R语言中多分类问题 multicalss classification 的性能测量
Posted 大数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言中多分类问题 multicalss classification 的性能测量相关的知识,希望对你有一定的参考价值。
判别分析包括可用于分类和降维的方法。线性判别分析(LDA)特别受欢迎,因为它既是分类器又是降维技术。二次判别分析(QDA)是LDA的变体,允许数据的非线性分离。最后,正则化判别分析(RDA)是LDA和QDA之间的折衷。
本文主要关注LDA,并探讨其在理论和实践中作为分类和可视化技术的用途。由于QDA和RDA是相关技术,我不久将描述它们的主要属性以及如何在R中使用它们。
线性判别分析
LDA是一种分类和降维技术,可以从两个角度进行解释。第一个是解释是概率性的,第二个是更多的程序解释,归功于费舍尔。第一种解释对于理解LDA的假设是有用的。第二种解释可以更好地理解LDA如何降低维数。
费舍尔的解释
Fisher的LDA优化标准规定组的质心应尽可能分散。这相当于找到一个线性组合?= a?XZ=aTX,使得aTaT相对于类内方差的类间方差最大化。
如前所述,类内方差是WW被汇集的协方差矩阵Σ^Σ^,这表明从它们的类质心的所有观察的偏差。如前所述,根据质心与总体平均值的偏差来定义类间方差。对于ZZ,类方差之间是aTBaaTBa与类内方差是一个?w ^一个ATWa。因此,可以通过瑞利商来优化LDA
它定义了XX到新空间ZZ的最佳映射。需要注意的是Z∈R1×pZ∈R1×p,即,观测被映射到单个维度。为了获得额外的维度,我们需要解决的最优化问题的a1,…,aK−1a1,…,aK−1,其中每个连续akak构造是在正交WW以前的判别坐标。这导致线性变换G=(ZT1,ZT2,…,ZTK−1)∈Rp×qG=(Z1T,Z2T,…,ZK−1T)∈Rp×q,使我们可以从映射pp到qq经由尺寸XGXG。为什么我们考虑K−1K−1预测?这是因为由KK质心跨越的仿射子空间具有至多K−1K−1的等级。
降低LDA
LDA在缩小的子空间中执行分类。在执行分类时,我们不需要使用所有K−1K−1维度,而是可以选择较小的子空间HlHl其中l<K−1l<K−1。当使用l<K−1l<K−1,这称为降阶LDA。降级LDA的动机是,基于减少数量的判别变量的分类可以在模型过度拟合时提高测试集的性能。
LDA模型的复杂性
LDA的有效参数的数量可以通过以下方式导出。有KK手段μ^kμ^k被估计。协方差矩阵不需要额外的参数,因为它已经由质心定义。由于我们需要估计KK判别函数(以获得判定边界),这就产生了涉及p个元素的KK计算。另外,我们有?-1为自由参数?前科。因此,有效LDA参数的数量是Kp+(K-1)。
LDA摘要
在这里,我总结了LDA的两个观点,并总结了该模型的主要特性。
概率论
LDA使用贝叶斯规则来确定观察xx属于kk类的后验概率。由于LDA的正常假设,后验由多元高斯定义,其协方差矩阵假定对于所有类是相同的。新的点通过计算判别函数分类δkδk(后验概率的枚举器)并返回类kk具有最大δkδk。判别变量可以通过类内和类间方差的特征分解来获得。
费舍尔的观点
根据Fisher,LDA可以理解为降维技术,其中每个连续变换是正交的并且相对于类内方差最大化类间方差。此过程将特征空间转换为具有K−1K−1维度的仿射空间。在对输入数据进行扩展之后,可以通过在考虑类先验的情况下确定仿射空间中的最接近的质心来对新点进行分类。
LDA的特性
LDA具有以下属性:
- LDA假设数据是高斯数据。更具体地说,它假定所有类共享相同的协方差矩阵。
- LDA在K−1K−1维子空间中找到线性决策边界。因此,如果自变量之间存在高阶相互作用,则不适合。
- LDA非常适合于多类问题,但是当类分布不平衡时应该小心使用,因为根据观察到的计数来估计先验。因此,观察很少被分类为不常见的类别。
- 与PCA类似,LDA可用作降维技术。请注意,LDA的转换本质上与PCA不同,因为LDA是一种考虑结果的监督方法。
音素数据集
为了举例说明线性判别分析,我们将使用音素语音识别数据集。该数据集对于展示判别分析很有用,因为它涉及五种不同的结果。
<span style="color:#000000"><span style="color:#000000"><code><strong>library</strong>(RCurl)
f <- getURL(<span style="color:#880000">‘https://www.datascienceblog.net/data-sets/phoneme.csv‘</span>)
df <- read.csv(textConnection(f), header=<span style="color:#78a960">T</span>)
print(dim(df))</code></span></span>## [1] 4509 259数据集包含五个音素的数字化语音样本:aa(如暗中的元音),ao(作为水中的第一个元音),dcl(如在黑暗中),iy(作为她的元音)和sh(如她)。总共选择了4509个32毫秒的语音帧。对于每个语音帧,计算长度为256的对数周期图,在此基础上我们想要执行语音识别。标记为x.1到x.256的256列标识语音特征,而列g和扬声器 分别表示音素(标签)和扬声器。
为了以后评估模型,我们将每个样本分配到培训或测试集中:
<span style="color:#000000"><span style="color:#000000"><code><span style="color:#888888">#logical vector: TRUE if entry belongs to train set, FALSE else</span>
train <- grepl(<span style="color:#880000">"^train"</span>, df$speaker)
<span style="color:#888888"># remove non-feature columns</span>
to.exclude <- c(<span style="color:#880000">"row.names"</span>, <span style="color:#880000">"speaker"</span>, <span style="color:#880000">"g"</span>)
feature.df <- df[, !colnames(df) %<strong>in</strong>% to.exclude]
test.set <- subset(feature.df, !train)
train.set <- subset(feature.df, train)
train.responses <- subset(df, train)$g
test.responses <- subset(df, !train)$g</code></span></span>在R中拟合LDA模型
我们可以通过以下方式拟合LDA模型:
<span style="color:#000000"><span style="color:#000000"><code><strong>library</strong>(MASS)
lda.model <- lda(train.set, grouping = train.responses)</code></span></span>让我们花一点时间来研究模型的相关组件:
- 现有包含组先验πkπk和计数相应的组计数,NkNk。
- 装置是质心基质M∈RK×pM∈RK×p,其分量是平均值矢量,μkμk。
- 缩放是N×(K−1)N×(K−1)矩阵,它将样本转换为由K−1K−1判别变量定义的空间。
- svd是奇异值,表示线性判别变量之间和组内标准差的比率。
LDA作为可视化技术
我们可以通过在缩放数据上应用变换矩阵将训练数据转换为规范坐标。要获得与predict.lda函数返回的结果相同的结果,我们需要首先围绕加权平均数据居中:
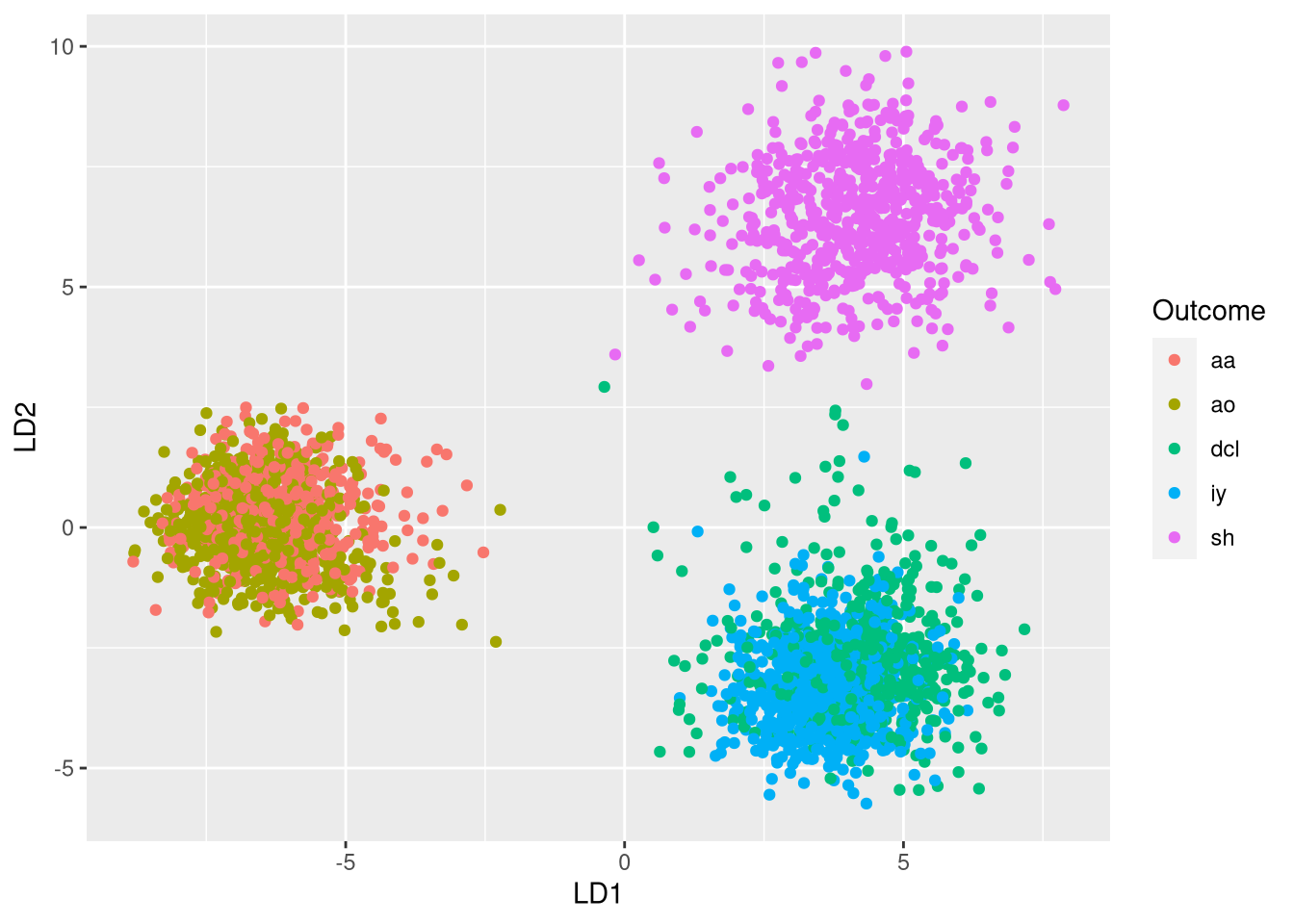
## [1] TRUE我们可以使用前两个判别变量来可视化数据:
![]() ?
?
绘制两个LDA维度中的数据显示三个集群:
- 群集1(左)由aa和ao音素组成
- 群集2(右下角)由dcl和iy音素组成
- 群集3(右上角)由sh音素组成
这表明两个维度??不足以区分所有5个类别。然而,聚类表明可以非常好地区分彼此充分不同的音素。
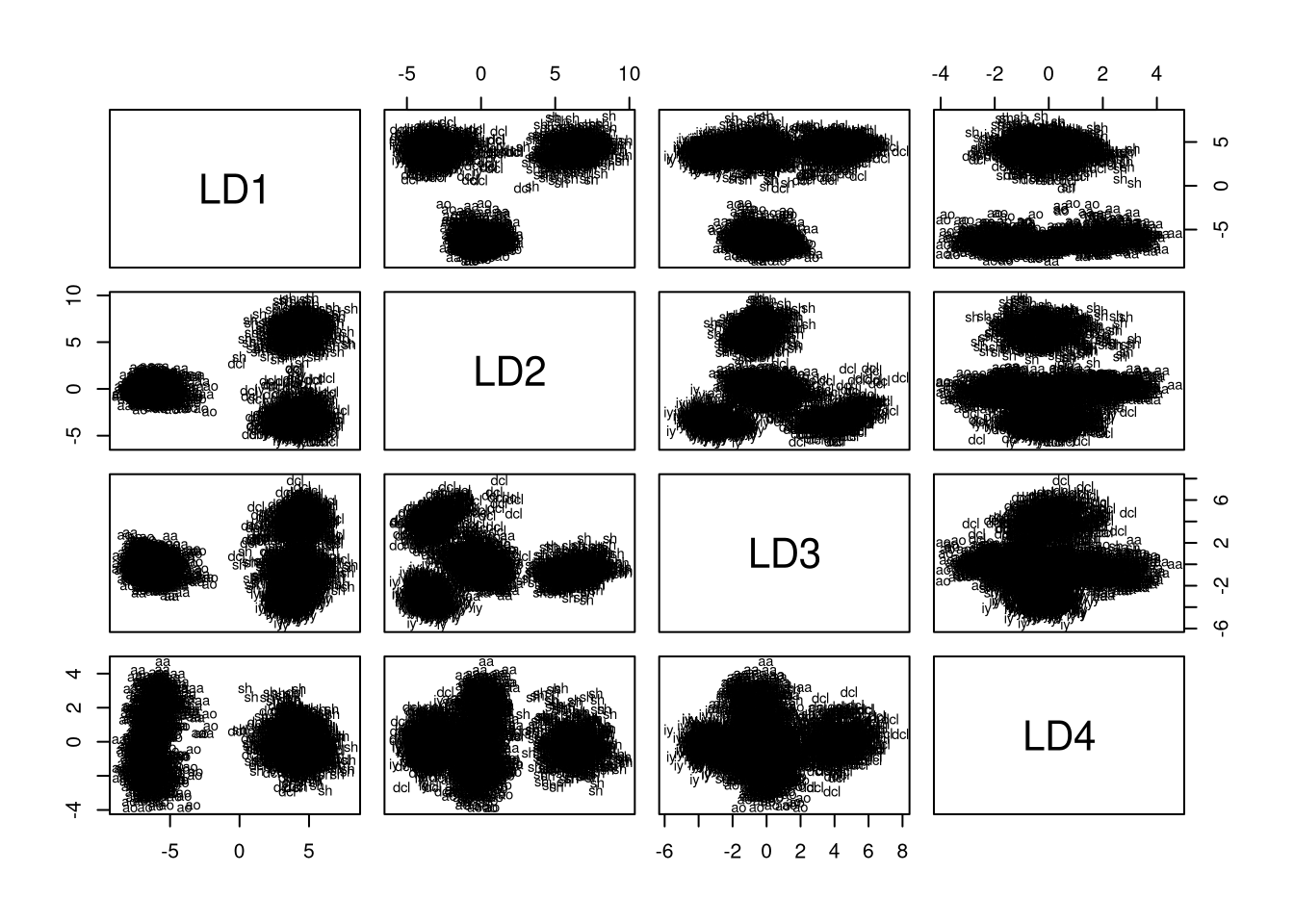
我们还可以使用plot.lda函数绘制训练数据到所有判别变量对的映射,其中dimen参数可用于指定所考虑的维数:
![]() ?
?
绘制所有维度对的训练数据表明,通过构造,捕获大部分方差。使用该图,我们可以获得关于我们应该为降低等级LDA选择的维数的直觉。请记住,LD1和LD2混淆AA与AO和DCL与IY。因此,我们需要额外的维度来区分这些群体。看一下这些图,似乎我们确实需要所有这四个维度,因为dcl和iy在LD1和LD3之间只是很好地分开,而当LD4与任何其他维度结合时,aa和ao只是很好地分开。
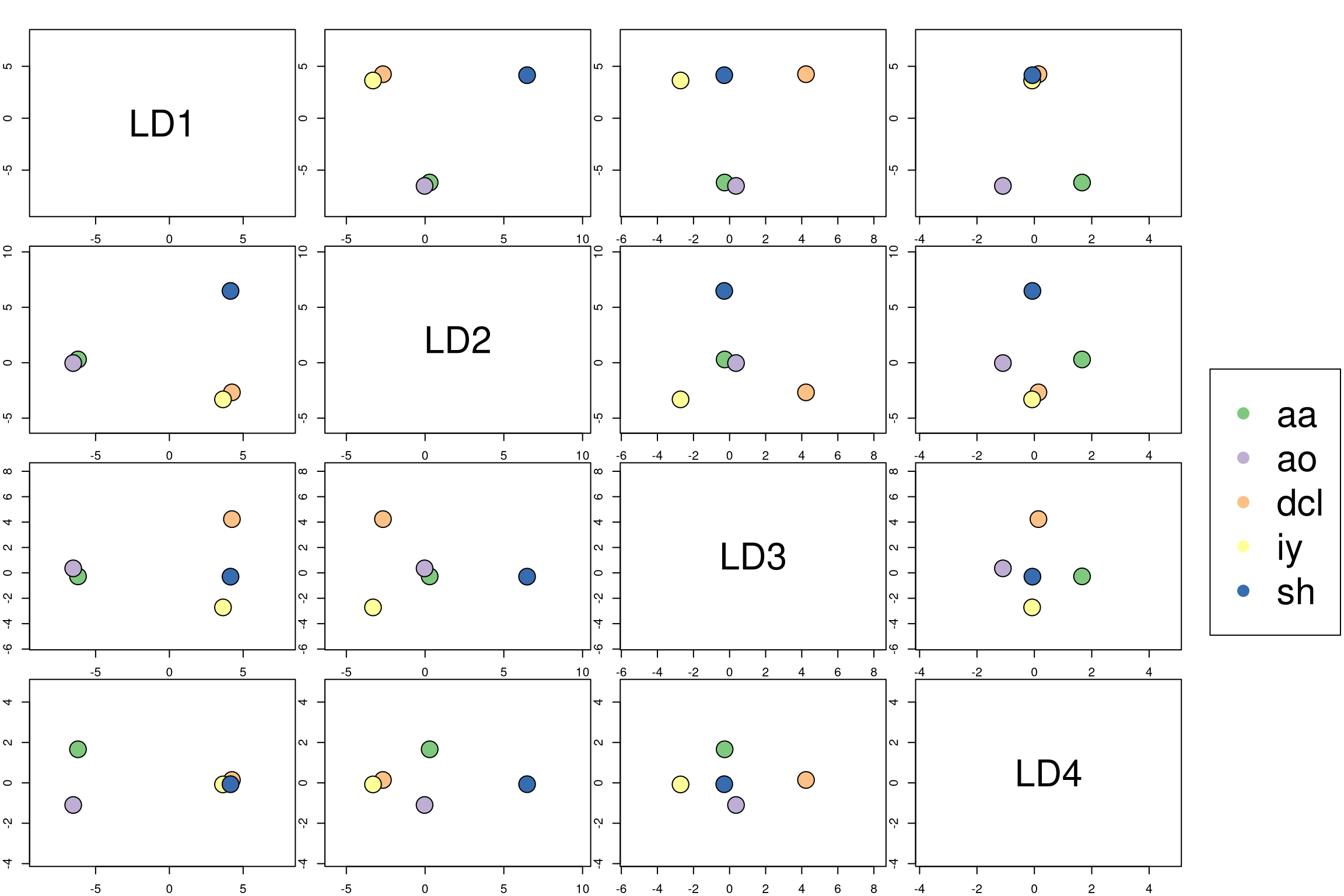
为了可视化组的质心,我们可以创建自定义图:
![]() ?
?
解释后验概率
除了将数据转换为由分量x提供的判别变量之外,预测函数还给出后验概率,其可以用于分类器的进一步解释。例如:
## [1] "Posterior of predicted class ‘sh‘ is: 1"## aa ao dcl iy sh
## aa 0.797 0.203 0.000 0.000 0.000
## ao 0.123 0.877 0.000 0.000 0.000
## dcl 0.000 0.000 0.985 0.014 0.002
## iy 0.000 0.000 0.001 0.999 0.000
## sh 0.000 0.000 0.000 0.000 1.000各个班级的后验表格表明该模型对音素aa和ao最不确定,这与我们对可视化的期望一致。
LDA作为分类器
如前所述,LDA的好处是我们可以选择用于分类的规范变量的数量。在这里,我们仍将通过使用多达四个规范变量进行分类来展示降级LDA的使用。
## Rank Accuracy
## 1 1 0.51
## 2 2 0.71
## 3 3 0.86
## 4 4 0.92正如从变换空间的视觉探索所预期的那样,测试精度随着每个附加维度而增加。由于具有四维的LDA获得最大精度,我们将决定使用所有判别坐标进行分类。
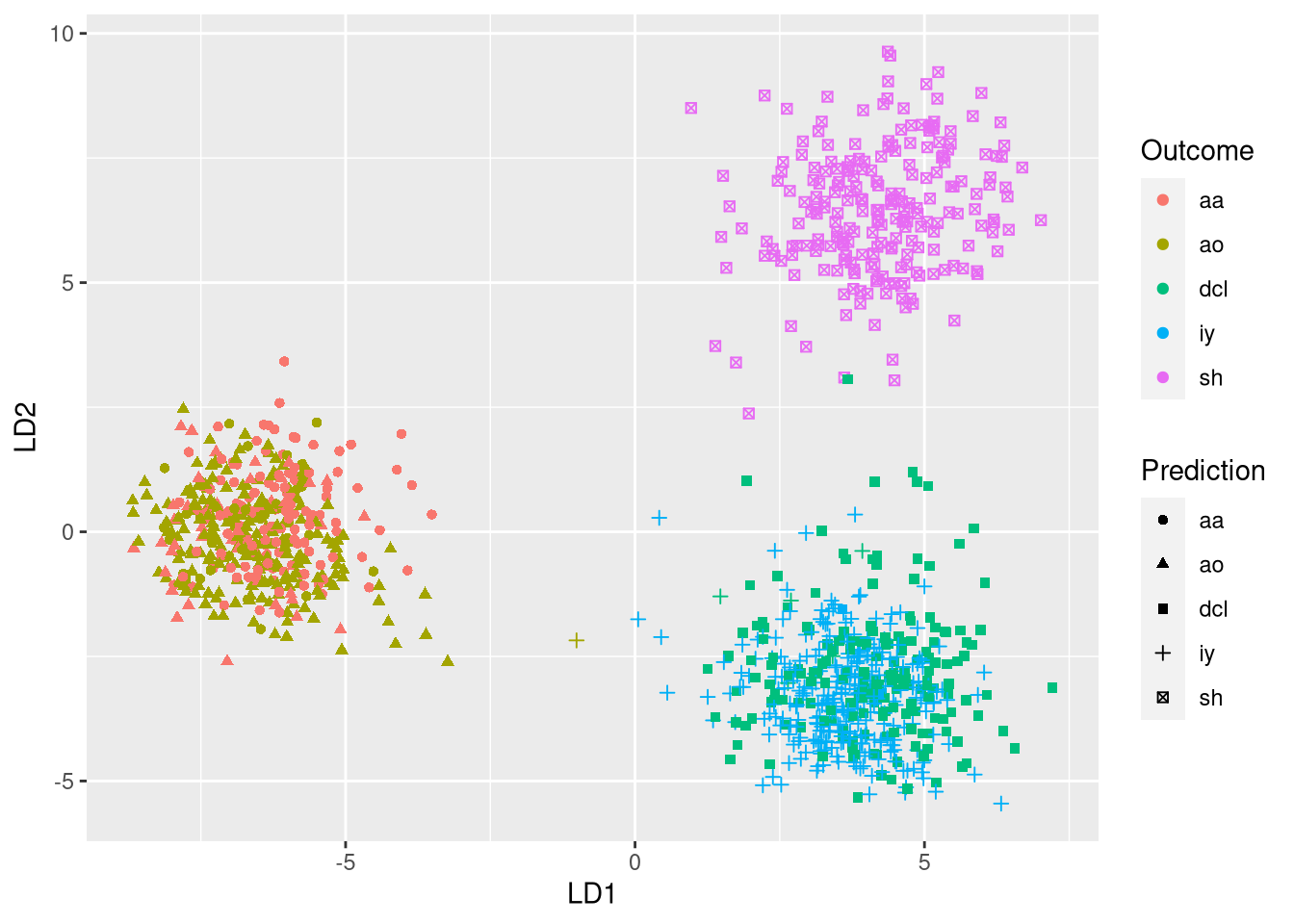
为了解释模型,我们可以可视化全等级分类器的性能:
![]() ?
?
在图中,预期的音素以不同的颜色显示,而模型预测通过不同的符号显示。具有100%准确度的模型将为每种颜色分配单个符号。因此,当单个颜色表现出不同的符号时,会发现不正确的预测。使用该图,我们很快发现,当标记为aa的观察被错误地分类为ao时,大多数混淆发生,反之亦然。
二次判别分析
QDA是LDA的变体,其中针对每类观察估计单个协方差矩阵。如果事先知道个别类别表现出不同的协方差,则QDA特别有用。QDA的缺点是它不能用作降维技术。
在QDA,我们需要估计ΣkΣk为每个类k∈{1,…,K}k∈{1,…,K}而不是假定Σk=ΣΣk=Σ如LDA。LDA的判别函数在xx是二次的:
δ?(x )= - 12日志| Σ?| -12(x - μ?)?Σ- 1?(x - μ?)+ 日志π?。δk(x)=−12log?|Σk|−12(x−μk)TΣk−1(x−μk)+log?πk.
由于QDA估计每个类的协方差矩阵,因此它具有比LDA更多的有效参数。我们可以通过以下方式得出参数的数量。
- 我们需要?K类先验π?πk。由于Σ?i = 1π?= 1∑i=1Kπk=1,我们不需要为先验的一个参数。因此,先验者有?- 1K−1自由参数。
- 由于有?K质心,μkμk,与pp每个条目下,有KpKp与所述装置的参数。
- 从协方差矩阵,ΣkΣk,我们只需要考虑对角线上直角三角形。协方差矩阵的这个区域有p(p+1)2p(p+1)2元素。由于KK需要估算这样的矩阵,所以有Kp(p+1)2Kp(p+1)2与协方差矩阵有关的参数。
因此,QDA参数的有效数量是?- 1 + K.p + K.p (p + 1 )2K−1+Kp+Kp(p+1)2。
由于QDA参数的数量在pp是二次的,因此当特征空间很大时,应小心使用QDA。
QDA在R
我们可以通过以下方式执行QDA:
的QDA和LDA对象之间的主要区别是,QDA具有p×pp×p的变换矩阵对于每个类k∈{1,…,K}k∈{1,…,K}。这些矩阵确保组内协方差矩阵是球形的,但不会导致子空间减小。因此,QDA不能用作可视化技术。
让我们确定QDA在音素数据集上是否优于LDA:
## [1] "Accuracy of QDA is: 0.84"QDA的准确度略低于全级LDA的准确度。这可能表明共同协方差的假设适合于该数据集。
规范的判别分析
RDA是LDA和QDA之间的折衷,因为它收缩ΣkΣk到合并方差ΣΣ通过定义
Σ^?(α )= α &Sigma;^?+ (1 - α )Σ^Σ^k(α)=αΣ^k+(1−α)Σ^
和更换Σ?与Σ?(α)中的判别函数。在此,α&Element;[0,1]是调谐参数确定是否协方差应该被独立地估计(α=1),还是应该被汇集(α=0)。Σ^?Σ^kΣ^?(α )Σ^k(α)α &Element; [ 0 ,1 ]α∈[0,1]α = 1α=1α=0α=0
另外Σ^Σ^也可朝向所述标量协方差通过要求缩水
Σ^(γ)= γΣ^+ (1 - γ)σ^2 Σ^(γ)=γΣ^+(1−γ)σ^2I
γ= 1γ=1γ=0γ=0Σ^kΣ^kΣ^(α ,γ)Σ^(α,γ)
由于RDA是一种正则化技术,因此当存在许多潜在相关的特征时,它尤其有用。现在让我们评估音素数据集上的RDA。
R中的RDA
<span style="color:#000000"><span style="color:#000000"><code>rda.preds <- predict(rda.model, t(train.set), train.responses, t(test.set))
<span style="color:#888888"># determine performance for each alpha:</span>
rda.perf <- vector(<span style="color:#880000">"list"</span>, dim(rda.preds)[<span style="color:#880000">1</span>])
<strong>for</strong> (i <strong>in</strong> seq(dim(rda.preds)[<span style="color:#880000">1</span>])) {
<span style="color:#888888"># performance for each gamma</span>
res <- apply(rda.preds[i,,], <span style="color:#880000">1</span>, <strong>function</strong>(x) length(which(x == as.numeric(test.responses))) / length(test.responses))
rda.perf[[i]] <- res
}
rda.perf <- do.call(rbind, rda.perf)
rownames(rda.perf) <- alphas</code></span></span>结论
判别分析对于多类问题特别有用。LDA非常易于理解,因为它可以减少维数。使用QDA,可以建模非线性关系。RDA是一种正则化判别分析技术,对大量特征特别有用。除了这些方法之外,还存在基于判别式的其他技术,例如灵活判别分析,惩罚判别分析和混合判别分析。
有问题吗?联系我们!
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() ?QQ:3025393450
?QQ:3025393450


![]() ?
?
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询服务
![]() ?
?

以上是关于R语言中多分类问题 multicalss classification 的性能测量的主要内容,如果未能解决你的问题,请参考以下文章
多类别分类(Multicalss Classification)