机器学习——Java调用sklearn生成好的Logistic模型进行鸢尾花的预测
Posted baby-lily
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习——Java调用sklearn生成好的Logistic模型进行鸢尾花的预测相关的知识,希望对你有一定的参考价值。
机器学习是python语言的长处,而Java在web开发方面更具有优势,如何通过java来调用python中训练好的模型进行在线的预测呢?在java语言中去调用python构建好的模型主要有三种方法:
1.在Java语言中,通过python的解释器执行python代码,简单来说就是在java中通过python解释器对象,传入写好的python代码,进行执行,这样的方式运行的效率非常低,而且存在很多python包无法使用的情况,只适合做简单的python代码的运行,并不推荐使用。
2.通过PMML工具,将在sklearn中训练好的模型生成一个pmml格式的文件,在该文件中,主要包含了模型的一些训练好的参数,以及输入数据的格式和名称等信息。生成了pmml文件之后,在java中导入pmml相关的包,我们就能通过pmml相关的类读取生成的pmml文件,使用其中的方法传入指定的参数就能实现模型的预测,速度快,效果不错。
3.第二种方法因为模型已经训练好了,无法改变,不能实现在线调参的功能,我们可以通过socket服务来进行python和java之间的网络通信,python提供socket服务,java端将模型的参数通过网络传给python端,python端接受到参数之后,进行模型的训练,训练完成之后,将得到的结果返回给Java端。
下面给是使用pmml方式调用的步骤:
1.在python端生成pmml模型文件,下面以logistic回归为例
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.85, random_state=1) model = PMMLPipeline([(‘LogisticModer‘, LogisticRegression())]) model.fit(x_train, y_train) y_hat = model.predict(x_test) loss = y_hat == y_test accuracy = np.mean(loss) print(accuracy) sklearn2pmml(model, ‘.\\LogisticRegression.pmml‘, with_repr=True)
需要加载的包
from sklearn2pmml import sklearn2pmml from sklearn2pmml.pipeline import PMMLPipeline
我们使用PMMLPipeline()的管道函数,还可以在管道中加入其它的一些预处理的操作,比如归一化。sklearn2pmml()函数能够将训练好的模型生成pmml文件,下面来看生成的pmml文件是怎样的吧:
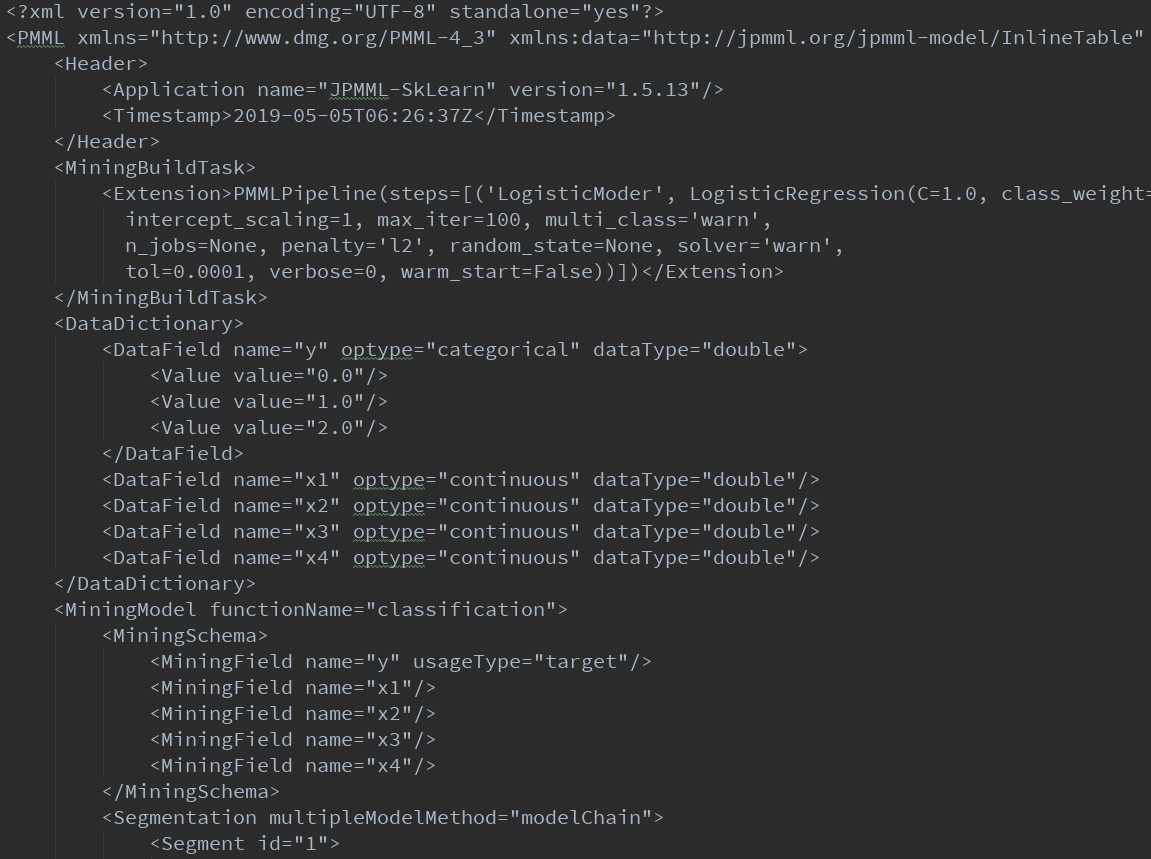
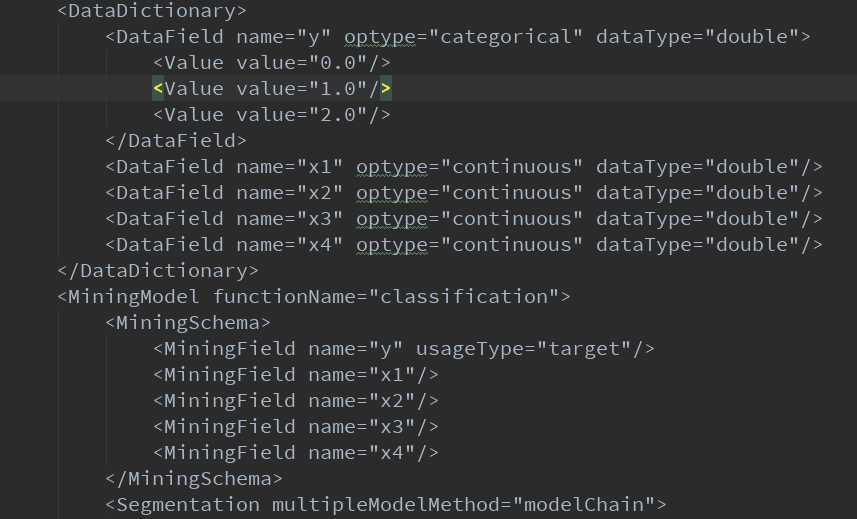
下面,我们建一个JavaWeb工程:
1 <dependency> 2 <groupId>org.jpmml</groupId> 3 <artifactId>pmml-evaluator</artifactId> 4 <version>1.4.1</version> 5 </dependency> 6 7 8 <dependency> 9 <groupId>org.jpmml</groupId> 10 <artifactId>pmml-evaluator-extension</artifactId> 11 <version>1.4.1</version> 12 </dependency> 13 <dependency>
在maven中引入相关的依赖,我们将要用到的方法进行封装,制作成一个工具类:
public static PMML getPMMLModel(InputStream inputStream) { PMML pmml = new PMML(); try { pmml = org.jpmml.model.PMMLUtil.unmarshal(inputStream); } catch (SAXException e1) { e1.printStackTrace(); } catch (JAXBException e2) { e2.printStackTrace(); } finally { try { inputStream.close(); } catch (IOException e) { e.printStackTrace(); } return pmml; } } public static Evaluator loadPmmlAndgetEvaluator(MachineLearnType machineLearnType) { String modefile = getJpmmlModelPath(machineLearnType); //获取模型的pmml文件路径 InputStream inputStream = readPmmlFile(modefile); //根据文件路径返回输入流 PMML pmml = getPMMLModel(inputStream); //根据输入流返回PMML ModelEvaluatorFactory modelEvaluatorFactory = ModelEvaluatorFactory.newInstance(); //获取 ModelEvaluatorFactory Evaluator evaluator = modelEvaluatorFactory.newModelEvaluator(pmml); // 根据 PMML 模型返回 Evaluator 对象 pmml = null; return evaluator; } public static Map<String, Object> modelPrediction(Evaluator evaluator, Map<String, Object> paramData) { if (evaluator == null || paramData == null) { System.out.println("--------------传入对象 evaluator 或 dataMap 为空, 无法进行预测----------------"); return null; } List<InputField> inputFields = evaluator.getInputFields(); //获取模型的输入域 Map<FieldName, FieldValue> arguments = new LinkedHashMap<>(); for (InputField inputField : inputFields) { //将参数通过模型对应的名称进行添加 FieldName inputFieldName = inputField.getName(); //获取模型中的参数名 Object paramValue = paramData.get(inputFieldName.getValue()); //获取模型参数名对应的参数值 FieldValue fieldValue = inputField.prepare(paramValue); //将参数值填入模型中的参数中 arguments.put(inputFieldName, fieldValue); //存放在map列表中 } Map<FieldName, ?> results = evaluator.evaluate(arguments); List<TargetField> targetFields = evaluator.getTargetFields(); Map<String, Object> resultMap = new HashMap<>(); for(TargetField targetField : targetFields) { FieldName targetFieldName = targetField.getName(); Object targetFieldValue = results.get(targetFieldName); if (targetFieldValue instanceof Computable) { Computable computable = (Computable) targetFieldValue; resultMap.put(targetFieldName.getValue(), computable.getResult()); }else { resultMap.put(targetFieldName.getValue(), targetFieldValue); } } return resultMap; }
上述的方法中,我们将生成的pmml文件读取,得到InputStream对象,调用上述的方法就行了。上面的代码中,MachineLearnType的作用就是获取pmml的路径,我们将要输入的参数放入Map中,进行预测,最后返回预测结果的Map,下面来看Service层的代码,其中MachineLearnType.LOGISTIC_REGRESSION就是根据名称获取pmml文件:
Evaluator evaluator = JPmmlModelUtil.loadPmmlAndgetEvaluator(MachineLearnType.LOGISTIC_REGRESSION); Map<String , Object> results = JPmmlModelUtil.modelPrediction(evaluator, paramMap); int result =(int)((double)results.get("y"));
下面是Controller层的代码:
/** * 使用pmml方式对输入的参数进行线性回归预测 */ @PostMapping("/logispmml") public ServerResponse<String> IrisLogosPmmlPredict(@RequestParam @Valid double x1, @RequestParam @Valid double x2, @RequestParam @Valid double x3, @RequestParam @Valid double x4) { logger.info("x1: " + x1 + " x2: " + x2 + " x3:" + x3 + "x4:" + x4); Map<String, Object> paramMap = new HashMap<>(); paramMap.put("x1", x1); paramMap.put("x2", x2); paramMap.put("x3", x3); paramMap.put("x4", x4); String result = logisticRegressionService.pridictlogisticpmml(paramMap); return createBySuccess(result); }
我们生成的模型是logistic回归进行鸢尾花数据集的分类,输入的是样本的四个特征,输出是类别0,1,2
int result =(int)((double)results.get("y")); String irisName = new String(); if(result == 0){ irisName = "Iris-setosa"; } if(result == 1){ irisName = "Iris-versicolor"; } if(result == 2){ irisName = "Iris-virginica"; } return irisName; }
我们在service中将预测结果转换为对应的类别,下面使用测试工具进行测试:
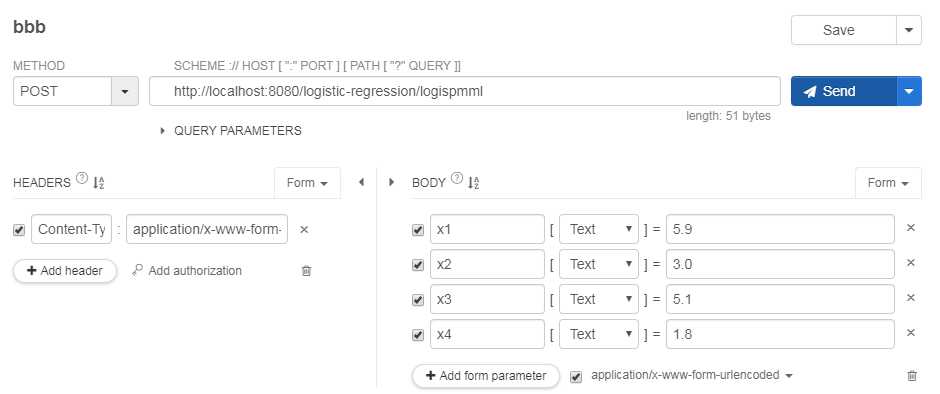
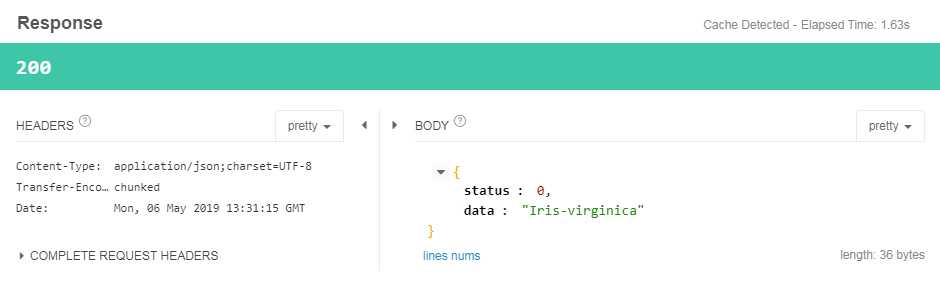
我们就可以在python中将模型构建好,来进行调用啦!
以上是关于机器学习——Java调用sklearn生成好的Logistic模型进行鸢尾花的预测的主要内容,如果未能解决你的问题,请参考以下文章