文本分布式表示:用tensorflow和word2vec训练词向量
Posted luv-gem
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分布式表示:用tensorflow和word2vec训练词向量相关的知识,希望对你有一定的参考价值。
博客园的markdown用起来太心塞了,现在重新用其他编辑器把这篇博客整理了一下。
目前用word2vec算法训练词向量的工具主要有两种:gensim 和 tensorflow。gensim中已经封装好了word2vec这个包,用起来很方便,只要把文本处理成规范的输入格式,寥寥几行代码就能训练词向量。这样比较适合在做项目时提高效率,但是对理解算法的原理帮助不大。相比之下,用tensorflow来训练word2vec比较麻烦,生成batch、定义神经网络的各种参数,都要自己做,但是对于理解算法原理,还是帮助很大。
所以这次就用开源的tensorflow实现word2vec的代码,来训练词向量,并进行可视化。这次的语料来自于一个新闻文本分类的项目。新闻文本文档非常大,有 120多M,这里提供百度网盘下载:https://pan.baidu.com/s/1yeFORUVr3uDdTLUYqDraKA 提取码:c98y 。
词向量训练出来有715M,真是醉了!好,开始吧。
一、用tensorflow和word2vec训练中文词向量
这次用到的是skip-gram模型。新闻文本的训练语料是一个txt文档,每行是一篇新闻,开头两个字是标签:体育、财经、娱乐等,后面是新闻的内容,开头和内容之间用制表符 ‘\\t‘ 隔开。
(一)读取文本数据,分词,清洗,生成符合输入格式的内容
这里是用jieba进行分词的,加载了停用词表,不加载的话会发现 “的、一 ”之类的词是排在前列的,而负采样是从词频高的词开始,因此会对结果产生不好的影响。
处理得到的规范格式的输入是这样的,把所有新闻文本分词后做成一个列表:[‘体育‘, ‘马‘, ‘晓‘, ‘旭‘, ‘意外‘, ‘受伤‘, ‘国奥‘, ‘警惕‘, ‘无奈‘, ‘大雨‘, ...]。
#encoding=utf8 from __future__ import absolute_import from __future__ import division from __future__ import print_function import collections import math import os import random import zipfile import numpy as np from six.moves import xrange import tensorflow as tf import jieba from itertools import chain """第一步:读取数据,用jieba进行分词,去除停用词,生成词语列表。""" def read_data(filename): f = open(filename, ‘r‘, encoding=‘utf-8‘) stop_list = [i.strip() for i in open(‘ChineseStopWords.txt‘,‘r‘,encoding=‘utf-8‘)] news_list = [] for line in f: if line.strip(): news_cut = list(jieba.cut(‘‘.join(line.strip().split(‘\\t‘)),cut_all=False,HMM=False)) news_list.append([word.strip() for word in news_cut if word not in stop_list and len( word.strip())>0]) # line是:‘体育\\t马晓旭意外受伤让国奥警惕 无奈大雨格外...‘这样的新闻文本,标签是‘体育’,后面是正文,中间用‘\\t‘分开。 # news_cut : [‘体育‘, ‘马‘, ‘晓‘, ‘旭‘, ‘意外‘, ‘受伤‘, ‘让‘, ‘国奥‘, ‘警惕‘, ‘ ‘, ‘无奈‘,...], 按‘\\t‘来拆开 # news_list为[[‘体育‘, ‘马‘, ‘晓‘, ‘旭‘, ‘意外‘, ‘受伤‘, ‘国奥‘, ‘警惕‘, ‘无奈‘, ...],去掉了停用词和空格。 news_list = list(chain.from_iterable(news_list)) # 原列表中的元素也是列表,把它拉成一个列表。[‘体育‘, ‘马‘, ‘晓‘, ‘旭‘, ‘意外‘, ‘受伤‘, ‘国奥‘, ‘警惕‘, ‘无奈‘, ‘大雨‘, ...] f.close() return news_list filename = ‘data/cnews/cnews.train.txt‘ words = read_data(filename) # 把所有新闻分词后做成了一个列表:[‘体育‘, ‘马‘, ‘晓‘, ‘旭‘, ‘意外‘, ‘受伤‘, ‘国奥‘, ‘警惕‘, ‘无奈‘, ‘大雨‘, ...]
(二)建立词汇表
这一步是把得到的词列表中的词去重,统计词频,然后按词频从高到低排序,构建一个词汇表:{‘UNK‘: 0, ‘中‘: 1, ‘月‘: 2, ‘年‘: 3, ‘说‘: 4, ‘中国‘: 5,...},key是词,‘中’的词频最高,放在前面,value是每个词的索引。
为了便于根据索引来取词,因此把词汇表这个字典进行反转得到:reverse_dictionary: {0: ‘UNK‘, 1: ‘中‘, 2: ‘月‘, 3: ‘年‘, 4: ‘说‘, 5: ‘中国‘,...}。
同时还得到了上面words这个列表中每个词的索引: [259, 512, 1023, 3977, 1710, 1413, 12286, 6118, 2417, 18951, ...]。
词语(含重复)共有1545万多个,去重复后得到19万多个。
"""第二步:建立词汇表""" words_size = len(words) vocabulary_size = len(set(words)) print(‘Data size‘, vocabulary_size) # 共有15457860个,重复的词非常多。 # 词汇表中有196871个不同的词。 def build_dataset(words): count = [[‘UNK‘, -1]] count.extend(collections.Counter(words).most_common(vocabulary_size - 1)) dictionary = dict() # 统计词频较高的词,并得到词的词频。 # count[:10]: [[‘UNK‘, -1], (‘中‘, 96904), (‘月‘, 75567), (‘年‘, 73174), (‘说‘, 56859), (‘中国‘, 55539), (‘日‘, 54018), (‘%‘, 52982), (‘基金‘, 47979), (‘更‘, 40396)] # 尽管取了词汇表前(196871-1)个词,但是前面加上了一个用来统计未知词的元素,所以还是196871个词。之所以第一个元素是列表,是为了便于后面进行统计未知词的个数。 for word, _ in count: dictionary[word] = len(dictionary) # dictionary: {‘UNK‘: 0, ‘中‘: 1, ‘月‘: 2, ‘年‘: 3, ‘说‘: 4, ‘中国‘: 5,...},是词汇表中每个字是按照词频进行排序后的,字和它的索引构成的字典。 data = list() unk_count = 0 for word in words: if word in dictionary: index = dictionary[word] else: index = 0 unk_count += 1 data.append(index) # data是words这个文本列表中每个词对应的索引。元素和words一样多,是15457860个 # data[:10] : [259, 512, 1023, 3977, 1710, 1413, 12286, 6118, 2417, 18951] count[0][1] = unk_count reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys())) return data, count, dictionary, reverse_dictionary # 位置词就是‘UNK‘本身,所以unk_count是1。[[‘UNK‘, 1], (‘中‘, 96904), (‘月‘, 75567), (‘年‘, 73174), (‘说‘, 56859), (‘中国‘, 55539),...] # 把字典反转:{0: ‘UNK‘, 1: ‘中‘, 2: ‘月‘, 3: ‘年‘, 4: ‘说‘, 5: ‘中国‘,...},用于根据索引取词。 data, count, dictionary, reverse_dictionary = build_dataset(words) # data[:5] : [259, 512, 1023, 3977, 1710] # count[:5]: [[‘UNK‘, 1], (‘中‘, 96904), (‘月‘, 75567), (‘年‘, 73174), (‘说‘, 56859)] # reverse_dictionary: {0: ‘UNK‘, 1: ‘中‘, 2: ‘月‘, 3: ‘年‘, 4: ‘说‘, 5: ‘中国‘,...} del words print(‘Most common words (+UNK)‘, count[:5]) print(‘Sample data‘, data[:10], [reverse_dictionary[i] for i in data[:10]]) # 删掉不同的数据,释放内存。 # Most common words (+UNK) [[‘UNK‘, 1], (‘中‘, 96904), (‘月‘, 75567), (‘年‘, 73174), (‘说‘, 56859)] # Sample data [259, 512, 1023, 3977, 1710, 1413, 12286, 6118, 2417, 18951] [‘体育‘, ‘马‘, ‘晓‘, ‘旭‘, ‘意外‘, ‘受伤‘, ‘国奥‘, ‘警惕‘, ‘无奈‘, ‘大雨‘] data_index = 0
(三)为skip-gram模型生成训练的batch
skip-gram模型是根据中心词来预测上下文词的,拿[‘体育‘, ‘马‘, ‘晓‘, ‘旭‘, ‘意外‘, ‘受伤‘, ‘国奥‘, ‘警惕‘, ‘无奈‘, ‘大雨‘]来举例,滑动窗口为5,那么中心词前后各2个词,第一个中心词为 ‘晓’时,上下文词为(体育,马,旭,意外)这样一个没有顺序的词袋。
那么生成的样本可能为:[(晓,马),(晓,意外),(晓,体育),(晓,旭)],上下文词不是按顺序排列的。
""" 第三步:为skip-gram模型生成训练的batch """ def generate_batch(batch_size, num_skips, skip_window): global data_index assert batch_size % num_skips == 0 assert num_skips <= 2 * skip_window batch = np.ndarray(shape=(batch_size), dtype=np.int32) labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32) span = 2 * skip_window + 1 buffer = collections.deque(maxlen=span) # 这里先取一个数量为8的batch看看,真正训练时是以128为一个batch的。 # 构造一个一列有8个元素的ndarray对象 # deque 是一个双向列表,限制最大长度为5, 可以从两端append和pop数据。 for _ in range(span): buffer.append(data[data_index]) data_index = (data_index + 1) % len(data) # 循环结束后得到buffer为 deque([259, 512, 1023, 3977, 1710], maxlen=5),也就是取到了data的前五个值, 对应词语列表的前5个词。 for i in range(batch_size // num_skips): target = skip_window targets_to_avoid = [skip_window] # i取值0,1,是表示一个batch能取两个中心词 # target值为2,意思是中心词在buffer这个列表中的位置是2。 # 列表是用来存已经取过的词的索引,下次就不能再取了,从而把buffer中5个元素不重复的取完。 for j in range(num_skips): # j取0,1,2,3,意思是在中心词周围取4个词。 while target in targets_to_avoid: target = random.randint(0, span - 1) # 2是中心词的位置,所以j的第一次循环要取到不是2的数字,也就是取到0,1,3,4其中的一个,才能跳出循环。 targets_to_avoid.append(target) # 把取过的上下文词的索引加进去。 batch[i * num_skips + j] = buffer[skip_window] # 取到中心词的索引。前四个元素都是同一个中心词的索引。 labels[i * num_skips + j, 0] = buffer[target] # 取到中心词的上下文词的索引。一共会取到上下各两个。 buffer.append(data[data_index]) # 第一次循环结果为buffer:deque([512, 1023, 3977, 1710, 1413], maxlen=5), # 所以明白了为什么限制为5,因为可以把第一个元素去掉。这也是为什么不用list。 data_index = (data_index + 1) % len(data) return batch, labels batch, labels = generate_batch(batch_size=8, num_skips=4, skip_window=2) # batch是 array([1023, 1023, 1023, 1023, 3977, 3977, 3977, 3977], dtype=int32),8个batch取到了2个中心词,一会看样本的输出结果就明白了。 for i in range(8): print(batch[i], reverse_dictionary[batch[i]], ‘->‘, labels[i, 0], reverse_dictionary[labels[i, 0]]) ‘‘‘ 打印的结果如下,突然明白说为什么说取样本的时候是用bag of words 1023 晓 -> 3977 旭 1023 晓 -> 1710 意外 1023 晓 -> 512 马 1023 晓 -> 259 体育 3977 旭 -> 512 马 3977 旭 -> 1023 晓 3977 旭 -> 1710 意外 3977 旭 -> 1413 受伤 ‘‘‘
(四)定义skip-gram模型
这里面涉及的一些tensorflow的知识点在第二部分有写,这里也说明一下。
首先 tf.Graph().as_default() 表示将新生成的图作为整个 tensorflow 运行环境的默认图,如果只有一个主线程不写也没有关系,tensorflow 里面已经存好了一张默认图,可以使用tf.get_default_graph() 来调用(显示这张默认纸),当你有多个线程就可以创造多个tf.Graph(),就是你可以有一个画图本,有很多张图纸,而默认的只有一张,可以自己指定。
tf.random_uniform这个方法是用来产生-1到1之间的均匀分布, 看作是初始化隐含层和输出层之间的词向量矩阵。
nce_loss函数是tensorflow中常用的损失函数,可以将其理解为其将多元分类分类问题强制转化为了二元分类问题,num_sampled参数代表将选取负例的个数。
这个损失函数通过 sigmoid cross entropy来计算output和label的loss,从而进行反向传播。这个函数把最后的问题转化为了(num_sampled ,num_True)这个两分类问题,然后每个分类问题用了交叉熵损失函数。
""" 第四步:定义和训练skip-gram模型""" batch_size = 128 embedding_size = 300 skip_window = 2 num_skips = 4 num_sampled = 64 # 上面那个数量为8的batch只是为了展示以下取样的结果,实际上是batch-size 是128。 # 词向量的维度是300维。 # 左右两边各取两个词。 # 要取4个上下文词,同一个中心词也要重复取4次。 # 负采样的负样本数量为64 graph = tf.Graph() with graph.as_default(): # 把新生成的图作为整个 tensorflow 运行环境的默认图,详见第二部分的知识点。 train_inputs = tf.placeholder(tf.int32, shape=[batch_size]) train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1]) embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0)) embed = tf.nn.embedding_lookup(embeddings, train_inputs) #产生-1到1之间的均匀分布, 看作是初始化隐含层和输出层之间的词向量矩阵。 #用词的索引在词向量矩阵中得到对应的词向量。shape=(128, 300) nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size))) # 初始化损失(loss)函数的权重矩阵和偏置矩阵 # 生成的值服从具有指定平均值和合理标准偏差的正态分布,如果生成的值大于平均值2个标准偏差则丢弃重新生成。这里是初始化权重矩阵。 # 对标准方差进行了限制的原因是为了防止神经网络的参数过大。 nce_biases = tf.Variable(tf.zeros([vocabulary_size])) loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights, biases=nce_biases, labels=train_labels, inputs=embed, num_sampled=num_sampled, num_classes=vocabulary_size)) # 初始化偏置矩阵,生成了一个vocabulary_size * 1大小的零矩阵。 # 这个tf.nn.nce_loss函数把多分类问题变成了正样本和负样本的二分类问题。用的是逻辑回归的交叉熵损失函数来求,而不是softmax 。 optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss) norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keepdims=True)) normalized_embeddings = embeddings / norm # shape=(196871, 1), 对词向量矩阵进行归一化 init = tf.global_variables_initializer()
(五)训练skip-gram模型
接下来就开始训练了,这里没什么好说的,就是训练神经网络,不断更新词向量矩阵,然后训练完后,得到最终的词向量矩阵。源码中还有一个展示邻近词语的代码,我觉得没啥用,删掉了。
num_steps = 10 with tf.Session(graph=graph) as session: init.run() print(‘initialized.‘) average_loss = 0 for step in xrange(num_steps): batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window) feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels} _, loss_val = session.run([optimizer, loss], feed_dict=feed_dict) average_loss += loss_val final_embeddings = normalized_embeddings.eval() print(final_embeddings) print("*"*20) if step % 2000 == 0: if step > 0: average_loss /= 2000 print("Average loss at step ", step, ": ", average_loss) average_loss = 0 final_embeddings = normalized_embeddings.eval() # 训练得到最后的词向量矩阵。 print(final_embeddings) fp=open(‘vector.txt‘,‘w‘,encoding=‘utf8‘) for k,v in reverse_dictionary.items(): t=tuple(final_embeddings[k]) s=‘‘ for i in t: i=str(i) s+=i+" " fp.write(v+" "+s+"\\n") # s为‘0.031514477 0.059997283 ...‘ , 对于每一个词的词向量中的300个数字,用空格把他们连接成字符串。 #把词向量写入文本文档中。不过这样就成了字符串,我之前试过用np保存为ndarray格式,这里是按源码的保存方式。 fp.close()
(六)词向量可视化
用sklearn.manifold.TSNE这个方法来进行可视化,实际上作用不是画图,而是降维,因为词向量是300维的,降到2维或3维才能可视化。
这里用到了t-SNE这一种集降维与可视化于一体的技术,t-SNE 的主要目的是高维数据的可视化,当数据嵌入二维或三维时,效果最好。
值得注意的一点是,matplotlib默认的字体是不含中文的,所以没法显示中文注释,要自己导入中文字体。在默认状态下,matplotlb无法在图表中使用中文。
matplotlib中有一个字体管理器——matplotlib.Font_manager,通过该管理器的方法——matplotlib.Font_manager.FontProperties(fname)可以指定一个ttf字体文件作为图表使用的字体。
"""第六步:词向量可视化 """ def plot_with_labels(low_dim_embs, labels, filename=‘tsne.png‘): assert low_dim_embs.shape[0] >= len(labels), "More labels than embeddings" plt.figure(figsize=(18, 18)) # in inches myfont = font_manager.FontProperties(fname=‘/home/dyy/Downloads/font163/simhei.ttf‘) #加载中文字体 for i, label in enumerate(labels): x, y = low_dim_embs[i, :] plt.scatter(x, y) plt.annotate(label, xy=(x, y), xytext=(5, 2), #添加注释, xytest是注释的位置。然后添加显示的字体。 textcoords=‘offset points‘, ha=‘right‘, va=‘bottom‘, fontproperties=myfont) plt.savefig(filename) plt.show() try: from sklearn.manifold import TSNE import matplotlib.pyplot as plt from matplotlib import font_manager #这个库很重要,因为需要加载字体,原开源代码里是没有的。 tsne = TSNE(perplexity=30, n_components=2, init=‘pca‘, n_iter=5000) plot_only = 500 low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :]) labels = [reverse_dictionary[i] for i in xrange(plot_only)] # tsne: 一个降维的方法,降维后维度是2维,使用‘pca‘来初始化。 # 取出了前500个词的词向量,把300维减低到2维。 plot_with_labels(low_dim_embs, labels) except ImportError: print("Please install sklearn, matplotlib, and scipy to visualize embeddings.")
可视化的结果: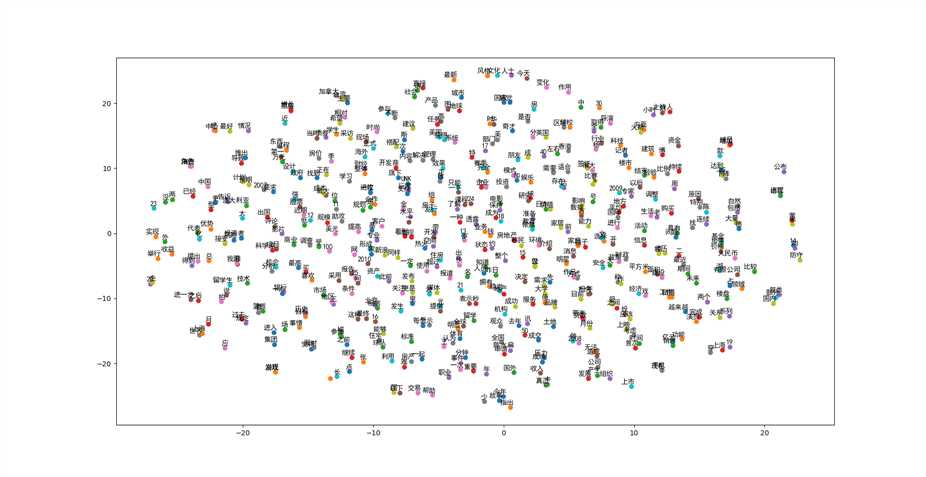
词向量(太大了,打开也要花不少时间)
以上是关于文本分布式表示:用tensorflow和word2vec训练词向量的主要内容,如果未能解决你的问题,请参考以下文章