数据表达与特征工程
Posted expedition
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据表达与特征工程相关的知识,希望对你有一定的参考价值。
字符串式 的特征称为“类型特征”
数值类型 的特征称为“连续特征”
本节讨论:
- 如何将不同的特征进行转换
- 如何合理表达数据
- 如何进行特征选择
数据表达
1.使用哑变量转换类型特征
哑变量,也称虚拟变量,是一种用来把某些类型变量转换为二值变量的方法
广泛使用于回归分析中
展示get_dummies的使用:
#导入pandas import pandas as pd #手工输入一个数据表 fruits = pd.DataFrame({‘数值特征‘:[5,6,7,8,9],‘类型特征‘:[‘西瓜‘,‘香蕉‘,‘橘子‘,‘苹果‘,‘葡萄‘]}) #显示fruits数据表 display(fruits)
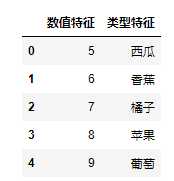
【结果分析】
上图就是我们使用pandas的DataFrame生成一个完整数据集,其中包括整型数值特征[5,6,7,8],还包括字符串组成的类型特征
下面使用get_dummies将类型特征转化为只有0 1 的二值数值特征:
#转化数据表中的字符串为数值 fruits_dum = pd.get_dummies(fruits) #显示转化后的数据表 display(fruits_dum)
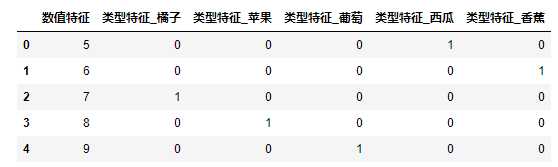
【结果分析】
已全部变成 0 1 的数值变量,或者说是一个 稀疏矩阵
但数值特征并没有发生变化【get_dummies 在默认情况下不会对数值特征进行转化】
假设希望把数值特征也进行get_dummies转换怎么办?
可以先将数值特征转换为字符串,然后通过get_dummies的columns参数来转换:
#令程序将数值也看作字符串 fruits[‘数值特征‘] = fruits[‘数值特征‘].astype(str) #在用get_dummies转化字符串 pd.get_dummies(fruits,columns=[‘数值特征‘])
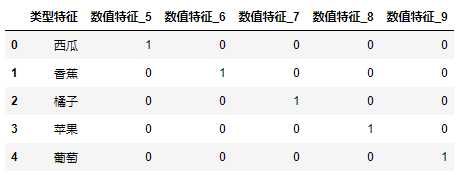
【结果分析】
首先使用 .astype指定了“数值特征”这一列是字符串类型的数据
然后在 get_dummies中指定columns参数为“数值特征”这一列,这样get_dummies就会只转换数值特征了

2.对数据进行装箱处理
不同的算法建立的模型会有很大的差别
即便是在同一个数据集中,这种差别也会存在【算法的工作原理不同】
手工生成一点数据,直观感受相同数据下不同算法的差异:
#导入numpy import numpy as np #导入画图工具 import matplotlib.pyplot as plt #生成随机数列 rnd = np.random.RandomState(38) x= rnd.uniform(-5,5,size=50) #向数据集中添加噪声 y_no_noise = (np.cos(6*x)+x) X = x.reshape(-1,1) y = (y_no_noise + rnd.normal(size=len(x))/2) #绘制图形 plt.plot(X,y,‘o‘,c=‘r‘) plt.show()
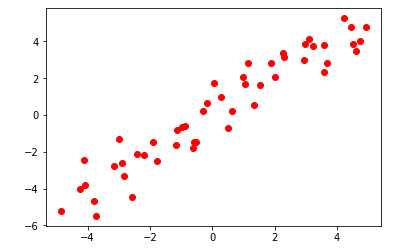 【此段代码用来生成随机数据】
【此段代码用来生成随机数据】
分别用MLP和KNN算法对这个数据集进行回归分析:
#导入神经网络 from sklearn.neural_network import MLPRegressor #导入KNN from sklearn.neighbors import KNeighborsRegressor #生成一个等差数列 line = np.linspace(-5,5,1000,endpoint=False).reshape(-1,1) #分别用两种算法拟合数据 mlpr = MLPRegressor().fit(X,y) knr = KNeighborsRegressor().fit(X,y) #绘制图形 plt.plot(line,mlpr.predict(line),label=‘MLP‘) plt.plot(line,knr.predict(line),label=‘KNN‘) plt.plot(X,y,‘o‘,c=‘r‘) plt.legend(loc=‘best‘) plt.show()
这里我们保持MLP和KNN的参数都为默认值,即MLP有一个隐藏层,节点数为100,而KNN的n_neighbors数量为5
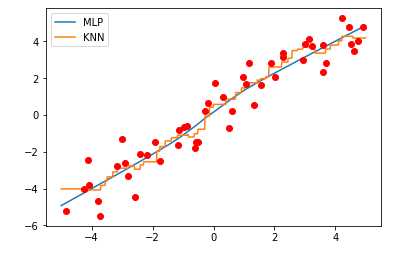
【结果分析】
MLP产生的回归线非常接近线性模型的结果
KNN相对复杂点,视图覆盖更多的数据点
对数据进行装箱处理:【也称离散化处理】
#设置箱体数为11 bins = np.linspace(-5,5,11) #将数据进行装箱操作 target_bin = np.digitize(X,bins=bins) #打印装箱数据范围 print(‘装箱数据范围:\\n‘,bins) #打印前十个数据的特征值 print(‘前十个数据的特征值:\\n‘,X[:10]) print(‘-‘*20) #找到所在的箱子 print(‘找到所在的箱子:\\n‘,target_bin[:10])

生成这个实验数据集的时候,是在-5~5之间随机生成了50个数据点,因此在生成箱子的时候,也指定范围为-5~5之间,生成11个元素的等差数列,这样每两个数值之间就形成了一个箱子,共10个

用新的方法来表达已经装箱的数据——OneHotEncoder,独热编码
OneHotEncoder和pandas的get_dummies功能差不多,但是OneHotEncoder目前只能用于整型数值的类型变量
#导入独热编码 from sklearn.preprocessing import OneHotEncoder onehot = OneHotEncoder(sparse = False) onehot.fit(target_bin) #使用独热编码转换数据 X_in_bin = onehot.transform(target_bin) #打印结果 #装箱后的数据形态 print(‘装箱后的数据形态:\\n‘,X_in_bin.shape) #装箱后的前十个数据点 print(‘装箱后的前十个数据点:\\n‘,X_in_bin[:10])

【结果分析】
虽然数据集中样本的数量仍然是50个,但特征数变成了10个【箱子10个】
而新的数据点的特征是用其所在箱子号码来表示的
如,第1个数据点在第4个箱子中,则,其特征列表中的第4个数字是1,其余都是0
这样一来,相当于把原先数据集中的连续特征转化成了类别特征
用KNN和MLP重新回归分析:
#使用独热编码进行数据表达 new_line = onehot.transform(np.digitize(line,bins=bins)) #使用新的数据来训练模型 new_mlpr = MLPRegressor().fit(X_in_bin,y) new_knr = KNeighborsRegressor().fit(X_in_bin,y) #绘制图形 plt.plot(line,new_mlpr.predict(new_line),label=‘New MLP‘) plt.plot(line,new_knr.predict(new_line),label=‘New KNN‘) plt.plot(X,y,‘o‘,c=‘r‘) #设置图形 plt.legend(loc=‘best‘) plt.show()
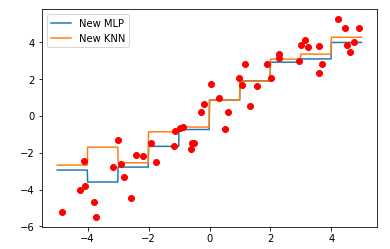
【结果分析】
MLP和KNN模型更相似,当x>0时,两模型几乎重合
和未经装箱的原先图比较,可发现,MLP的回归模型更复杂,KNN更简单
即,对样本特征进行装箱的好处:
- 纠正模型过拟合和欠拟合问题
- 尤其针对大规模高纬度的数据集使用线性模型的时候,可以大幅度提高预测的准确率

数据“升维”
交互式特征:在原始数据特征中添加交互项,使特征数量增加
通过Numpy中的hstack函数实现
了解下hstack的原理:
#手工生成两个数组 array_1 = [1,2,3,4,5] array_2 = [6,7,8,9,0] #使用hstack 将两个数组进行堆叠 array_3 = np.hstack((array_1,array_2)) #打印结果 print(‘将数组2添加到数据1中得到:‘,array_3)
将数组2添加到数据1中得到: [1 2 3 4 5 6 7 8 9 0]
#将原始数据和装箱后的数据进行堆叠 X_stack = np.hstack([X,X_in_bin]) print(X_stack.shape)
(50, 11)【结果分析】
#将数据进行堆叠 line_stack = np.hstack([line,new_line]) #重新训练模型 mlpr_interact = MLPRegressor().fit(X_stack,y) #绘制图形 plt.plot(line,mlpr_interact.predict(line_stack),label=‘MLP for interaction‘) plt.ylim(-4,4) for vline in bins: plt.plot([vline,vline],[-5,5],‘:‘,c=‘k‘) plt.legend(loc=‘lower right‘) plt.plot(X,y,‘o‘,c=‘r‘) plt.show()
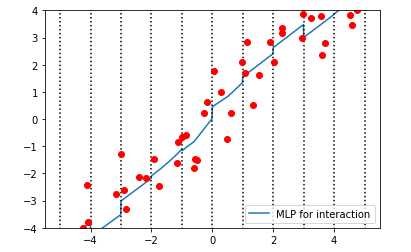
【结果分析】
#使用新的堆叠方式处理数据 X_multi = np.hstack([X_in_bin,X*X_in_bin]) #打印结果 print(X_multi.shape) print(X_multi[0])

【结果分析】
打印第一个样本,发现20个特征中大部分数值是0,而在之前的X_in_bin中数值为1的特征,与原始数据中X的第一个特征值-1.1522688
#重新训练模型 mlpr_multi = MLPRegressor().fit(X_multi,y) line_multi = np.hstack([new_line,line * new_line]) #绘制图形 plt.plot(line,mlpr_multi.predict(line_multi),label=‘MLP Regressor‘) for vline in bins: plt.plot([vline,vline],[-5,5],‘:‘,c=‘gray‘) plt.plot(X,y,‘o‘,c=‘r‘) plt.legend(loc=‘lower right‘) plt.show()
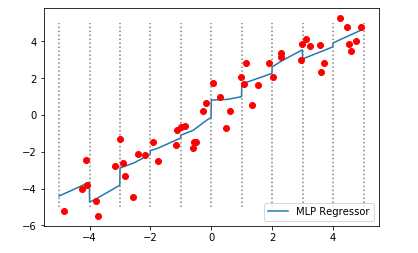
【结果分析】
多项式指的是,多个单项式相加组成的代数式

#导入多项式特征工具 from sklearn.preprocessing import PolynomialFeatures #向多项式添加多项式特征 poly = PolynomialFeatures(degree=20,include_bias=False) X_poly = poly.fit_transform(X) print(X_poly.shape)
(50, 20)
【结果分析】
degree参数 = 20 ,生成20个特征
include_bias = False ,如果设定为True时,PolynomialFeatures只会为数据集添加数值为1的特征
PolynomialFeatures对数据进行怎样的调整?
#打印结果 print(‘原始数据集中的第一个样本特征‘,X[0]) print(‘处理后的数据集中的第一个样本特征‘,X_poly[0])

【结果分析】
原始数据集的样本只有一个特征,而处理后的数据集有20个特征
处理后的样本第一个特征是原始数据样本特征,第二个特征是原始数据特征的平方,第三个,3次方。。。
验证一下结论:
#打印多项式特征的处理方式 print(‘PolynomialFeatures对原始数据的处理:‘,poly.get_feature_names())
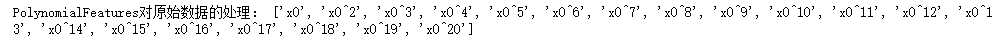
处理后,机器学习的模型有什么变化:
#导入线性回归 from sklearn.linear_model import LinearRegression #使用处理后的数据训练线性回归模型 LNR_poly = LinearRegression().fit(X_poly,y) line_poly = poly.transform(line) #绘制图形 plt.plot(line,LNR_poly.predict(line_poly),label=‘Linear Regressor‘) plt.xlim(np.min(X)-0.5,np.max(X)+0.5) plt.ylim(np.min(y)-0.5,np.max(y)+0.5) plt.plot(X,y,‘o‘,c=‘r‘) plt.legend(loc=‘lower right‘) plt.show()
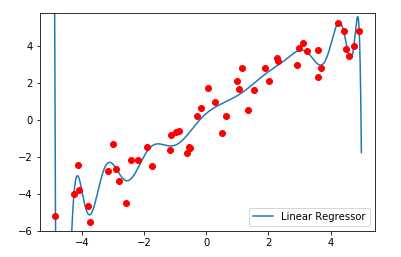
【结果分析】
对于低维数据集,线性模型常常会出现欠拟合,将数据集进行多项式特征扩展后,可以一定程度上解决线性模型欠拟合的问题

在复杂的特征中,有些对于模型预测结果的影响比较大,而有些重要性相对较低
分析样本特征和目标之间是否会有明显的相关性
在统计分析过程中,选那些置信度最高的样本特征进行分析
【只适用于样本特征之间没有明显关联的情况】

由于书本使用的数据集无法下载,所以,放上代码和书上的截图,学习使用“工具”
用A股股票的交易数据集训练机器学习模型:
import pandas as pd #读取股票数据集 stock = pd.read_csv(‘d;/stock dataset/071013.csv‘,encoding=‘GBK‘) #结果 print(stock.head())
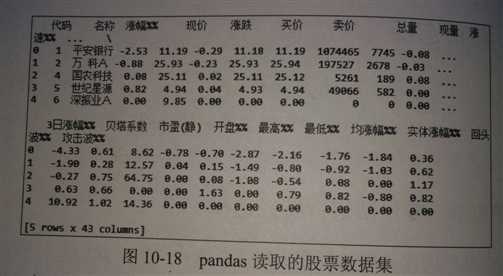
【结果分析】
这个csv文件包括43列
目标是通过回归分析,预测股票的涨幅:
#设置回归分析的目标为涨幅 y = stock[‘涨幅%%‘] print(y.shape) print(y[0])
(3421,)
-2.53
【结果分析】
一共有3421个样本,第一个样本,即“平安银行”的股票当日涨幅为-2.53%
说明指定分析的target成功
指定样本的特征:
#提取特征值 features = stock.loc[:,‘现价‘:‘流通股(亿)‘] X = features.values print(X.shape) print(X[:1])
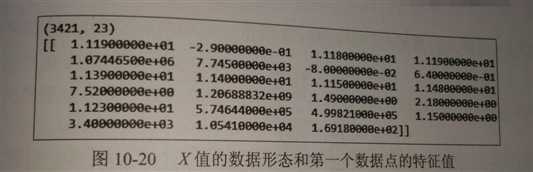
【结果分析】
样本特征一共有23个,下面的数组是第一个样本的全部特征值
但发现,特征值之间的数量级差别较大——> 通过预处理模块进行数据缩放
#导入数据集拆分工具 from sklearn.model_selection import train_test_spilt #导入StandardScaler from sklearn.preprocessing import StandardScaler #设置神经网络隐藏层参数和alpha参数 mlpr=MLPRegreesor(random_state=62,hidden_layer_sizes=(100,100),alpha=0.001) X_train,X_test,y_train,y_test = train_test_spilt(X,y,random_state=62) #对数据进预处理 scaler = StandardScaler() scaler.fit(X_train) X_trian_scaled = scaler.transform(X_train) X_test_scaled = scaler.transform(X_test) #训练神经网络 mlpr.fit(X_train_scaled,y_train) print(mlpr.score(X_test_scaled,y_test))
0.93
下面列出涨幅大于10%的股票:
#列出涨幅>= 10%的股票 wanted = stock.loc[:,‘名称‘] print(wanted[y>=10])

使用SelectPercentile进行特征选择:
#导入特征选择工具 from sklearn.features_selection import SelectPercentile #设置特征选择参数 select = SelectPercentile(percenttile=50) select.fit(X_train_scaled,y_train) X_train_selected = select.transform(X_trian_scaled) print(‘经过缩放的特征形态:‘,X_train_scaled.shape) print(‘特征选择后的特征形态:‘,X_train_selected.shape)

究竟是哪些特征被留下?哪些被去掉?—— get_support查看
#查看那些特征被保留下来 mask = select.get_support() print(mask)

【结果分析】
False表示该特征没有被选择
用图像直观看一下特征选择的结果:
#使用图像表示特征选择的结果 plt.matshow(mask.reshape(1,-1),cmap=plt.cm.cool) plt.xlabel(‘Features Selected‘) plt.show()

经过特征选择的数据集训练的神经网络模型表现:
#使用特征选择后的数据集训练神经网络 X_test_selected = select.transform(X_test_scaled) mlpr_sp = MLPRegreesor(random_state=62,hidden_layer_sizes=(100,100),alpha=0.001) mlpr_sp.fit(X_train_selected,y_train) print(‘得分:‘,mlpr_sp.score(X_test_selected,y_test))
0.88
【结果分析】
进行特征选择后,模型的评分降低很正常,因为数据集并不包括噪声
对于噪声特多的数据集来说,特征选择之后模型评分会提高
【无论使用哪一个模型,“单一变量法”对数据进行处理的方式都是一样的,不依赖于使用什么算法进行建模】
2.基于模型的特征选择
原理————先使用一个有监督学习的模型对数据特征的重要性进行判断,然后把最重要的特征进行保留
【先用的进行判断重要性的模型和最终进行预测分析的模型不一定同一个】
#导入基于模型的特征选择工具 from sklearn.feature_selection import SelectFromModel #导入随机森林模型 from sklearn.ensemble import RandomForestRegressor #设置模型n_estimators参数 sfm = SelectionFormModel(RandomForestRegressor(n_estimators=100,random_state=38),threshold=‘median‘) #使用模型拟合数据 sfm.fit(X_train_scaled,y_train) X_train_sfm = sfm.transform(X_train_scaled) print(‘基于随机森林模型进行特征后的数据形态‘,X_train_sfm.shape)
我们使用了随机森林回归模型进行特征选择————包括随机森林在内的基于决策树的算法都会内置一个称为feature_importances_ 的属性,可以让SelectFromModel直接从这个属性中抽取特征的重要性


【结果分析】
特征选择之后,数据集中样本的特征还剩下12个,少了11个
看一下基于随机森林模型的特征选择有什么区别:
#显示保留的特征 mask_sfm = sfm.get_support() print(mask_sfm)

【结果分析】
该特征选择保留了第2、4、6、9、11、12、15、16、19、20、21、22个特征
对特征选择进行可视化:
#对特征选择进行可视化 plt.matshow(mask_sfm.reshape(1,-1),cmap=plt.cm.cool) plt.xlabel(‘Features Selected‘) plt.show()

【结果分析】

经过随机森林选择的特征,在实际训练模型中表现如何:
#基于特征选择后的数据集训练神经网络 X_test_sfm = sfm.transform(X_test_scaled) mlpr_sfm = MLPRegreesor(random_state=62,hidden_layer_sizes=(100,100),alpha=0.001) mlpr_sfm.fit(X_train_sfm,y_train) print(‘随机森林进行特征选择后的模型得分:‘,mlpr_sfm.score(X_test_sfm,y_test))
0.95
【结果分析】
在其他参数不变的情况下,得分比使用单一变量法进行特征选择的分数高很多
接下来,更强悍的特征选择方法——迭代式特征选择【基于若干个模型进行特征选择】
在sklearn中,有一种称为 递归特征剔出法RFE 的功能就是提高这种方式来进行特征选择的:
- 最开始,RFE对某个模型进行特征选择
- 之后再建立两个模型,其中一个对已经被选择的特征进行筛选
- 另一个对被剔除的模型进行筛选
- 一直重复,直到达到指定的特征数量
这种方式更加强悍,但计算能力要求也更高
使用RFE对股票数据进行特征选择:
#导入RFE工具 from sklearn.feature_selection import RFE rfe = RFE(RandomForestRegressor(n_estimators=100,random_state=38),n_features_to_select=12) #使用RFE工具拟合数据 rfe.fit(X_train_scaled,y_trian) #显示保留的特征 mask = rfe.get_support() print(mask)
为了和前面的模型进行比较,RFE筛选的特征数量也为12个
![]()
可视化表达:
#绘制RFE保留的特征 plt.xlabel(‘Features Selected‘) plt.show()

【结果分析】
RFE选择的特征和单一变量法及基于单个模型的特征选择的结果都不相同
准确率:
#使用新的数据集训练神经网络 X_trian_rfe = rfe.transform(X_train_scaled) X_test_rfe = rfe.transform(X_test_scaled) mlpr_rfe = MLPRegreesor(random_state62,hidden_layer_sizes=(100,100),alpha=0.001) mlpr_rfe.fit(X_trian,y_trian) print(‘RFE选择特征后的模型得分:‘,mlpr_rfe.score(X_test_rfe,y_test))
0.95
【结果分析】
不同的方法没有绝对的好与不好,只是适用不同场景
以上是关于数据表达与特征工程的主要内容,如果未能解决你的问题,请参考以下文章
机器学习特征表达——日期与时间特征做离散处理(数字到分类的映射),稀疏类分组(相似特征归档),创建虚拟变量(提取新特征) 本质就是要么多变少,或少变多