一个让业务开发效率提高10倍的golang库
Posted yjf512
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个让业务开发效率提高10倍的golang库相关的知识,希望对你有一定的参考价值。
一个让业务开发效率提高10倍的golang库
此文除了是标题党,没有什么其他问题。
这篇文章推荐一个库,https://github.com/jianfengye/collection。 这个库是我在开发业务过程中 Slice 的频繁导致业务开发效率低,就产生了要做一个 Collection 包的想法。本文说说我开发这个库的前因后果
Golang 适不适合写业务?
最近一个逻辑非常复杂的业务,我用 Golang 来开发。开发过程不断在问一个问题,Golang 适不适合写业务?
业务说到底,是一大堆的逻辑,大量的逻辑都是在几个环节:获取数据,封装数据,组织数据,过滤数据,排序结果。获取/封装数据,即从 DB 中根据查询 SQL,获取表中的数据,并封装成数据结构。组织数据,例如,当我有两份数据源,我需要将两份数据源按照某个字段合并,那么这种组织数据的能力也是非常需要的。过滤数据,我获取的字段有10个,但是我只需要给前端返回3个就够了;排序结果,返回的结构按照某种顺序。这些都是我们在写业务中,每个业务逻辑都会遇到的问题。一款适合做业务的语言一定是在这些环节上都提供足够的便利性的。

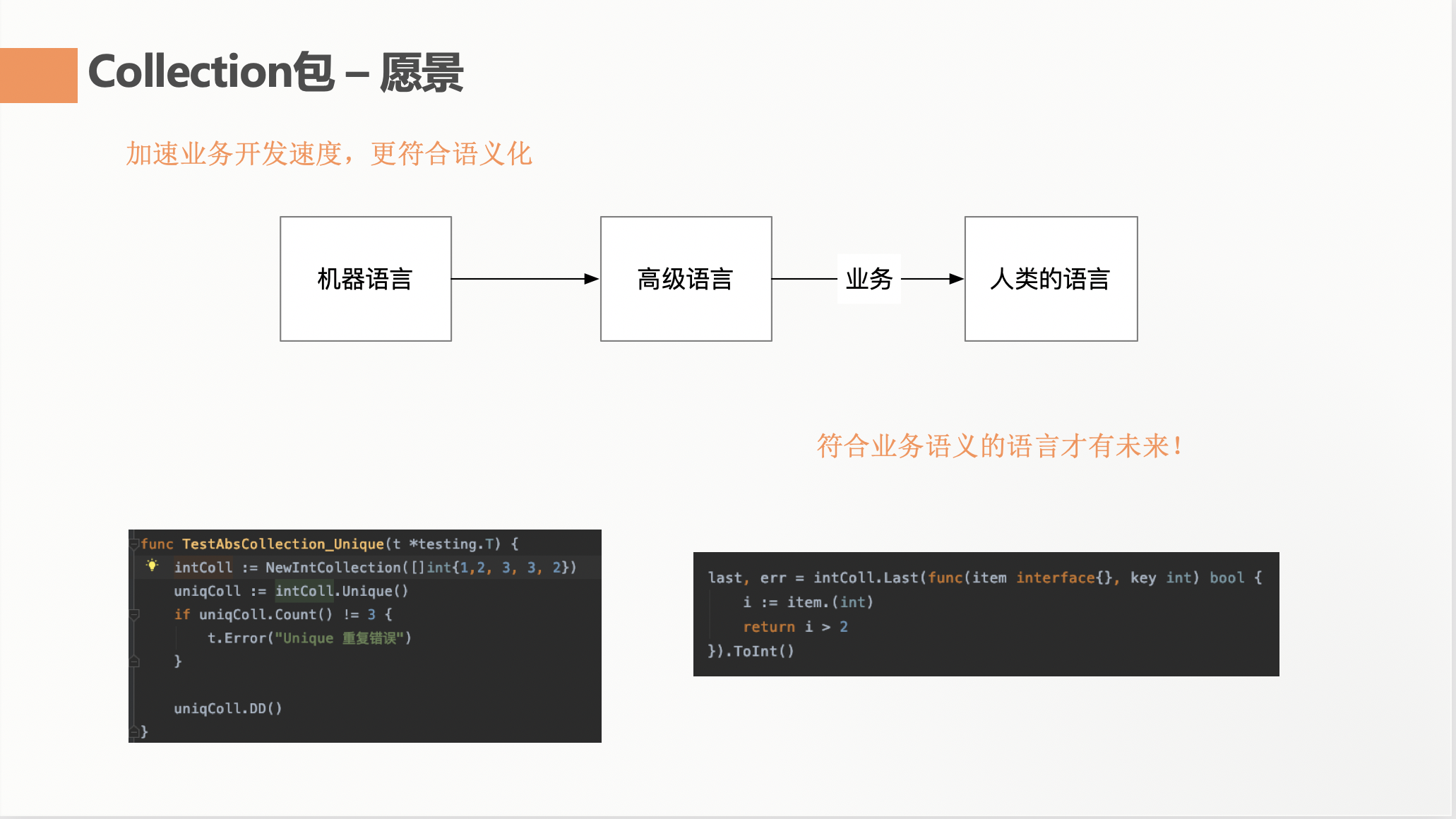
我想,符合业务语义的语言才有未来!!
什么是业务语义呢?就是我们开发人员和产品人员交流的语言。感受一下,比如 “将这个名单中成绩按照从大到小排列,并且成绩大于60的最后一个学生找出来” 这么一句话的需求,就是我们常常和产品人员交流的语言。而我们开发中使用到的语言/框架/库,又是一种思维和语言。当我们接到上述的需求,如果我们头脑中浮现的逻辑是“我要使用快速排序,然后在快速排序循环中能直接找到成绩大于60的,还要是最后一个,所以我可能需要有个 min 变量”。那么我只能说,或许你的代码运行效率足够高,但是一旦业务复杂了,你的代码开发效率一定很低。像上述的需求,我们按照伪码来说,最希望是有一门语言能支持:collection().sortDesc().Last(score > 60) 这样符合业务语义的代码。
如图,如果说高级语言是拉近了机器语言和业务语义的距离,那么开发Collection包的愿景也是希望拉近 Golang 这门高级语言和 业务语言的距离。
Collection包目标是用于替换golang原生的Slice,使用场景是在大量不追求极致性能,追求业务开发效能的场景。
展示
业务开发最核心的也就是对数组的处理,Collection封装了多种数据数组类型。
Collection包目前支持的元素类型:int, int64, float32, float64, string, struct。除了struct数组使用了反射之外,其他的数组并没有使用反射机制,效率和易用性得到一定的平衡。
使用下列几个方法进行初始化Collection:
NewIntCollection(objs []int) *IntCollection
NewInt64Collection(objs []int64) *Int64Collection
NewFloat64Collection(objs []float64) *Float64Collection
NewFloat32Collection(objs []float32) *Float32Collection
NewStrCollection(objs []string) *StrCollection
NewObjCollection(objs interface{}) *ObjCollection所有的初始化函数都是很方便的将要初始化的slice传递进入,返回了一个实现了ICollection的具体对象。
下面做一些Collection中函数的展示。
友好的格式展示
首先业务是很需要进行代码调试的,这里封装了一个 DD 方法,能按照友好的格式展示这个 Collection
a1 := Foo{A: "a1"}
a2 := Foo{A: "a2"}
objColl := NewObjCollection([]Foo{a1, a2})
objColl.DD()
/*
ObjCollection(2)(collection.Foo):{
0: {A:a1}
1: {A:a2}
}
*/
intColl := NewIntCollection([]int{1,2})
intColl.DD()
/*
IntCollection(2):{
0: 1
1: 2
}
*/查找功能
在一个数组中查找对应的元素,这个是非常常见的功能
Search(item interface{}) int查找Collection中第一个匹配查询元素的下标,如果存在,返回下标;如果不存在,返回-1
注意 此函数要求设置compare方法,基础元素数组(int, int64, float32, float64, string)可直接调用!
intColl := NewIntCollection([]int{1,2})
if intColl.Search(2) != 1 {
t.Error("Search 错误")
}
intColl = NewIntCollection([]int{1,2, 3, 3, 2})
if intColl.Search(3) != 2 {
t.Error("Search 重复错误")
}排重功能
将Collection中重复的元素进行合并,返回唯一的一个数组。
intColl := NewIntCollection([]int{1,2, 3, 3, 2})
uniqColl := intColl.Unique()
if uniqColl.Count() != 3 {
t.Error("Unique 重复错误")
}
uniqColl.DD()
/*
IntCollection(3):{
0: 1
1: 2
2: 3
}
*/获取最后一个
获取该Collection中满足过滤的最后一个元素,如果没有填写过滤条件,默认返回最后一个元素
intColl := NewIntCollection([]int{1, 2, 3, 4, 3, 2})
last, err := intColl.Last().ToInt()
if err != nil {
t.Error("last get error")
}
if last != 2 {
t.Error("last 获取错误")
}
last, err = intColl.Last(func(item interface{}, key int) bool {
i := item.(int)
return i > 2
}).ToInt()
if err != nil {
t.Error("last get error")
}
if last != 3 {
t.Error("last 获取错误")
}Map & Reduce
Map
Map(func(item interface{}, key int) interface{}) ICollection
对Collection中的每个函数都进行一次函数调用,并将返回值组装成ICollection
这个回调函数形如: func(item interface{}, key int) interface{}
如果希望在某此调用的时候中止,就在此次调用的时候设置Collection的Error,就可以中止,且此次回调函数生成的结构不合并到最终生成的ICollection。
intColl := NewIntCollection([]int{1, 2, 3, 4})
newIntColl := intColl.Map(func(item interface{}, key int) interface{} {
v := item.(int)
return v * 2
})
newIntColl.DD()
if newIntColl.Count() != 4 {
t.Error("Map错误")
}
newIntColl2 := intColl.Map(func(item interface{}, key int) interface{} {
v := item.(int)
if key > 2 {
intColl.SetErr(errors.New("break"))
return nil
}
return v * 2
})
newIntColl2.DD()
/*
IntCollection(4):{
0: 2
1: 4
2: 6
3: 8
}
IntCollection(3):{
0: 2
1: 4
2: 6
}
*/Reduce
Reduce(func(carry IMix, item IMix) IMix) IMix
对Collection中的所有元素进行聚合计算。
如果希望在某次调用的时候中止,在此次调用的时候设置Collection的Error,就可以中止调用。
intColl := NewIntCollection([]int{1, 2, 3, 4})
sumMix := intColl.Reduce(func(carry IMix, item IMix) IMix {
carryInt, _ := carry.ToInt()
itemInt, _ := item.ToInt()
return NewMix(carryInt + itemInt)
})
sumMix.DD()
sum, err := sumMix.ToInt()
if err != nil {
t.Error(err.Error())
}
if sum != 10 {
t.Error("Reduce计算错误")
}
/*
IMix(int): 10
*/排列
将Collection中的元素进行升序排列输出
intColl := NewIntCollection([]int{2, 4, 3})
intColl2 := intColl.Sort()
if intColl2.Err() != nil {
t.Error(intColl2.Err())
}
intColl2.DD()
/*
IntCollection(3):{
0: 2
1: 3
2: 4
}
*/合并
Join(split string, format ...func(item interface{}) string) string
将Collection中的元素按照某种方式聚合成字符串。该函数接受一个或者两个参数,第一个参数是聚合字符串的分隔符号,第二个参数是聚合时候每个元素的格式化函数,如果没有设置第二个参数,则使用fmt.Sprintf("%v")来该格式化
intColl := NewIntCollection([]int{2, 4, 3})
out := intColl.Join(",")
if out != "2,4,3" {
t.Error("join错误")
}
out = intColl.Join(",", func(item interface{}) string {
return fmt.Sprintf("'%d'", item.(int))
})
if out != "'2','4','3'" {
t.Error("join 错误")
}核心
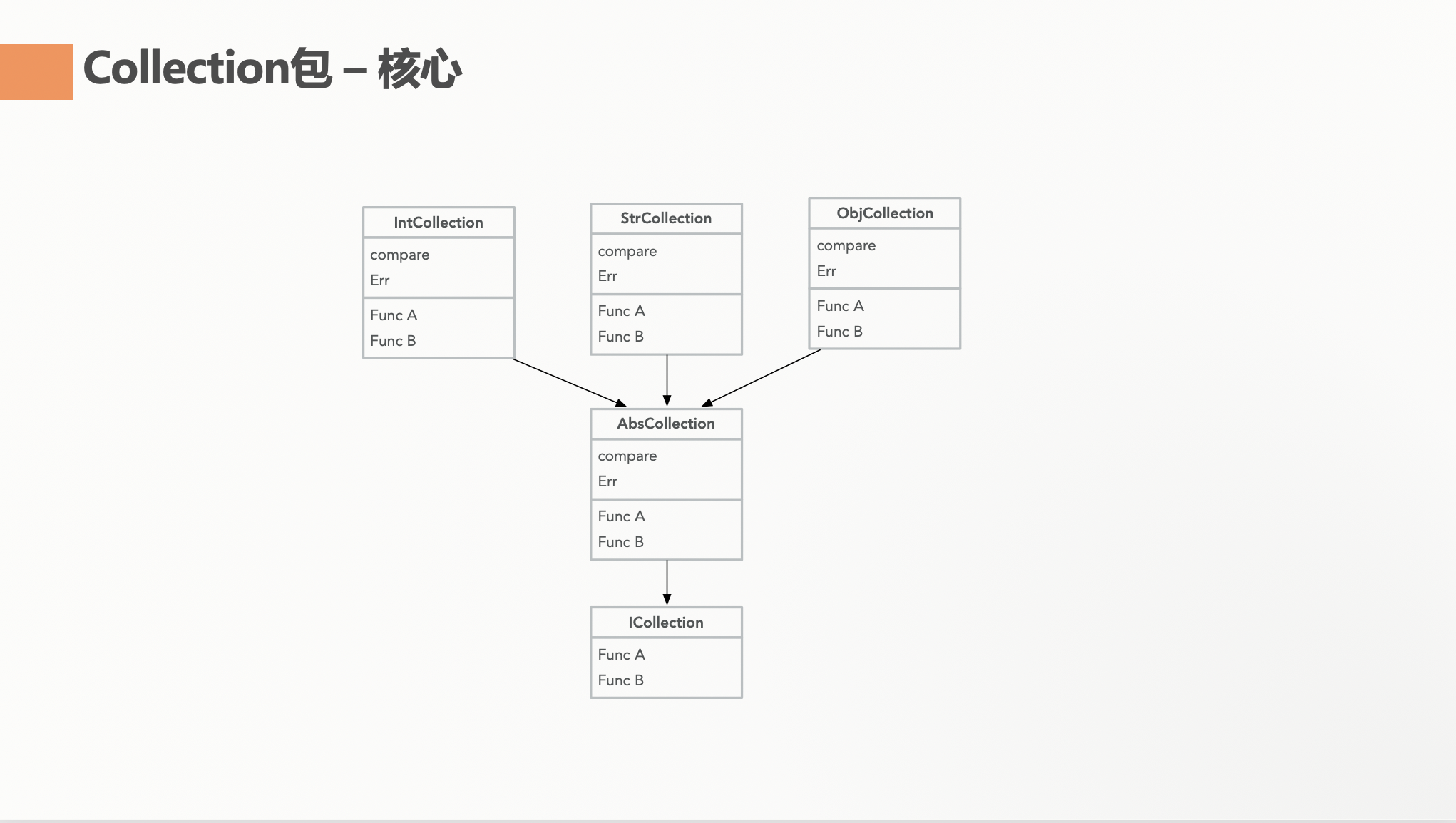
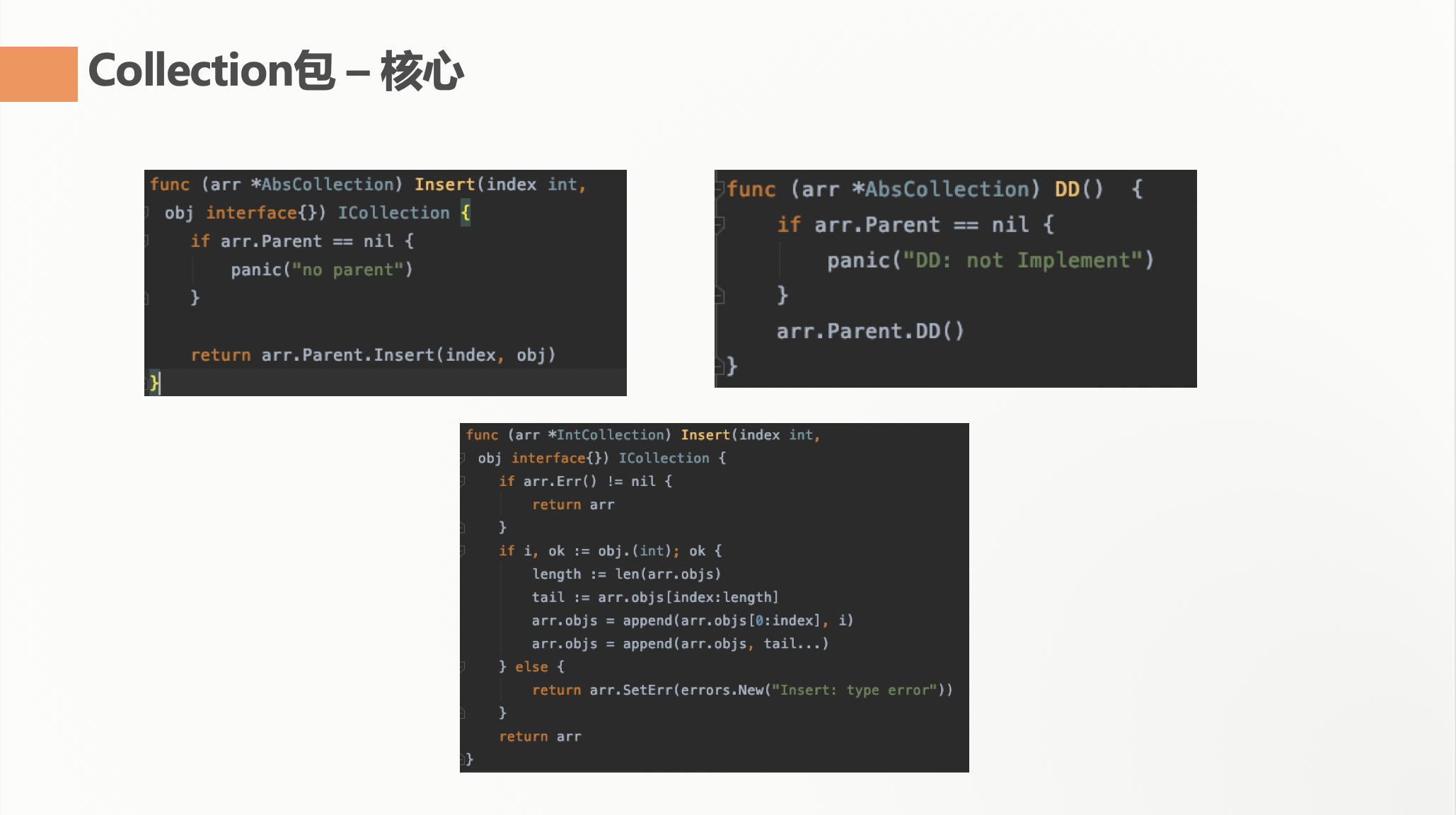
继承
Collection 包的核心思想也就是继承。但是在 Golang 中的继承,特别是抽象类是没有办法实现的。我这里使用了实现了自身接口的属性Parent来实现的。
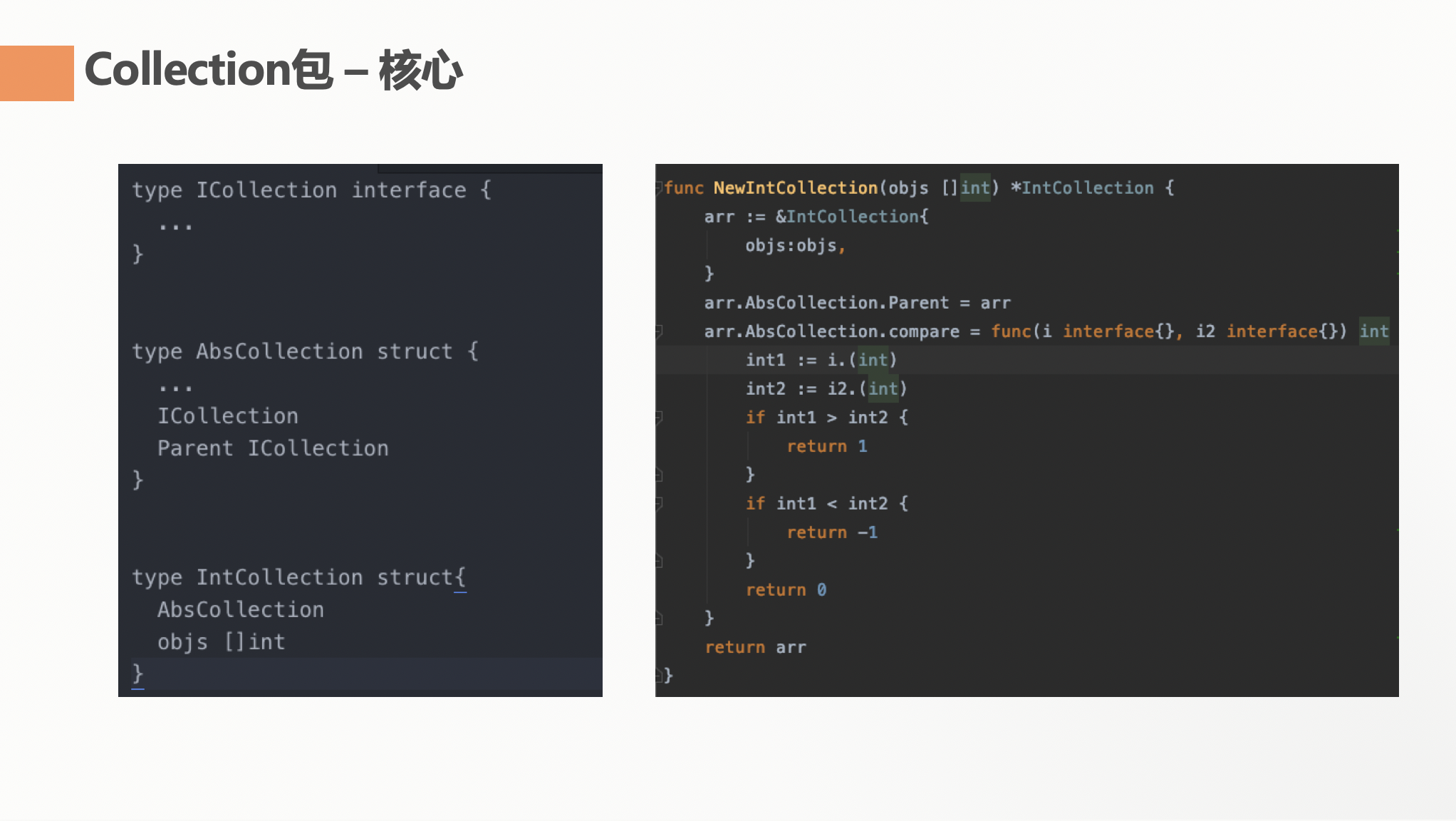
首先定义 ICollection 接口,在这个接口中定义好所有的方法。其次创建了 AbsCollection 这个 struct。首先它自身实现了 ICollection 方法,其次,它有个 Parent 属性实现了 ICollection方法,这个 Parent 属性是存放指向真正的实现类的方法,比如 IntCollection。最后,IntCollection/Float32Collection 等都是实现了 AbsCollection。这里显式写实现了 AbsCollection 有几个好处,一个是强制必须实现 ICollection的方法,其次,一些在具体实现类中不一样的方法,可以在实现类中重写了。并且最后,为每个实现类实现了一个New方法。
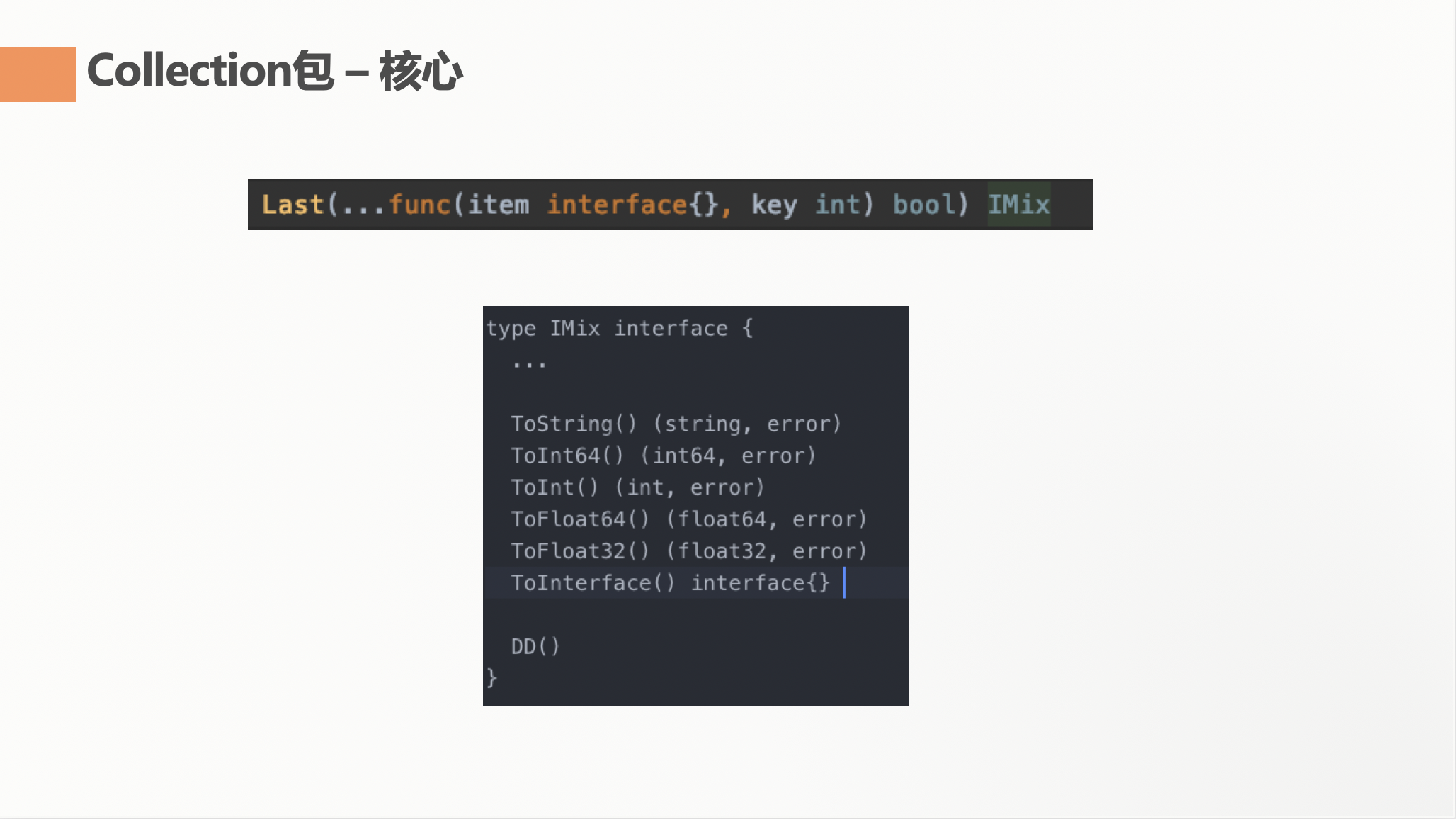
IMix
当然,由于是强类型语言,很多函数在定义的时候,返回值是无法确定类型的,当然这里可以简单的使用一个interface来做,但是这样易用性其实又降低了,每次函数调用就必须坐下类型判断。再加上后续回说到的 error 处理的问题。所以我设计了一个 IMix 接口,由实现了这个接口的对象来进行类型转换,ToString, ToInt64 等。当然我也为 IMix 设计了 DD() 方便调试的方法。
AbsCollection
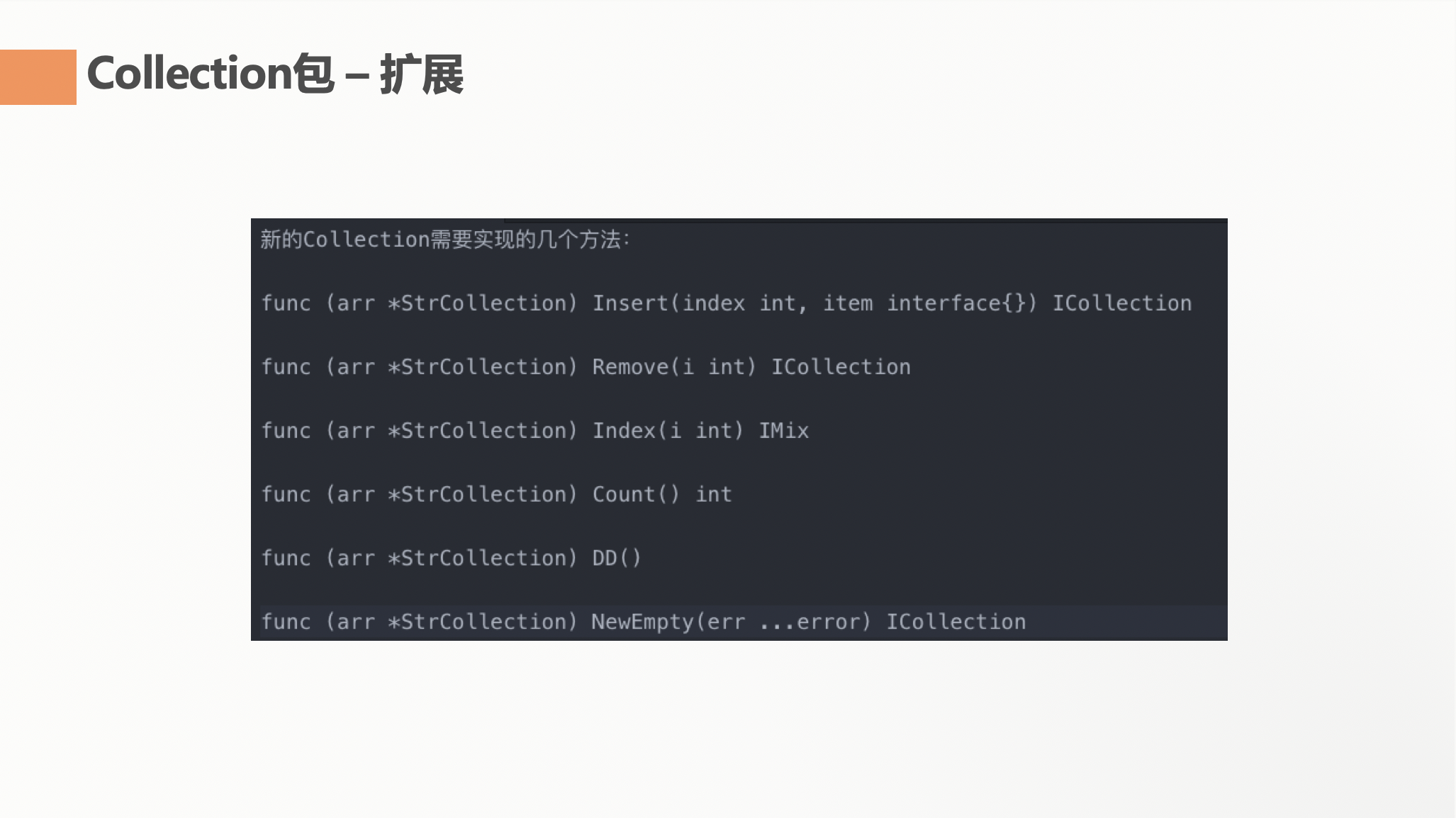
上面说了继承,AbsCollection 是我定位的抽象类,它的思想是一生二,二生万物的思想。就是有一些原子方法(比如Insert方法)是根据不同的数组对象而不同的。这些方法在AbsCollection 层的实现就是调用 Parent 的具体实现方法。而其他的 AbsCollection 中的通用方法则使用这些原子进行实现。
一共给具体的父实现类定义了6个方法,后续一旦有新的类型添加的需求,只需要保证他能实现了这6个方法即可使用其他的方法了。
特色
下面说说这个包设计的一些特色。
可选参数
Collection 使用了大量的可选参数,比如 Collection.Slice方法。
Slice(...int) ICollection
获取Collection中的片段,可以有两个参数或者一个参数。
如果是两个参数,第一个参数代表开始下标,第二个参数代表结束下标,当第二个参数为-1时候,就代表到Collection结束。
如果是一个参数,则代表从这个开始下标一直获取到Collection结束的片段。
intColl := NewIntCollection([]int{1, 2, 3, 4, 5})
retColl := intColl.Slice(2)
if retColl.Count() != 3 {
t.Error("Slice 错误")
}
retColl.DD()
retColl = intColl.Slice(2,2)
if retColl.Count() != 2 {
t.Error("Slice 两个参数错误")
}
retColl.DD()
retColl = intColl.Slice(2, -1)
if retColl.Count() != 3 {
t.Error("Slice第二个参数为-1错误")
}
retColl.DD()
/*
IntCollection(3):{
0: 3
1: 4
2: 5
}
IntCollection(2):{
0: 3
1: 4
}
IntCollection(3):{
0: 3
1: 4
2: 5
}
*/
是否使用可选方法我纠结了很久,因为这种可选参数毕竟还是不够美观的。不过后来还是想到了Collection这个包的设计宗旨是方便业务开发。那么业务开发使用者使用的爽的程度才是这个包应该关心的,所以也就大量使用了这种对使用者灵活友好,但是略不美观的实现方式。

链式调用 & 错误处理
链式调用是我在实现这个包的时候一直坚持的。因为复杂的业务逻辑,链式调用的写法阅读性是很高的。所以在所有能返回数组的函数中,我都返回了 ICollection 接口。以方便于后续调用。
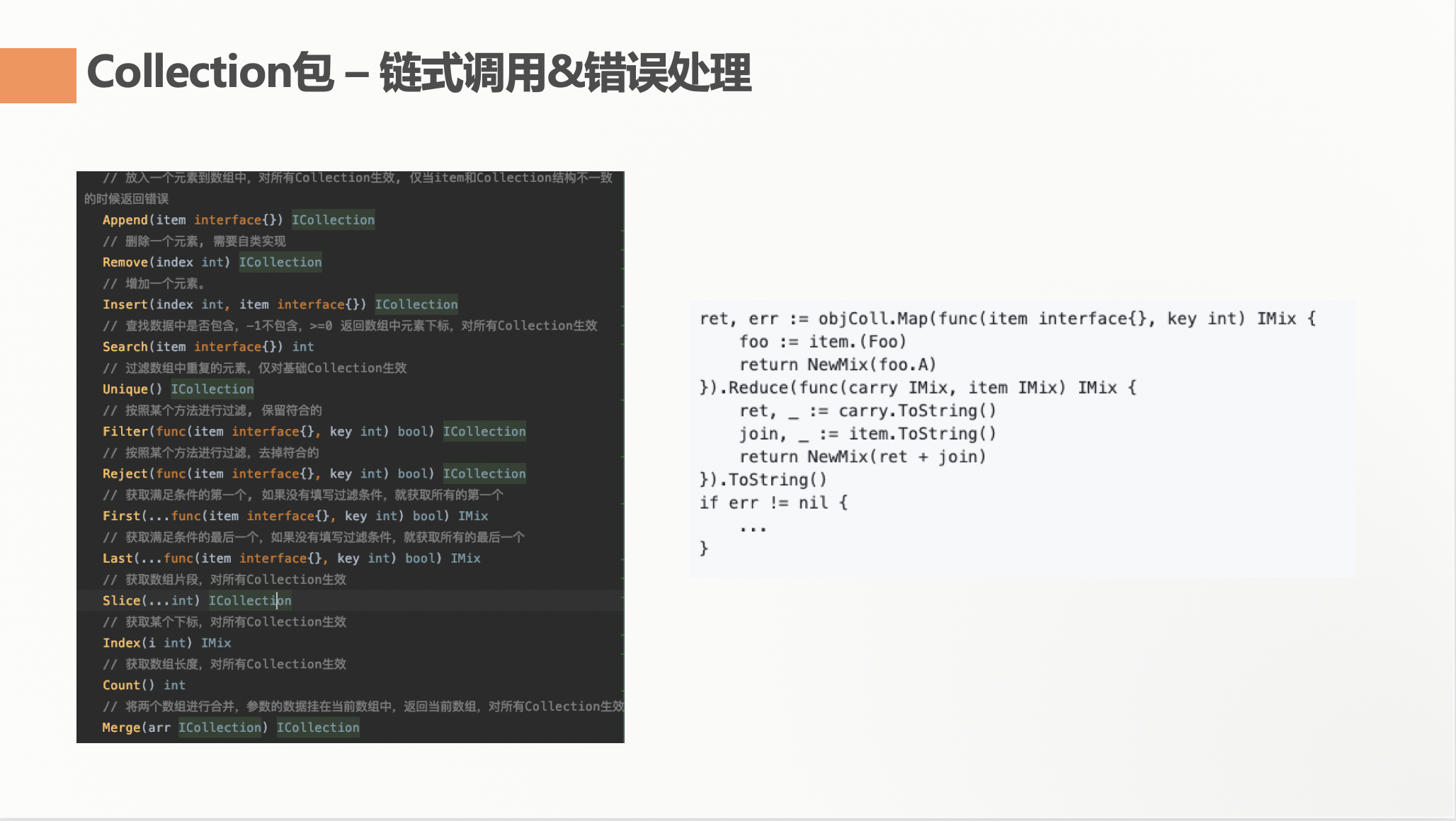
但是 Golang 中还有一个 error 的处理问题。每个函数调用其实都是有可能有错误的,这个错误如果直接返回,那么链式调用必然就不可行了。我采用的方式是火丁[文章]中说到的错误处理机制。当错误出现的时候,我把错误挂载在当前或者返回的 IColleciton,或者返回的 IMix 中。并且提供了 Error() 方法来让外部用户获取确认这个链式调用是否有错误。
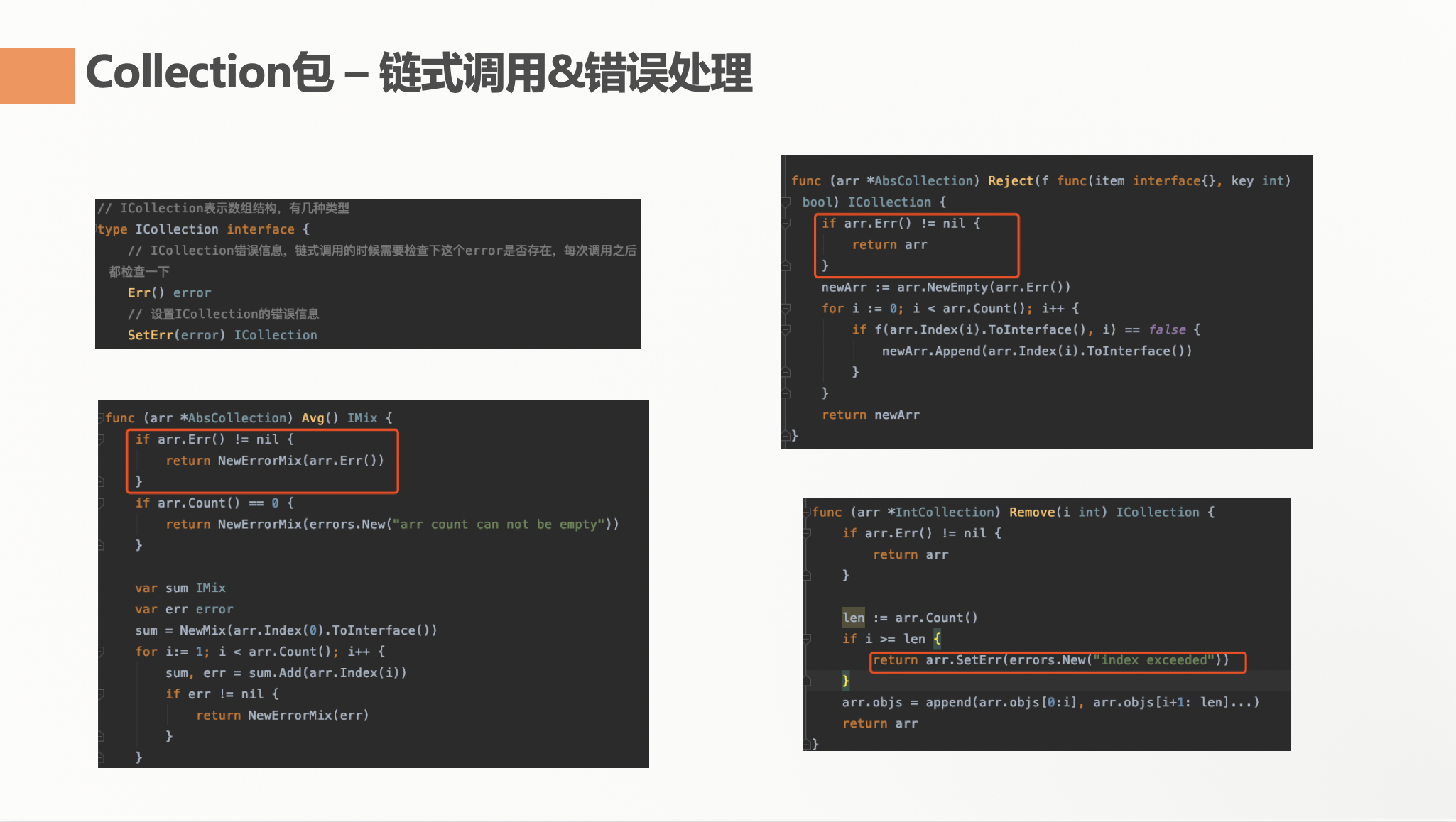
这样的错误处理机制是我现在能想到的最好的处理机制了(在 Go 2.0 handle error没有出来之前)。它一方面兼顾了链式调用,一方面能进行错误检查。当然这种方式的错误检查机制等于弱化,不是在每次调用函数的时候强制用户检查了,而是在链式调用之后,建议用户检查。但是回到 Collection 库的愿景,这样的实现会让使用者更为舒适。
compare
数组当然有个compare函数,这个函数我设计作为匿名函数放在 AbsCollection 中,具体的实现在每个实现类的 New 函数中进行设置。我也将这个 compare 函数的设置权限作为 SetCompare() 函数放给外部设置。主要考虑到扩展性,如果后续你的 Collection 是包的自己定义的一个复杂的 Object方法,那么你完全可以按照某个字段进行排序。
ObjCollection
对象数组是我最耗费精力的一个实现类。它大量使用了反射。但是这个是可以扩展的。由于接口中的方法的输入输出完全是 ICollection 接口。比如在初期,你使用 Collection 自带的 NewObjCollection 实例化了一个 ICollection, 或许你对使用了反射的 Insert,Pluck 方法的效率不是非常满意,那么,你只需要自己实现一个 ACollection, 并且自己实现上文说的6个方法,继承AbsCollection,那么,你就可以很方便的使用 Colleciton的其他方法,且没有反射。
New复制slice指针还是数组?
这个是我很后面加的,在 New 一个Collection的时候,Collection 中的数组元素,是选择将参数中的数组指针复制到 Colleciton 中,还是将参数中的整个数组复制到 Collection 中呢?后来我选择了后者。主要是考虑到安全性,NewCollection 的时候我复制一份,后续如果有对这个数组进行修改的操作,不会影响原先传入的参数Slice。为了一些安全性,牺牲一些内存,我认为还是值得的。

心路历程及后续
这个 Collection 包我也前后利用业余时间开发了挺久了。主要是实现的思想不断在变化,从最初的我将 error 以直接panic的方式保持链式调用,到希望实现一个 IMap 数据结构,到使用的是数组,还是指针等,包括名字我也从最初的IArray 改成ICollection(我希望从使用这个包开始,Collection就成为了这个包的关键字,所有接口和函数一旦设计到数组的概念的时候就使用Collection这个关键字)。

写一个通用库其实并不是那么容易的事情,最重要的是思想还有设计感。
这个库我目前就在我自己的项目组进行推广和使用。文中的PPT就是我在项目组推广时使用的PPT。目前已经打了1.0.1的tag。后续会持续优化,并且做一些文档补充。希望能成为最适合业务开发的 Collection 包。
再次推广下这个项目 https://github.com/jianfengye/collection,欢迎使用和提PR。熟练使用之后,它一定会让你的业务开发效率提升一个档次的。
以上是关于一个让业务开发效率提高10倍的golang库的主要内容,如果未能解决你的问题,请参考以下文章