算法4:合并排序的套路 | 重用 | 分治
Posted freeself
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法4:合并排序的套路 | 重用 | 分治相关的知识,希望对你有一定的参考价值。
“重用与增量有序”的设计套路,前文已经介绍,这次介绍另一个招数--重用与分治的设计思想,这个套路在合并排序的算法设计中有所体现。
重用已经是一种被广泛使用的套路,小程之前介绍了重用的含义,而合并排序的重用,体现在对自身的反复调用。首先,认定合并排序算法就是让数列有序的,只要经过它处理,就一定会变得有序,这个信念很重要,做人要信。然后,把数列分为两部分,分别重用合并排序,重用完,这两部分就变得有序了。最后,把有序的两部分数列,合并起来,就解决了排序的问题。
也就是,合并排序本身就是一个标准作业,可以反复被重用。
选定标准作业,是很重要的,它会演化出不同的算法。比如,插入排序是不能以自身作为标准作业的,因为如果这样设计,它就不叫“插入排序”了,很可能变成了合并排序。
以上介绍了重用套路在合并排序算法中的体现。
另一个经典的套路,是分治。
分治,就是分而治之,你应该经常听到这样的说法:“没有什么是搞不定的!只要你把它分解得足够小,就能解决!”,换一个说法就是:没有什么是退一步不能解决的,如果有,那就退两步。
分是第一步,分出来解决后,还要把结果组合起来。
合并排序的分治套路,表现很明显:把数列分为两部分,重用自己令这两部分有序后,再组合起来。
而且,合并排序的分治,是很简单的分治,从中间分开再处理就可以了。当分到只有一个元素时,就不能再分,此时这一个元素是有序的。
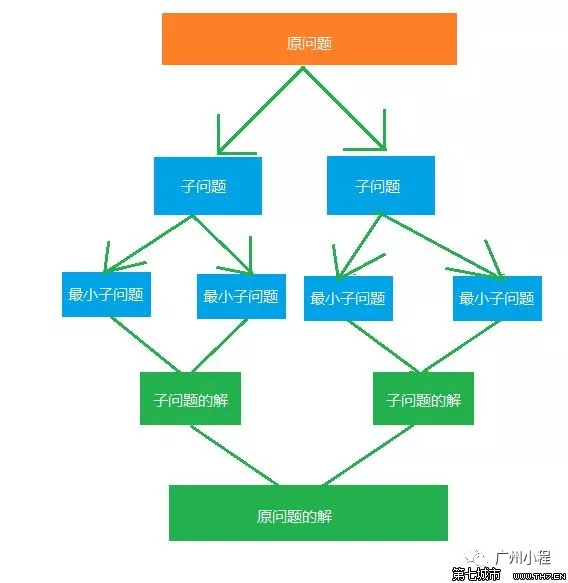
至此,合并排序的两个重要的套路(重用与分治)就差不多介绍完毕了。
为了让读者更清晰地感受这两个套路,小程接下来从具体的排序实例来详细介绍。
合并排序,先是要分(一分为二),分到只有一个元素为止(一个元素时就是有序的)。然后是合,先是两个元素合在一起,之后是多个元素合在一起。
参考以下这个演示图,可以更好地理解合排的设计与实现:

上面这个图,注意不同颜色框的变化(分与合的变化)。
再参考另一个演示图(来自网络):
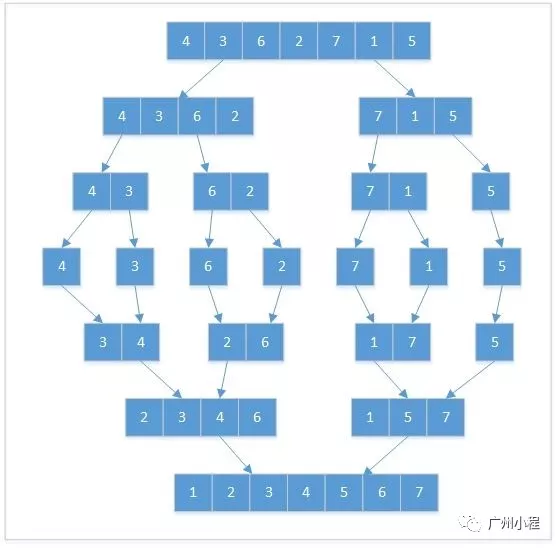
以上是算法套路,接下是代码实现,这两者是两个话题,之前已经解释过。
#include <stdio.h>
#include <stdlib.h>
void merge(int* arr, int f, int m, int l, int* tmparr) {
int i=f, j=m+1;
int k=0;
while (i<=m && j<=l) {
if (arr[i] > arr[j]) {
tmparr[k++]=arr[j++];
}
else {
tmparr[k++]=arr[i++];
}
}
while (i<=m) {
tmparr[k++]=arr[i++];
}
while (j<=l) {
tmparr[k++]=arr[j++];
}
for (i=0; i<k; i++) {
arr[f++]=tmparr[i];
}
}
void _sort_merge(int* arr, int f, int l, int* tmparr) {
if (f < l) {
int m=(f+l)>>1;
_sort_merge(arr, f, m, tmparr);
_sort_merge(arr, m+1, l, tmparr);
merge(arr, f, m, l, tmparr);
}
}
void sort_merge(int* arr, int size) {
int* tmparr=(int*)malloc(sizeof(int) * size);
_sort_merge(arr, 0, size-1, tmparr);
free(tmparr);
}
int main(int argc, char *argv[])
{
int arr[] = {4, 2, 5, 1, 6, 6, 8, 9, 8, 3};
int size=sizeof arr/sizeof *arr;
for (int i = 0; i < size; i ++) {
printf("%d, ", arr[i]);
}
sort_merge(arr, size);
printf("\nafter_sort:\n");
for (int i = 0; i < size; i ++) {
printf("%d, ", arr[i]);
}
printf("\n");
return 0;
}
另外,在分治的套路中,可以混搭增量有序的套路,也就是,合并排序在划分到数量较小时,可以使用插入排序来完成排序(因为在数量较小时,插入排序更快一些),这种套路混搭,打出来的就是组合拳。
以下这部分,介绍了合排与快排的对比,你可以忽略掉,因为时间复杂度或速度方面,跟套路并无直接关系。
小白:只要分成两部分,再递归调用自己来排好序,再合并在一起即可。小程,你之前讲的递归又发挥作用了!
小程:不要把递归实现跟设计思想混在一起。设计上,是一直分下去,再合起来。但实现时,不一定要用递归,比如可以把分出来的部分,用数组保存起来,再对这个数组内的部分作细分...,用迭代也能实现。只不过,递归是很自然的实现选择,而且简洁。但是,你要有“空手套白狼”的勇气才敢于用上递归实现。
小白:就是先假设我的函数已经实现排序了,再在函数里面调用自己,对某部分作排序了。东风吹战鼓擂,这个世界谁怕谁?
合并排序的分(O(lgn))与合(O(n)),整体的时间复杂度是O(nlgn),而且是稳定排序。
小白:那岂不是比快排还要快,因为快排有可能变为n的平方?
小程:不是。快排有可能变成n的平方,这种极端的情况是低概率的,而且,可以先打乱再来快排,从而避免去到O(n^2),或者去到极低概率。在都为O(nlogn)时,快排的系数比合排更小,所以速度更快。另外,合排需要额外的空间来保存合并的结果,而快排不需要。
小白:这个...,看来quicksort是实至名归!
在工程中,快排的效果比合排更优,但注意高层次的设计思想,也就是套路,是一样的。
总结一下,本文介绍了合并排序的套路,即重用与分治,这两种思想都是经典的套路,重用能简化问题的思考,而分治能把问题变小,能熟练掌握这两种套路就具备了很厉害的功力。

以上是关于算法4:合并排序的套路 | 重用 | 分治的主要内容,如果未能解决你的问题,请参考以下文章