pandas的基本用法
Posted zydlh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas的基本用法相关的知识,希望对你有一定的参考价值。
Pandas是一款数据分析工具。它内置了大量用于数据分析的方法,如:max、min、sqrt、groupby等。它最基本的数据类型只有Series和DataFrame两种。
1. Series:称为系列,我们可以看作是竖起来的list,相当于Excel表格中的一列。它常见的操作有:
在进行操作之前,需要先导入【pandas】模块:
import pandas as pd
①创建操作
| 方法 | 说明 | 举例 |
| 利用列表初始化创建一个Series | 列表的元素对应于Series的值,其索引默认为从0开始的数字 |
s_from_list=pd.Series([1,2,3,4,5])
s_from_list2=pd.Series([‘aa‘,‘bb‘,‘cc‘,‘dd‘,‘ee‘])
|
| 利用列表初始化创建一个Series,并指定算定义的标签 | 列表的元素对应于Series的值,其数字索引仍然从0开始,但由于指定了自定义的标签,因此这个Series既有索引,还有标签,也称为双索引。 |
s_from_list=pd.Series([1,2,3,4,5],index=[‘A‘,‘B‘,‘C‘,‘D‘,‘E‘])
|
| 利用字典初始化创建一个Series | 由上面的两种方式来看,无论标签是自定义的,还是默认的索引,创建Series都不够灵活。由字典生成Series,则字典的键key变成了Series的标签,而字典的值value变成了Series的值。 |
s_from_dict=pd.Series({‘name‘:‘张炎‘,‘age‘:18,‘gender‘:True,‘hobby‘:‘编程‘})
|
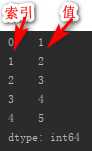
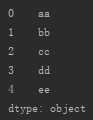
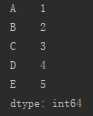
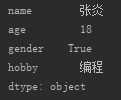
②Series查找操作:
| 操作目的 | 访问方式 | 举例 | |
| 访问单个元素 | 索引 |
s_from_list1=pd.Series([1,2,3,4,5]) 
|
|
| 标签 |
s_from_list2=pd.Series([1,2,3,4,5],index=[‘A‘,‘B‘,‘C‘,‘D‘,‘E‘])  |
||
| 访问多个元素 | 连续 |
切片 (索引切片或标签切片) (索引切片前闭后开) (标签切片前闭后闭) |
s_from_list1=pd.Series([1,2,3,4,5]) 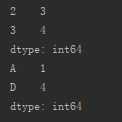
|
| 不连续 | 切片: 索引列表或标签列表 |
s_from_list1=pd.Series([1,2,3,4,5]) 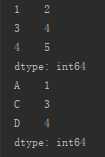
|
③增操作
只有append方法,没有insert方法。
append方法的参数必须也是一个Series对象,也就是说append的参数的类型必须是Series。
append方法不会改变原来Series对象的值,会生成一个新的Series对象。如:
s_from_list1=pd.Series([1,2,3,4,5])
add_s=pd.Series(6)
new_s=s_from_list1.append(add_s)
print(s_from_list1)
print(new_s)
print(new_s.index)
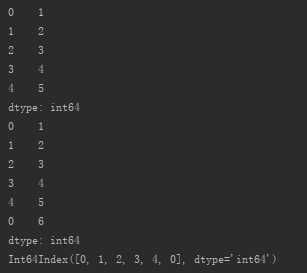
又如:
s_from_list1=pd.Series([1,2,3,4,5])
add_s=pd.Series(6,index=[7])
new_s=s_from_list1.append(add_s)
print(s_from_list1)
print(new_s)
print(new_s.index)
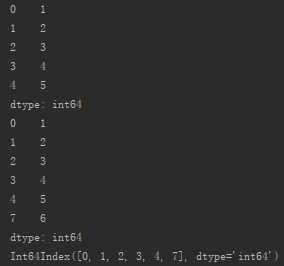
④删除操作
方法drop(索引或标签)。
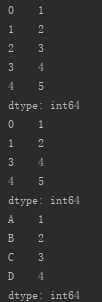
s_from_list1=pd.Series([1,2,3,4,5])
droped=s_from_list1.drop(2)
print(s_from_list1)
print(droped)
s_from_list2=pd.Series([1,2,3,4,5],index=[‘A‘,‘B‘,‘C‘,‘D‘,‘E‘])
droped=s_from_list2.drop(‘E‘)
print(droped)
注:,如果索引或标签不存在,则报错,如:
droped=s_from_list2.drop(‘G‘)

如果指定了标签,则不能用索引去删除,必须用标签去删除,否则报错,如:
s_from_list2=pd.Series([1,2,3,4,5],index=[‘A‘,‘B‘,‘C‘,‘D‘,‘E‘])
droped=s_from_list2.drop(0)

⑤判某个值是否在Series里面
⑥修改操作
| 修改目的 | 方法 | 举例 |
| 修改单个元素 | 索引或标签 |
s_from_list2=pd.Series([1,2,3,4,5],index=[‘A‘,‘B‘,‘C‘,‘D‘,‘E‘]) 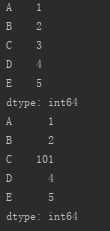
|
| 修改多个元素 | 切片 |
s_from_list2=pd.Series([1,2,3,4,5],index=[‘A‘,‘B‘,‘C‘,‘D‘,‘E‘]) 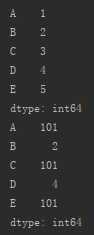 |
⑦重置索引操作
就是重新给Series对象s的index赋值,值为range(0,len(s)),如:
s.index=range(0,len(s))
⑧常用的属性
| 属性 | 说明 | 举例 |
| index |
查看所有索引, 该属性的数据类型是:pandas.core.indexes.base.Index |
s_from_list1=pd.Series([1,2,3,4,5],index=[‘A‘,‘B‘,‘C‘,‘D‘,‘E‘]) 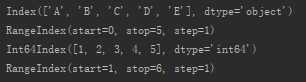 |
| values |
查看所有值,各个值之间用空格分隔, 该属性的数据类型是:numpy.ndarray |
s_from_list1=pd.Series([1,2,3,4,5],index=[‘A‘,‘B‘,‘C‘,‘D‘,‘E‘]) 
|
2. DataFrame:相当于Excel中的一个Sheet表。
以上是关于pandas的基本用法的主要内容,如果未能解决你的问题,请参考以下文章