mysql内存数据淘汰机制和大查询会不会把内存打爆?
Posted sjks
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql内存数据淘汰机制和大查询会不会把内存打爆?相关的知识,希望对你有一定的参考价值。
首先我们说一下大查询会不会把内存打爆?
比如说主机内存有5g,但是我们一个大查询的数据有10g,这样会不会把内存打爆呢?
答案:不会
为什么?
因为mysql读取数据是采取边读边发的策略
select * from t1
这条语句的流程是这样的
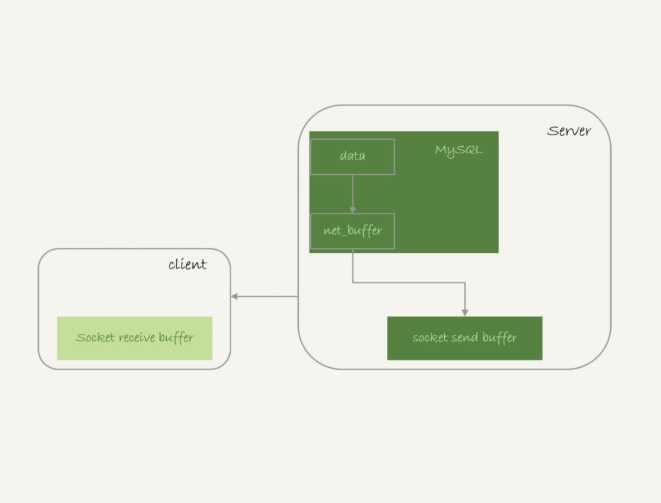
1.读取数据放入net_buffer中,net_buffer大小是由net_buffer_length控制
2.net_buffer放满了以后,调用网络栈发送数据到客户端
3.如果发送成功就清空net_buffer,继续读取数据放入net_buffer中
4.如果发送函数返回EAGAIN或者WSAEWOULDBLOCK就表示本地网络栈满了,这时候就进入等待,知道网络栈重新可写,再继续发送。
根据这个流程来看,读取数据的时候占用的内存最多也就是net_buffer的大小。
InnoDB内存(buffer pool)管理
我们都知道mysql查询数据是先看内存中有没有数据,如果没有就从磁盘中读出来,然后在读入内存
所以说bufferpool对查询有加速效果,加速效果依赖于一个指标也就是内存命中率,如果命中率能达到100%那是最好的
通过
show engine innodb status
可以查看命中率
innodb buffer pool的大小是由参数innodb_buffer_pool_size控制的,一般设置为可用物理内存的60%-80%
内存淘汰
既然内存是一块固定大小的,那么存放在内存里的数据就肯定有的会被淘汰
下面是一个lur算法的基本模型
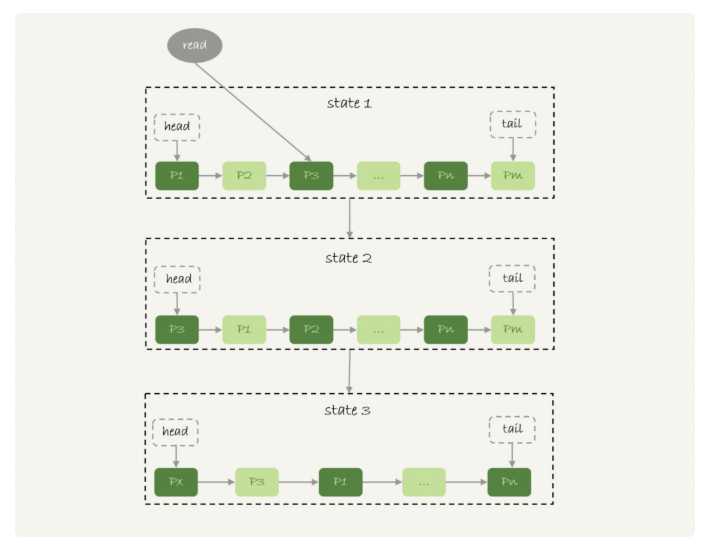
innodb管理bufferpool的lru算法是基于链表实现的
state1:我们要查询p3的数据,由于p3是在内存中的,那么久直接把p3移动到链表头部,
也就是对应图中state2的状态
state3中由于我们查询的px数据不是在px中,那么就从磁盘中查询出px的数据放入链表头部,
但是由于内存满了,所以
就会把pm的数据从链表尾部淘汰掉,从现象上来看就是最久没有被访问都的数据会被淘汰
这种算法对于mysql来说有什么问题??
如果我们对一个冷数据表进行全表扫描,比如说日志表,这些不是正常用户访问的表,
那么在bufferpool中就会大量存在这些数据的表,那么就会导致用户正常访问存放的业务数据会被淘汰掉,
就会导致大量数据需要重新读磁盘放入内存,这样性能就会大大降低
mysql肯定不会允许这种情况发生的,所以它基于上面的lru算法做了改进
下图就是改进后的模型
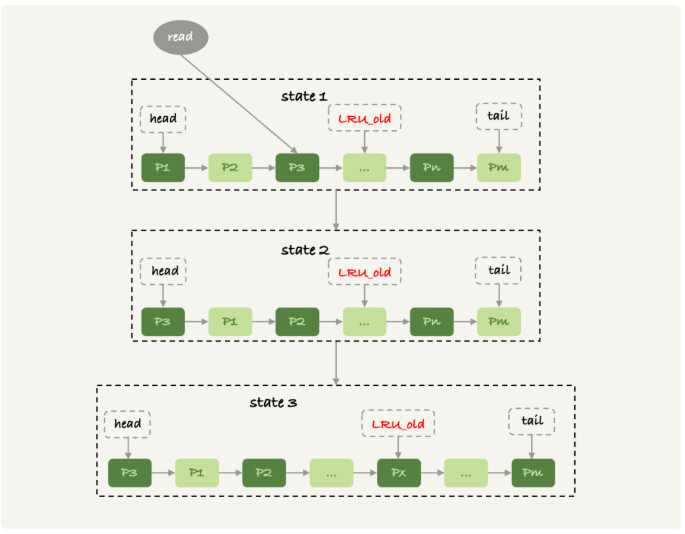
innodb把整个内存的前八分之五记为young区域,后八分之三记为old区域,
我们看上图state1中由于我们访问的p3是在young区域,那么就把p3移动到链表头部
但是如果我们访问的数据如果是在old区域,比如说我们访问了px,这个时候会做个判断
如果px在内存中存活时间超过1秒,就会把它移动到young区域的链表头部,否则位置不动
这个1秒是由参数
innodb_old_blocks_time控制的,默认值是1000,单位毫秒
这样我们在看扫描全表的步骤
扫描过程中被访问的数据页会被放在old区域
一个数据页有多条记录会被访问,所以这数据页会被多次访问到,但是由于是顺序扫描,
这个数据页第一次被访问和最后一次被访问的时间间隔不会超过一秒,所以就会一直在old区域
在继续扫描后面的数据页,之前的这个数据页也不会被访问到,因此就会一直在old区域,也就很快就会被淘汰掉了
可以看到这个策略的最大收益,就是在扫描的过程中,虽然也用到了bufferpool,
但是不会对young区域造成影响,也就保证了bufferpool响应业务的内存命中率
以上是关于mysql内存数据淘汰机制和大查询会不会把内存打爆?的主要内容,如果未能解决你的问题,请参考以下文章