Linux 文件系统引起的云盘文件系统异常导致 MySQL 数据页损坏事故恢复复盘
Posted piperck
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux 文件系统引起的云盘文件系统异常导致 MySQL 数据页损坏事故恢复复盘相关的知识,希望对你有一定的参考价值。
事故的起因是因为当我访问某个数据库的某个表的时候,mysql 立即出现崩溃并且去查看 MySQL 的错误日志出现类似信息
2019-05-09T05:52:19.232564Z 1027 [ERROR] InnoDB: Space id and page no stored in the page, read in are [page id: space=1668620387, page number=16777216], should be [page id: space=1321, page number=2560] 2019-05-09T05:52:19.232613Z 1027 [ERROR] InnoDB: Database page corruption on disk or a failed file read of page [page id: space=1321, page number=2560]. You may have to recover from a backup. 2019-05-09T05:52:19.232620Z 1027 [Note] InnoDB: Page dump in ascii and hex (16384 bytes): 2019-05-09T05:52:19.301493Z 1027 [Note] InnoDB: Uncompressed page, stored checksum in field1 0, calculated checksums for field1: crc32 509574685/727399785, innodb 723696011, none 3735928559, stored checksum in field2 2940110097, calculated checksums for field2: crc32 509574685/727399785, innodb 2408125488, none 3735928559, page LSN 2131755008 16, low 4 bytes of LSN at page end 0, page number (if stored to page already) 16777216, space id (if created with >= MySQL-4.1.1 and stored already) 1668620387 InnoDB: Page may be a freshly allocated page 2019-05-09T05:52:19.301532Z 1027 [Note] InnoDB: It is also possible that your operating system has corrupted its own file cache and rebooting your computer removes the error. If the corrupt page is an index page. You can also try to fix the corruption by dumping, dropping, and reimporting the corrupt table. You can use CHECK TABLE to scan your table for corruption. Please refer to http://dev.mysql.com/doc/refman/5.7/en/forcing-innodb-recovery.html for information about forcing recovery. 2019-05-09T05:52:19.301558Z 1027 [ERROR] [FATAL] InnoDB: Aborting because of a corrupt database page in the system tablespace. Or, there was a failure in tagging the tablespace as corrupt. 2019-05-09 13:52:19 0x7fe307678700 InnoDB: Assertion failure in thread 140613058529024 in file ut0ut.cc line 942 Trying to get some variables. Some pointers may be invalid and cause the dump to abort. Query (7fe2dc03c240): select * from desktop_document2 Connection ID (thread ID): 1027 Status: NOT_KILLED
可以注意到这里就是 MySQL innodb 的数据发生了损坏。可以看到日志的最下面其实这里就是给出的是可能造成崩溃的 query
这里我们可以看到是要因为对 desktop_document2 进行读取造成的。一旦我们对该表尝试读写或者 check table 都会造成 MySQL 崩溃重启。
这里有两种解决思路:
1. 有备份的话将备份找个地方恢复出来,然后重新生成该表。
2. 如果对应到坏的表 check 了之后发现是可有可无可以重新生成的表,可以直接将该表 drop 掉重建。这样可以省出一些恢复的成本和复杂性。
3. 如果坏的数据不可修复,也没有备份。那么需要避开坏数据用 id 偏移的方式尽量扫描更多的数据出来。
然后这里还有个脚本 可以批量扫描坏表。当遇到第一个坏表的时候检查打印出来的 table_name 并做确认。然后排出掉他再继续扫下面的表。
#!/bin/bash host_name=127.0.0.1 user_name= user_pwd= database= tables=$(/usr/local/webserver/mysql/bin/mysql -h$host_name -u$user_name -p$user_pwd $database -A -Bse "show tables") for table_name in $tables do echo $table_name check_result=$(/usr/local/webserver/mysql/bin/mysql -h$host_name -u$user_name -p$user_pwd $database -A -Bse "check table $table_name" | awk ‘{ print $4 }‘) if [ "$check_result" = "OK" ] then echo "OK TABLE $table_name" fi done
需要注意的是使用该脚本在扫描到坏表的时候同样会触发 MySQL 异常重启。
到目前为止来看似乎情况可控,但是遗憾的是造成这次事故继续扩大的是。当时我发现异常损坏发生在系统盘,然后该盘有天级快照。在和各方确认该数据库影响之后我打算直接使用 aliyun 的天级快照来恢复目前糟糕的情况。然后再重新计算当天的相关数据即可,恢复的周期也比较短。
于是关机开始恢复快照 然而等待我的却是
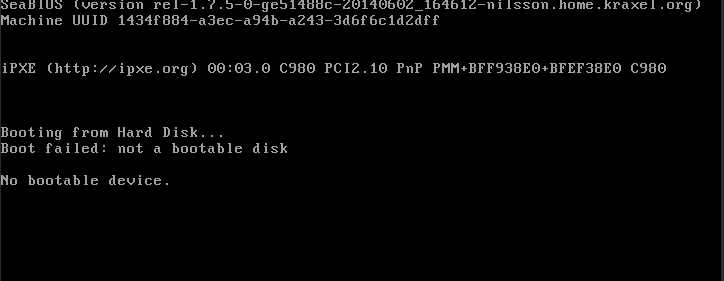
exoo me????
看上去是引导区损坏了,到这里为止就感觉情况变得非常麻烦了。因为快照恢复之后出现这个问题就意味着之前很长一段时间一直都存在引导区因为文件系统损坏而损坏的情况。也就是说可能之前的快照也都坏了,系统盘无法作为引导启动系统。
后来联系 aliyun 工程师通过 liveCD 重启系统,将之前系统挂载到数据盘开始抢救数据。
这里有个值得反思的地方,当时没有做这个机器的数据库备份是因为想到有快照可以依赖,用快照来当备份使用。但是没有考虑打的是,MySQL 的默认数据目录是 /var/lib ,而这个目录存在于数据库上而并非数据盘上。一旦出现类似的文件系统或者引导区损坏重启之后可能就无法进入系统,最严重的情况可能无法使用快照恢复任何数据。
所以说任何时候即使有快照,都应该对你的数据库进行最少天级备份。
在和 aliyun 确认一些信息之后,我列了一个恢复方案最终使用了方案2恢复了数据。下面贴一个 check list
方案1: 1. data02 上用 data-11 5.8日凌晨3点的快照恢复一块 500g 的数据盘。 2. data02 上配置和 data-11 上版本相同的 MySQL(5.7.23)。 3. 使用 data-11 上 MySQL 的数据目录恢复出当时 MySQL 的情况并且启动 MySQL 4. 使用 innobackupex 将机器上的数据库全量备份出来,同时查看数据完整性情况,使用脚本 check table 检查完整性。 5. 将 data-11 机器还原成初始配置,安装同样版本的数据库,并且使用备份恢复数据库数据。 方案2: 1. 直接在 data-11 上重置系统。?? 2. 然后使用镜像挂一个 500g 的盘。?? 3. 通知 aliyun 工程师使得新挂载的盘变得可读。?? 4. 安装 MySQL 5.7.23 数据库。?? 5. 将数据库文件找个地方拷贝出来。?? 6. 将数据文件恢复至 新安装的 5.7.23 数据库,并且不保证相关账号密码都和以前一致。??
这里要提一下方案2的todo 6,如果全量恢复整个数据库的数据,可以直接将整个数据目录进行覆盖,然后重启数据库就可以简单的直接通过文件恢复数据库。
如果是单纯的要恢复某个表或者某个库,最好还是找机器全量恢复之后,使用 mysqldump 或者 pxb 备份对应的库表进行恢复比较简单。直接通过恢复文件的形式恢复单个表库实在太过于复杂了,感觉没必要。
截止到目前数据库就已经恢复了,剩下的还是要 drop 掉坏掉的表进行重建,或者参照上面的方法进行数据抢救。
其实在之前一个月就发现该机器有一些奇怪的报错日志 类似于
Aborted connection 134328328 to db: ‘test‘ user: ‘root‘ host: ‘127.0.0.1‘ (Got timeout reading communication packets)
后来看了一些资料,这些都是一些网络超时错误,与此次事故无关,可以根据 http://mysql.taobao.org/monthly/2017/05/04/ | https://www.percona.com/blog/2016/05/16/mysql-got-an-error-reading-communication-packet-errors/ 来仔细排查网络问题。
小结:
不管有没有快照或者别的保护措施都应该对数据库进行天级备份,有备无患。
当能恢复接触到数据的时候应该第一时间对数据进行再备份,保证至少当前状态可以保证不再恶化。
要第一时间通知相关小伙伴事故处理的进度,以及通知到受影响的小伙伴获得他们的支持,恢复之后第一时间恢复相关服务。
Reference:
https://zhuanlan.zhihu.com/p/60327406 MySQL通过frm、ibd文件恢复innodb数据
http://www.yunweipai.com/archives/19844.html MySQL 如何利用 ibd 文件恢复数据
http://mysql.taobao.org/monthly/2017/05/04/ MySQL · 答疑解惑 · MySQL 的那些网络超时错误
https://www.percona.com/blog/2016/05/16/mysql-got-an-error-reading-communication-packet-errors/ mysql-got-an-error-reading-communication-packet-errors
https://dev.mysql.com/doc/refman/5.7/en/forcing-innodb-recovery.html Forcing InnoDB Recovery
以上是关于Linux 文件系统引起的云盘文件系统异常导致 MySQL 数据页损坏事故恢复复盘的主要内容,如果未能解决你的问题,请参考以下文章