Spark—RDD介绍
Posted jnba
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark—RDD介绍相关的知识,希望对你有一定的参考价值。
Spark—RDD
1、概念介绍
RDD(Resilient Distributed Dataset):弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
官方定义还是比较抽象,个人理解为:它本质就是一个类,屏蔽了底层对数据的复杂抽象和处理,为用户提供了一组方便数据转换和求值的方法。
2、RDD特点
1)不可变:弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合
2)可分区:RDD在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同Worker节点上,从而让RDD中的数据可以被并行操作。(分布式数据集)
3)弹性:1>存储弹性:内存与磁盘的自动切换 2>容错弹性:数据丢失可以自动恢复
3>计算弹性:计算出错重试机制 4>分片弹性:根据需要重新分片
3、在计算数据中RDD都做了什么:
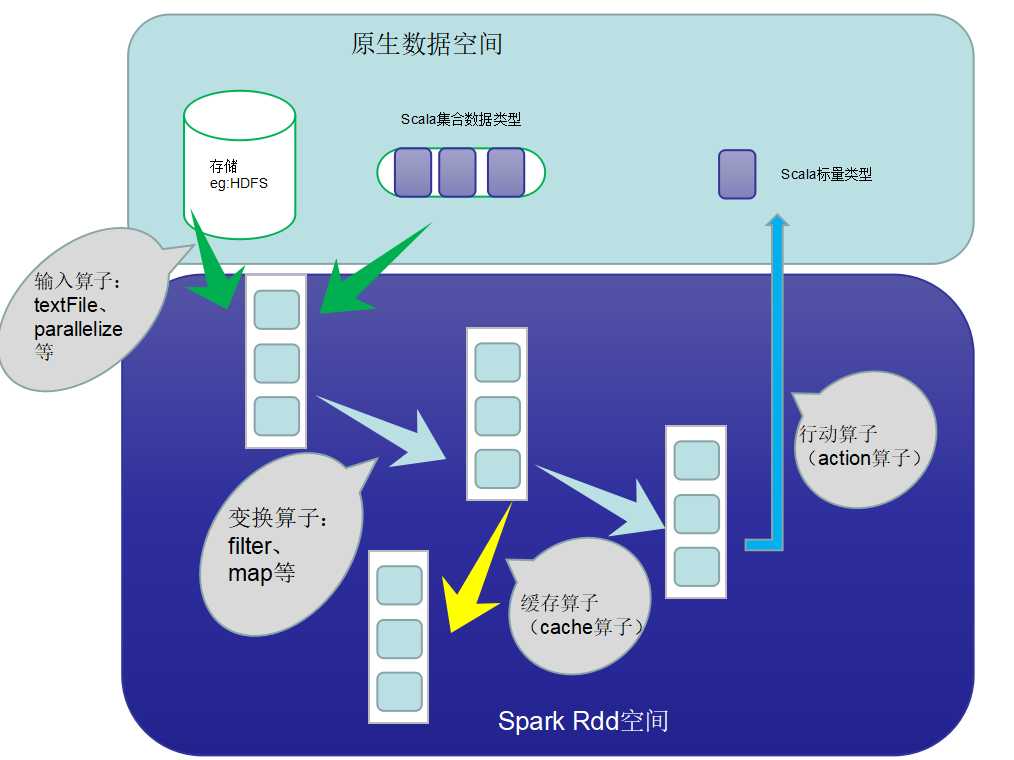
主要流程:
RDD创建——>RDD转换——>RDD缓存——>RDD行动——>RDD的输出
spark计算的核心就在RDD转换、缓存、行动上。
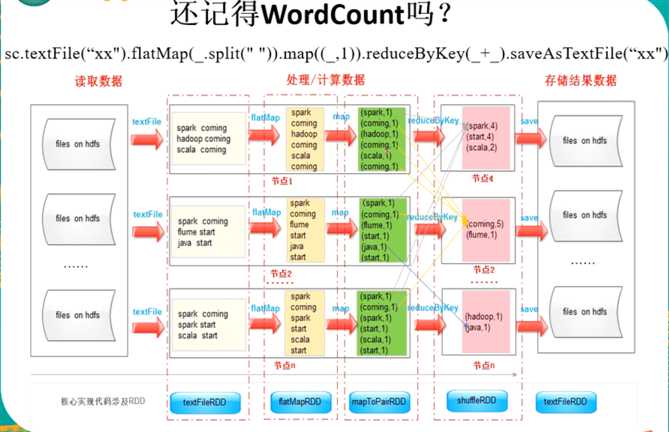
4、Spark wordcount 解释RDD
以上是关于Spark—RDD介绍的主要内容,如果未能解决你的问题,请参考以下文章