memcached
Posted tidetrace
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了memcached相关的知识,希望对你有一定的参考价值。
1. 使用缓存和不使用缓存的浏览器、应用服务器、数据库、memcached之间的调用关系图。
2. 伪代码实现先读缓存,缓存中没有数据再读取数据库。
参考:https://blog.csdn.net/jingzi123456789/article/details/78432716
3. 在使用缓存过程中,NULL值是否存储到缓存中?为什么?
答:存入redis的值,如果为null是否默认不被存入。当从数据源获取的数据为 null 时,缓存就没有意义了,请求会回到数据源去获取数据。当请求量非常大的话,会造成数据源负载过高而宕机。所以对于 null 的数据,需要做特殊处理,比如使用特殊字符串进行替换。
参考:https://www.cnblogs.com/virtualWindGuest/p/7765687.html
https://blog.csdn.net/Troy__/article/details/40829295
4. 对于上面的问题具体实现是什么样子的?
public class NullValueResultDO implements Serializable{
private static final long serialVersionUID = -6550539547145486005L;
}
public class UserManager {
UserDAO userDAO;
LocalCache localCache;
public UserDO getUser(String userNick) {
Object object = localCache.get(userNick);
if(object != null) {
if(object instanceof NullValueResultDO) {
return null;
}
return (UserDO)object;
} else {
User user = userDAO.getUser(userNick);
if(user != null) {
localCache.put(userNick,user);
} else {
localCache.put(userNick, new NullValueResultDO());
}
return user;
}
}
5. 使用memcache实现分布式锁的伪代码。
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicInteger;
import javax.annotation.Resource;
import javax.servlet.ServletContext;
import javax.servlet.http.HttpServletRequest;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.context.WebApplicationContext;
import org.springframework.web.context.support.WebApplicationContextUtils;
import com.danga.MemCached.MemCachedClient;
import com.danga.MemCached.SockIOPool;
@Controller
public class MemController {
private AtomicInteger ai=new AtomicInteger(0);
static {
String[] serverlist = { "127.0.0.1:11211"};
SockIOPool pool = SockIOPool.getInstance();
pool.setServers(serverlist);
pool.initialize();
}
private static final Logger logger = LoggerFactory.getLogger(MemController.class);
@RequestMapping(value = "/testMem", method = RequestMethod.GET)
public void testMem(HttpServletRequest req,Model model) {
MemCachedClient mc = new MemCachedClient();
String key="test";
boolean b = mc.add(key, "1", 60000);
Integer object =null;
if(b){
object = (Integer) mc.get("test_atomic");
if(object==null){
mc.set("test_atomic", 1);
}else{
object=object+1;
mc.set("test_atomic", object);
}
mc.delete(key);
}else{
ai.getAndIncrement();
}
System.out.println("--------------object:"+object+",error:"+ai.get());
}
}或者
方法一:
在load db之前先add一个mutex key, mutex key add成功之后再去做加载db, 如果add失败则sleep之后重试读取原cache数据。为了防止死锁,mutex key也需要设置过期时间。伪代码如下
if (memcache.get(key) == null) {
// 3 min timeout to avoid mutex holder crash
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
value = db.get(key);
memcache.set(key, value);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
或者
在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中。伪代码如下
v = memcache.get(key);
if (v == null) {
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
value = db.get(key);
memcache.set(key, value);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
} else {
if (v.timeout <= now()) {
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
// extend the timeout for other threads
v.timeout += 3 * 60 * 1000;
memcache.set(key, v, KEY_TIMEOUT * 2);
// load the latest value from db
v = db.get(key);
v.timeout = KEY_TIMEOUT;
memcache.set(key, value, KEY_TIMEOUT * 2);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
}
}
参考:https://blog.csdn.net/chengyongcy/article/details/84810731
https://blog.csdn.net/huwei2003/article/details/54632472
6. 一致性hash算法是什么样子的(画图说明),缓存服务器节点数较少的时候有什么缺点,如何解决?
- 一致性Hash算法的神秘面纱
一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性Hash算法是对2^32取模,什么意思呢?简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下: ?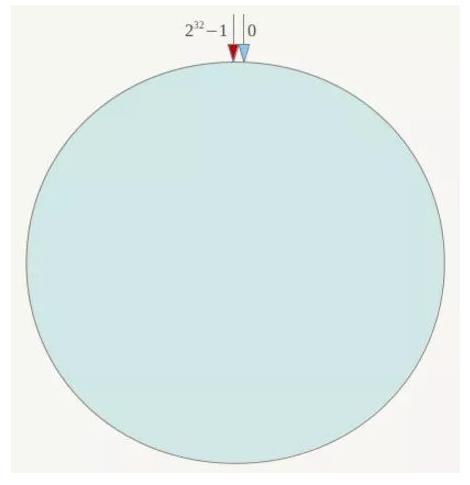
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用IP地址哈希后在环空间的位置如下: ?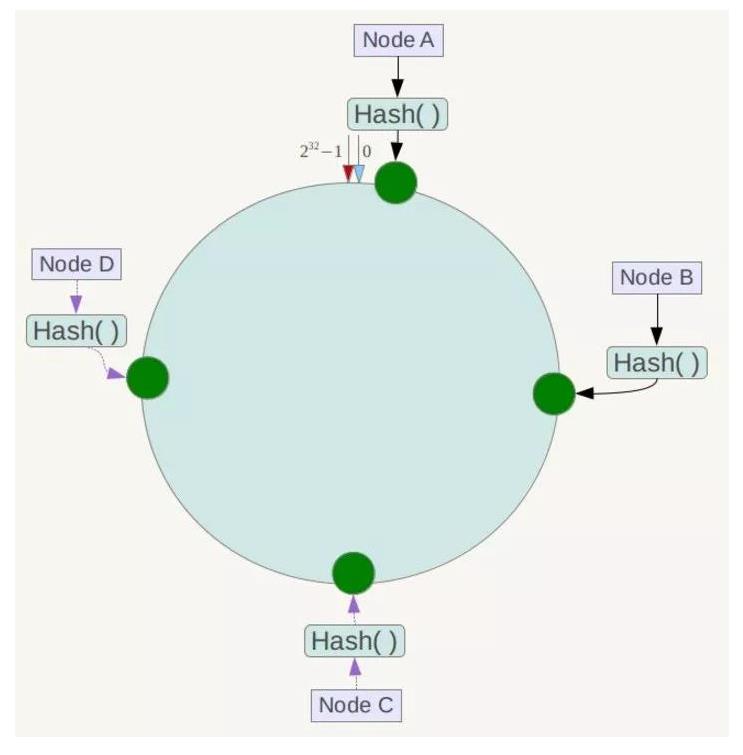
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器!
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:?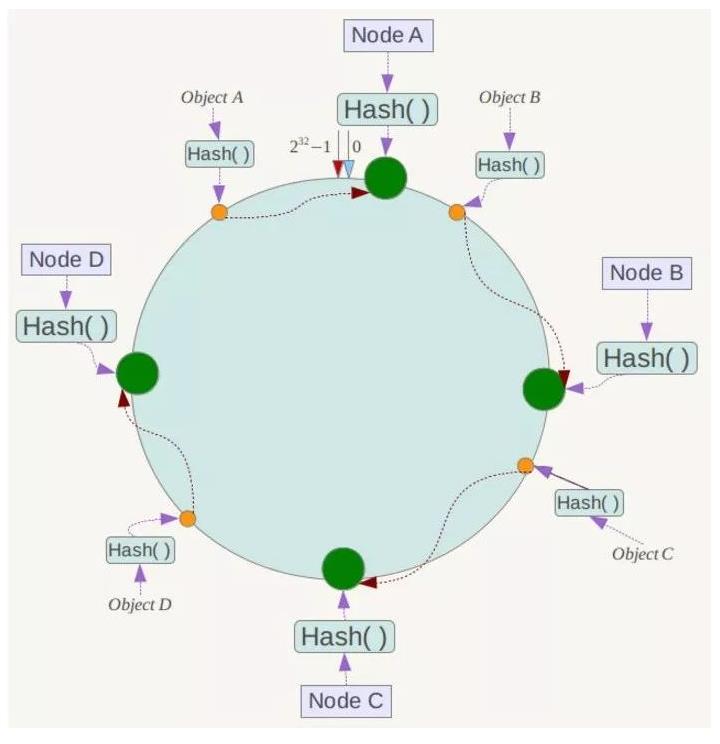
根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
- 一致性Hash算法的容错性和可扩展性
现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响,如下所示: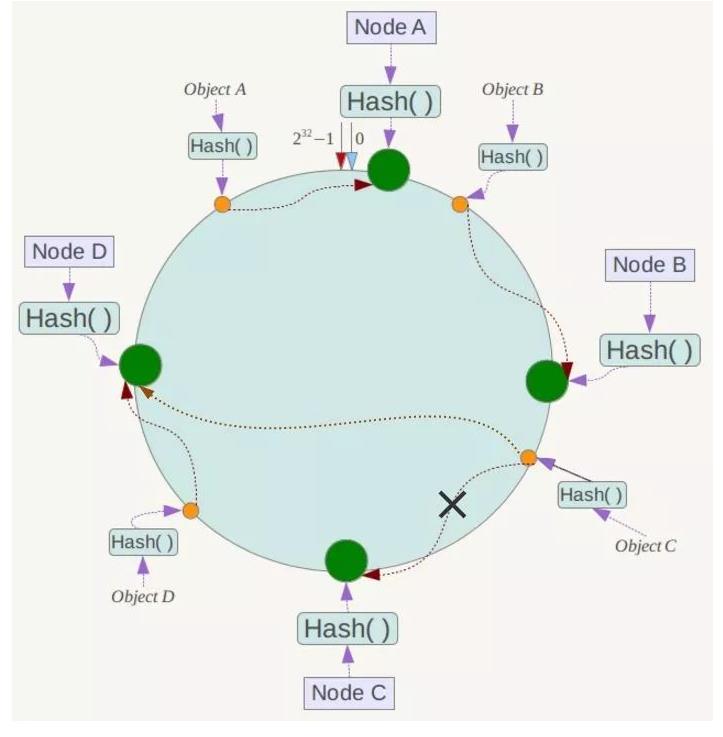
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示: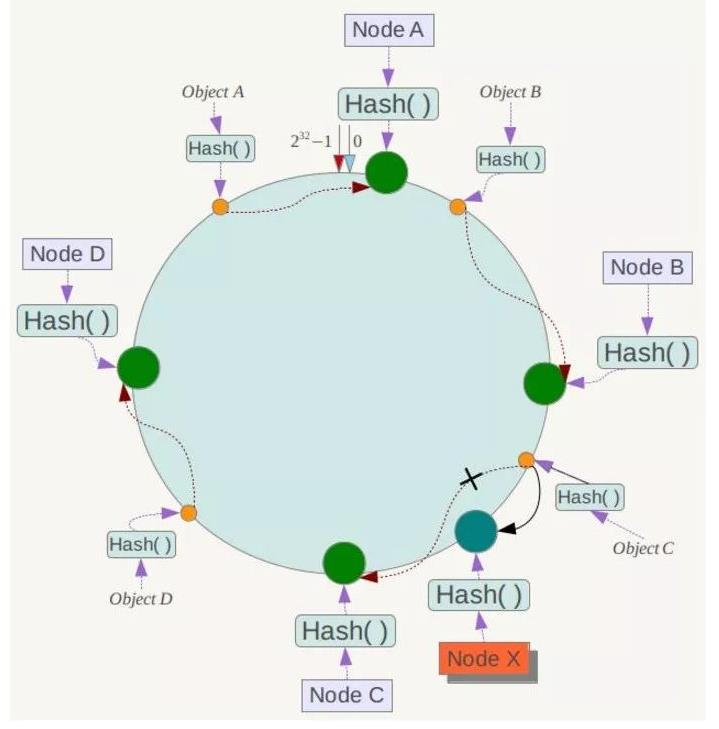
此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X !一般的,在一致性Hash算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
- Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器,其环分布如下:?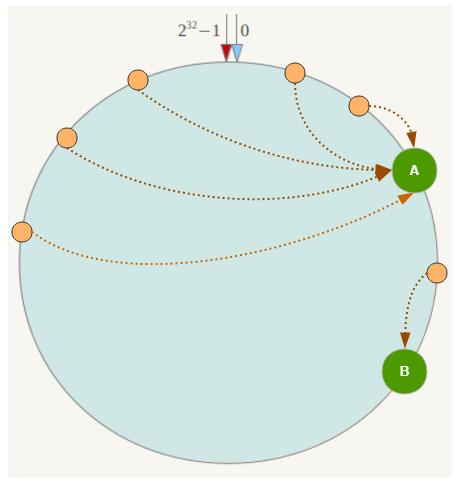
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器IP或主机名的后面增加编号来实现。
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:?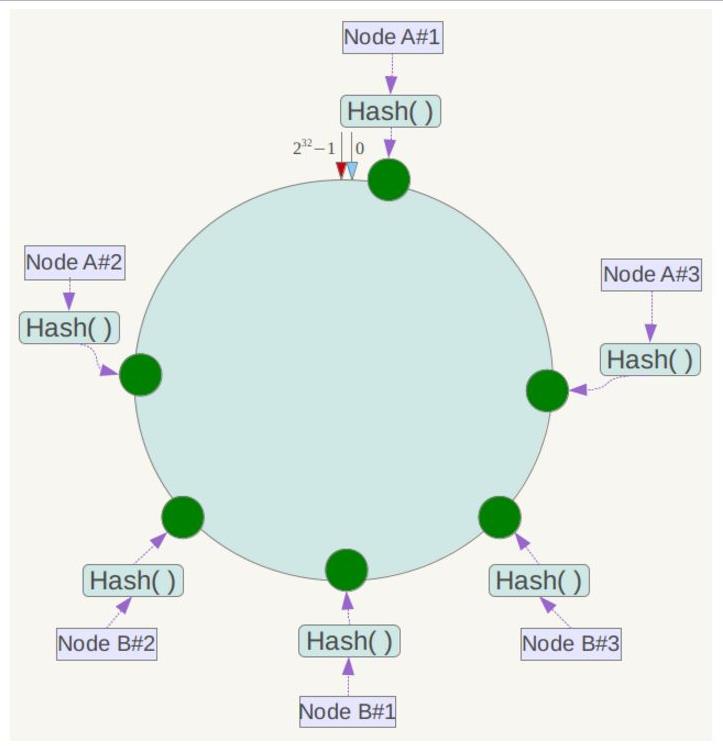
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
参考:https://blog.csdn.net/bntX2jSQfEHy7/article/details/79549368
7. 能否使用memcache作为分布式session的缓存?为什么?
8. 刚起步的小公司有一个应用系统,准备引入缓存提高性能,是否能够使用memcache?为什么?
不建议使用。因为
1、访问数据的速度比传统的关系型数据库要快,因为Oracle、mysql这些传统的关系型数据库为了保持数据的持久性,数据存放在硬盘中,IO操作速度慢
2、MemCache的数据存放在内存中同时意味着只要MemCache重启了,数据就会消失
3、既然MemCache的数据存放在内存中,那么势必受到机器位数的限制,这个之前的文章写过很多次了,32位机器最多只能使用2GB的内存空间,64位机器没有上限。
适用memcached的业务场景:?
1)如果网站包含了访问量很大的动态网页,因而数据库的负载将会很高。由于大部分数据库请求都是读操作,那么memcached可以显著地减小数据库负载。?
2)如果数据库服务器的负载比较低但CPU使用率很高,这时可以缓存计算好的结果( computed objects )和渲染后的网页模板(enderred templates)。?
3)利用memcached可以缓存?session数据?、临时数据以减少对他们的数据库写操作。?
4)缓存一些很小但是被频繁访问的文件。?
5)缓存Web ‘services‘(非IBM宣扬的Web Services,译者注)或RSS feeds的结果.。
不适用memcached的业务场景:?
1)缓存对象的大小大于1MB???
Memcached本身就不是为了处理庞大的多媒体(large media)和巨大的二进制块(streaming huge blobs)而设计的。???
2)key的长度大于250字符???
3)虚拟主机不让运行memcached服务???
? ?? ?如果应用本身托管在低端的虚拟私有服务器上,像vmware, xen这类虚拟化技术并不适合运行memcached。Memcached需要接管和控制大块的内存,如果memcached管理的内存被OS或 hypervisor交换出去,memcached的性能将大打折扣。?
4)应用运行在不安全的环境中???
Memcached为提供任何安全策略,仅仅通过telnet就可以访问到memcached。如果应用运行在共享的系统上,需要着重考虑安全问题。?
5)业务本身需要的是持久化数据或者说需要的应该是database
上面已经对于MemCache做了一个比较详细的解读,这里再次重复总结MemCache的限制和特性:
1、MemCache中可以保存的item数据量是没有限制的,只要内存足够
2、MemCache单进程在32位机中最大使用内存为2G,这个之前的文章提了多次了,64位机则没有限制
3、Key最大为250个字节,超过该长度无法存储
4、单个item最大数据是1MB,超过1MB的数据不予存储
5、MemCache服务端是不安全的,比如已知某个MemCache节点,可以直接telnet过去,并通过flush_all让已经存在的键值对立即失效
6、不能够遍历MemCache中所有的item,因为这个操作的速度相对缓慢且会阻塞其他的操作
7、MemCache的高性能源自于两阶段哈希结构:第一阶段在客户端,通过Hash算法根据Key值算出一个节点;第二阶段在服务端,通过一个内部的Hash算法,查找真正的item并返回给客户端。从实现的角度看,MemCache是一个非阻塞的、基于事件的服务器程序
8、MemCache设置添加某一个Key值的时候,传入expiry为0表示这个Key值永久有效,这个Key值也会在30天之后失效,见memcache.c的源代码:
以上是关于memcached的主要内容,如果未能解决你的问题,请参考以下文章