTBFIGCYNR73TQEE333CO6:/var/lib/docker/overlay2/l/6Y5GTV75CBUR4WORCMOHYJZQ7Y:/var/lib/docker/overlay2/l/VWENHOE7X3WDA4NK5P7DTTPSIX,upperdir=/var/lib/docker/overlay2/be512d9faf97c7d860fa16ecc4ecd5057e12feffc8b0804115923f0795bb9f75/diff,workdir=/var/lib/docker/overlay2/be512d9faf97c7d860fa16ecc4ecd5057e12feffc8b0804115923f0795bb9f75/work)
overlay on /var/lib/docker/overlay2/8a7546027e2e354bf0bba12600fdb6ac87c199d09589ba90952f28aed74d13b6/merged type overlay (rw,relatime,seclabel,lowerdir=/var/lib/docker/overlay2/l/KOZRXUFTWITQUNAKOZMWSYWTSH:/var/lib/docker/overlay2/l/2CCAOTBFIGCYNR73TQEE333CO6:/var/lib/docker/overlay2/l/6Y5GTV75CBUR4WORCMOHYJZQ7Y:/var/lib/docker/overlay2/l/VWENHOE7X3WDA4NK5P7DTTPSIX,upperdir=/var/lib/docker/overlay2/8a7546027e2e354bf0bba12600fdb6ac87c199d09589ba90952f28aed74d13b6/diff,workdir=/var/lib/docker/overlay2/8a7546027e2e354bf0bba12600fdb6ac87c199d09589ba90952f28aed74d13b6/work)
...2.4 镜像分层
上面3个章节已经可以实现一个基本的容器了。接下来的问题是,我们这么多应用的docker镜像如果全部都包含了整个操作系统的文件,势必给镜像的传播下载带来不便,所以docker为我们实现了镜像分层来解决镜像大小问题。
FROM reg.miz.so/library/centos:7
MAINTAINER "maizuo <[email protected]>"
RUN rm /etc/localtime && ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
WORKDIR /business-manager
ADD ./build/main /business-manager/business-manager
ADD ./build/resource /business-manager/resource
RUN mkdir /data && cd /data && mkdir logs查看上面这个典型的dockerfile文件,其中FROM字段表示我们当前打包的镜像是基于reg.miz.so/library/centos:7来创建的,dockerfile文件里每条指令均会创建一个新的镜像层,这些层合在一起就是一个完整的镜像。
镜像分层的应用,简单的举个例子,比如我们的business-manager和data-product都是基于reg.miz.so/library/centos:7这个镜像建立的,那么我们第一次下载data-product镜像时,需要把reg.miz.so/library/centos:7也下载下来,但当我们再次下载其他的镜像比如business-manager,已经存在的镜像层如reg.miz.so/library/centos:7镜像则无需重复下载,只需要下载增量部分即可,所以多个应用如果基于同样的基础层创建,除第1次外,后面的镜像下载往往只需要下几十M的应用程序即可,这就很大程度上解决了镜像大小的问题。
不同的容器镜像共用相同的层,那么容器如果修改了底层的文件,会不会影响到其他容器呢?答案是不会,docker在这里运用了copy-on-write的手法,限于篇幅,也不展开说了。我们需要记住的是,基于同样的底层镜像创建的新镜像,可以共用相同的镜像层,所以无论是下载还是硬盘存储,都不会太大。(这就是为什么有时候删除一个docker镜像,磁盘空间基本没啥变化)
3 docker容器与虚拟机的对比
有了前面的原理分析,接下来我们可以解答开篇的疑问了:
|特性或原理|Docker Container|虚拟机|
| :------- | ----: | :---: |
|核心原理|进程隔离,共享操作系统内核|硬件虚拟化,在宿主操作系统上再跑一个操作系统|
|如何保证一致性|镜像(rootfs)|安装一个相同的操作系统|
|启动速度|秒级-进程级启动|分钟级-系统级启动|
|硬盘使用|MB-镜像分层的优势|GB|
|性能|几乎无损耗|有损耗|
|单机支持量|单机支持上千个容器|一般几十个|
当然,docker也存在一些弊端,主要是隔离性不足以及隔离不足所带来的安全风险。虚拟机基于硬件虚拟化,每个虚拟机上都运行着独立的系统内核,可以保证与宿主机和其他虚拟机有强隔离,跑在虚拟机内的应用可以随便折腾而无需担心影响到“邻居”。而docker所依赖的namespace提供的是有限的隔离,典型的是系统时间没有被隔离,容器内修改系统时间会直接体现在宿主机上;所以开发过程中,当我们的应用需要修改内核参数时,务必谨慎,明确自己在干啥。
以上是关于Docker容器技术的核心原理的主要内容,如果未能解决你的问题,请参考以下文章