MNIST机器学习入门
Posted xiaoyh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MNIST机器学习入门相关的知识,希望对你有一定的参考价值。
在前一个博客中,我们已经对MNIST 数据集和TensorFlow 中MNIST 数据集的载入有了基本的了解。本节将真正以TensorFlow 为工具,写一个手写体数字识别程序,使用的机器学习方法是Softmax 回归。
一、Softmax回归的原理
Softmax 回归是一个线性的多类分类模型,实际上它是直接从Logistic回归模型转化而来的。区别在于Logistic 回归模型为两类分类模型,而Softmax 模型为多类分类模型。
在手写体识别问题中, 一共有10 个类别( 0~9 ),我们希望对输入的图像计算它属于每个类别的概率。如属于9 的概率为70% ,属于1 的概率为10%等。最后模型预测的结果就是概率最大的那个类别。
先来了解什么是Softmax 函数。Softmax 函数的主要功能是将各个类别的“打分”转化成合理的概率值。例如,一个样本可能属于三个类别:第一个类别的打分为a,第二个类别的打分为b,第三个类别的打分为c。打分越高代表属于这个类别的概率越高,但是打分本身不代表概率,因为打分的值可以是负数,也可以很大,但概率要求值必须在0~ 1 ,并且三类的概率加起来应该等于1 。那么,如何将(a, b, c)转换成合理的概率值呢?方法就是使用Softmax 函数。例如,对(a, b, c)使用Softmax 函数后,相应的值会变成
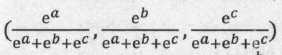
也就是说,第一类的概率可以用第一个值表示,第二类的概率可以用第二个值表示,第三类的概率可以用第三个值表示。显然,这三个数值都在0~1之间,并且加起来正好等于1,是合理的概率表示。
假设x 是单个样本的特征, W、b 是Softmax 模型的参数。在MNIST 数据集中, x 就代表输入图片,它是一个784 维的向量,而W 是一个矩阵, 它的形状为(784, 10),b 是一个10 维的向量, 10 代表的是类别数。Softmax 模型的第一步是通过下面的公式计算各个类别的Logit:Logit = WTx + b。
Logit 同样是一个10 维的向量,它实际上可以看成样本对应于各个类别的“打分” 。接下来使用Softmax 函数将包转换成各个类别的概率值:y = Softmax(Logit)
Softmax 模型输出的y 代表各个类别的概率,还可以直接用下面的式子来表示整个Softmax 模型:y = Softmax(Logit = WTx + b)
二、Softmax回归在TensorFlow中的实现
本节对应的程序为softmax_regression.py ,在该程序中,使用TensorFlow定义了一个Softmax 模型,实现了MNIST 数据集的分类。首先导入TensorFlow 模块:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
下面的步骤是非常关键的几步,先来看代码:
# 创建x,x是一个占位符(placeholder),代表待识别的图片 x = tf.placeholder(tf.float32,[None,784]) # w是Softmax模型的参数,将一个784维的输入转换为10维的输出 # 在TensorFlow中,模型的参数用tf.Variable表示 w = tf.Variable(tf.zeros([784,10])) # b是又一个Softmax模型的参数,一般叫做“偏置顶”(bias) b = tf.Variable(tf.zeros([10])) # y 表示模型的输出 y = tf.nn.softmax(tf.matmul(x,w)+b) # y_是实际的图像标签,同样以占位符表示 y_ = tf.placeholder(tf.float32,[None,10])
这里定义了一些占位符和变量(Variable )。在TensorFlow 中,无论是占位符还是变量, 它们实际上都是“ Tensor”。从TensorFlow 的名字中,就可以看出Tensor 在整个系统中处于核心地位。TensorFlow 中的Tensor 并不是具体的数值, 它只是一些我们“希望” TensorFlow 系统计算的“节点’。
这里的占位符和变量是不同类型的Tensor 。先来讲解占位符。占位符不依赖于其他的Tensor ,它的值由用户自行传递给TensorFlow ,通常用来存储样本数据和标签。如在这里定义了x = tf.placeholder(tf. float32, [None, 784]),它是用来存储训练图片数据的占位符。它的形状为[None, 784], None 表示这一维的大小可以是任意的,也就是说可以传递任意张训练图片给这个占位符,每张图片用一个784 维的向量表示。同样的, y_= tf.placeholder(tf.float32,[None, 10])也是个占位符,它存储训练图片的实际标签。
再来看什么是变量。变量是指在计算过程中可以改变的值,每次计算后变量的值会被保存下来,通常用变量来存储模型的参数。如这里创建了两个变量: W = tf.Variable(tf.zeros([784, 10 ])) 、b = tf.Variable(tf. zeros([10])) 。它们都是Softmax 模型的参数。创建变量时通常需要指定某些初始值。这里W的初始值是一个784 × 10 的全零矩阵, b的初始值是一个10 维的0向量。
除了变量和占位符之外,还创建了一个y = tf.nn.softmax(tf.matmul(x, W)+ b) 。这个y 就是一个依赖x、 W 、b 的Tensor 。如果要求TensorFlow 计算y的值,那么系统首先会获取x、 W、b 的值,再去计算y 的值。
y 实际上定义了一个Softmax 回归模型,在此可以尝试写出y 的形状。假设输入x 的形状为(N, 784),其中N 表示输入的训练图像的数目。W 的形状为(784,10), b 的形状为(10,) 。那么, Wx + b 的形状是(N, 10)。Softmax函数不改变结果的形状,所以得到y 的形状为(N, 10) 。也就是说, y 的每一行是一个10 维的向量,表示模型预测的样本对应到各个类别的概率。
模型的输出是y ,而实际的标签为y_ , 它们应当越相似越好。在Softmax回归模型中,通常使用“交叉熵”损失来衡量这种相似性。损失越小,模型的输出就和实际标签越接近,模型的预测也就越准确。
在TensorFlow 中,这样定义交叉熵损失:
# 至此,我们得到了两个重要的Tensor:y和y_。 # y是模型的输出,y_是实际的图像标签,不要忘了y_是独热表示的 # 下面我们就会根据y和y_构造损失 # 根据y和y_构造交叉熵损失 cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y)))
构造完损失之后,下面一步是如何优化损失,让损失减小。这里使用梯度下降法优化损失,定义为:
# 有了损失,我们就可以用随机梯度下降针对模型的参数(w和b)进行优化 train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
TensorFlow 默认会对所有变量计算梯度。在这里只定义了两个变量W和b ,因此程序将使用梯度下降法对W 、b 计算梯度并重新它们的值。tf.train.GradientDescentOptimizer(0.01)中的0.01 是梯度下降优化器使用的学习率( Learning Rate )。
# 创建一个Session。只有在Session中才能运行优化步骤train_step
sess = tf.InteractiveSession()
# 运行之前必须要初始化所有变量,分配内存
tf.global_variables_initializer().run()
print("start training...")
会话(Session)是Tensor Flow 的又一个核心概念。前面提到Tensor 是“希望”Tensor Flow 进行计算的结点。而会话就可以看成对这些结点进行计算的上下文。之前还提到过,变量是在计算过程中可以改变值的Tensor ,同时变量的值会被保存下来。事实上,变量的值就是被保存在会话中的。在对变量进行操作前必须对变量进行初始化,实际上是在会话中保存变量的初始值。初始化所高变量的语句是tf.global_variables initializer().run()。
有了会话,就可以对变量W 、b 进行优化了,优化的程序如下:
# 进行1000步梯度下降
for _ in range(1000):
# 在mnist.train中取100个训练数据
# batch_xs是形状为(100, 784)的图像数据,batch_ys是形如(100, 10)的实际标签
# batch_xs, batch_ys对应着两个占位符x和y_
batch_xs,batch_ys = mnist.train.next_batch(100)
# 在Session中运行train_step,运行时要传入占位符的值
sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys})
每次不使用全部训练数据,而是每次提取100 个数据进行训练,共训练1000 次。batch_xs, batch _ys 分别是100 个训练图像及其对应的标签。在训练时,需要把它们放入对应的占位符x, y_中,对应的语句是feed_dict={x:batch_ xs, y_:batch_ys} 。
在会话中,不需要系统计算占位符的值,而是直接把占位符的值传递给会话。与变量不同的是,占位符的值不会被保存,每次可以给占位符传递不同的值。
运行完梯度下降后,可以检测模型训练的结果,对应的代码如下:
# 正确的预测结果
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
# 计算预测准确率,它们都是Tensor
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
# 在Session中运行Tensor可以得到Tensor的值
# 这里是获取最终模型的准确率
print(sess.run(accuracy,feed_dict={x:mnist.test.images,y_:mnist.test.labels})) # 0.9149
模型预测y 的形状是(N,10), 而实际标签y_的形状是(N, 10),其中N 为输入模型的样本个数。tf. argmax(y, 1) 、tf. argmax(y_, 1)的功能是取出数组中最大值的下标,可以用来将独热表示以及模型输出转焕为数字标签。假设传入四个样本,它们的独热表示y_为(需要通过sess.run(y_)才能获取此Tensor的值,下同):
[[1,0,0,0,0,0,0,0,0,0], [0,0,1,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0,0,1], [1,0,0,0,0,0,0,0,0,0]]
tf.argmax(y_,1)就是:
[0,2,9,0]
也就是说,取出每一行最大值对应的下标位置, 它们是输入样本的实际标签。假设此时模型的预测输出y 为:
[[0.91, 0.01, 0.01, 0.01, 0.01 , 0.01, 0.01, 0.01, 0.01, 0.01], [0.91, 0.01, 0.01, 0.01, 0.01 , 0.01, 0.01, 0.01, 0.01, 0.01], [0.91, 0.01, 0.01, 0.01, 0.01 , 0.01, 0.01, 0.01, 0.01, 0.01], [0.91, 0.01, 0.01, 0.01, 0.01 , 0.01, 0.01, 0.01, 0.01, 0.01]]
tf.argmax(y_,1)就是:
[0,0,0,0]
得到了预测的标签和实际标签,接下来通过tf.equal 函数来比较它们是否相等,并将结果保存到correct_prediction 中。在上述例子中,correct_prediction 就是:
[True,False,False,True]
即第一个样本和最后一个样本预测是正确的,另外两个样本预测错误。可以用tf.cast(correct_prediction, tf. float32)将比较值转换成float32 型的变量,此时True 会被转换成1, False 会被转接成0 。在上述例子中,tf.cast(correct_prediction, tf.float32)的结果为:
[1., 0., 0., 1.]
最后,用tf.reduce_mean 可以计算数组中的所有元素的平均值,相当于得到了模型的预测准确率,如[1., 0., 0., 1.]的平均值为0.5 ,即50% 的分类准确率。
在程序softmax_regression. py 中,传入占位符的值是feed_dict={x:moist.test.images, y_: mnist.test.labels}。也就是说,使用全体测试样本进行测试。测试图片一共高10000 张,运行的结果为0.9149 ,即91.49% 的准确率。因为Softmax 回归是一个比较简单的模型,这里预测的准确率并不高,假如使用卷积神经网络的话会将预测的准确率提高到99% 。
这篇博文主要来自《21个项目玩转深度学习》这本书里面的第一章,内容有删减,还有本书的一些代码的实验结果。随书附赠的代码库链接为:https://github.com/hzy46/Deep-Learning-21-Examples
以上是关于MNIST机器学习入门的主要内容,如果未能解决你的问题,请参考以下文章