并发编程
Posted 1oo88
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并发编程相关的知识,希望对你有一定的参考价值。
并发编程
操作系统的进化
- 传统的纸带输入
- 磁带的存储降低了输入输出数据占用的时间,提高了CPU的利用率
- 多道操作系统的出现:提高了CPU的利用率,单纯的切换会浪费时间
a) 一台计算机上同时可以出现多个任务
b) 能够将多个任务所使用的资源隔离开
c) 当一个任务遇到输入输出工作的时候能够让另一个任务使用CPU去计算
- 分时操作系统:降低了CPU的利用率,提高了用户的体验。
时间片轮转
- 实时操作系统(实时的处理任务)
- 网络操作系统
- 分布式操作系统(多任务分给子系统处理)
并发和并行
并发:多个程序交替在同一个CPU上被计算
并行:多个程序同时在多个CPU上被计算
阻塞与非阻塞
CPU是否在工作
异步和同步
异步:发布一个任务,不等待这个任务的结果就继续执行任务
同步:发布一个任务,等待获取这个任务的结果之后才继续执行任务
进程和线程
进程(是计算机中资源分配的最小单位。)
进程就是运行中的程序,每个进程在计算机中都有一个唯一的进程id,为PID
进程三状态(就绪、运行、阻塞)
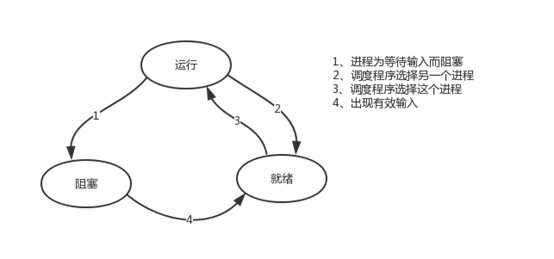
进程的调度
- 先来先服务
- 短作业优先
- 分时/多道
- 多级反馈队列
进程的终止
- 正常退出
- 出错退出
- 严重错误
- 被其他进程杀死
线程(是计算机中能够被CPU调度的最小单位)
是进程中的一个单位,它不独立存在
TCP协议的socketserver并发效果(可以同时开多个客户端)
import socketserver
socket是socketserve的底层模块
socketserver的网络连接这个操作是调用socket模块实现的
import socketserver class Myserver(socketserver.BaseRequestHandler): def handle(self): conn=self.request print(conn) server = socketserver.ThreadingTCPServer((‘127.0.0.1‘, 9999), Myserver) server.serve_forever()
并发编程之多进程
开启进程的两种方式
multiprocessing模块
Python提供了multiprocessing。 multiprocessing模块用来开启子进程,并在子进程中执行我们定制的任务(比如函数),该模块与多线程模块threading的编程接口类似。multiprocessing模块的功能众多:支持子进程、通信和共享数据、执行不同形式的同步,>提供了Process、Queue、Pipe、Lock等组件。
Process进程类(达到异步传输的作用)
示例:
import time from multiprocessing import Process def func(a,b,c): time.sleep(1) print(a,b,c) if __name__ == ‘__main__‘: Process(target=func,args=(1,2,3)).start() #这里的target是目标的意思,固定搭配 Process(target=func,args=(2,3,4)).start() #所有的Process()都是子进程,子进程都放在if下。 Process(target=func,args=(3,4,5)).start()
需要注意:args是传值,若只传一个值时,必须为元组形式。
p.start() #P是一个进程操作
p.terminate() 终止进程
p.is_alive() 进程是否存活
join(阻塞,直到P对应的进程结束后才结束阻塞-对子进程同步管理的方法)
示例:
import time import random from multiprocessing import Process def send_mail(name): time.sleep(random.uniform(1,3)) print(‘已经给%s发送邮件完毕‘%name) if __name__ == ‘__main__‘: lst = [‘alex‘,‘yuan‘,‘宝元‘,‘太白‘] p = Process(target=send_mail, args=(‘alex‘,)) p.start() p.join() # 阻塞,直到p对应的进程结束之后才结束阻塞 print(‘所有的信息都发送完毕了‘)
守护进程(p.daemon=True)
守护进程是一个子进程,守护的是主进程。
结束条件:主进程的代码结束,守护进程也结束
import time from multiprocessing import Process def func(): for i in range(20): time.sleep(0.5) print(‘in func‘) def func2(): print(‘start : func2‘) time.sleep(5) print(‘end : func2‘) if __name__ == ‘__main__‘: p = Process(target=func) p.daemon = True # 表示设置p为一个守护进程 p.start() p2 =Process(target=func2) p2.start() print(‘in main‘) time.sleep(3) print(‘finished‘) p2.join()
锁(with lock:)
import lock
lock=Lock()
lock.acquire()
内容
lock.release()
或
with lock:
内容
推荐用with lock,可以自动异常处理。
牺牲了效率,保证了数据安全
锁的应用:
当多个进程需要操作同一个文件/数据库的时候,会产生数据不安全,我们应该使用锁来避免多个进程同时修改一个文件
队列(实现多个进程间的数据交互和通信(IPC))
from multiprocessing import Queue # 可以完成进程之间通信的特殊的队列 # from queue import Queue # 不能完成进程之间的通信 from multiprocessing import Queue,Process def son(q): print(‘-->‘,q.get()) if __name__ == ‘__main__‘: q = Queue() Process(target=son,args=(q,)).start() q.put(‘wahaha‘)
线程
- 轻型进程,轻量级的进程
- 在同一个进程中的多个线程是可以共享一部分数据的
- 线程的开启、销毁、切换都比进程要高效很多
- 4. python当中的多线程不能访问多个CPU,但是线程本身可以同时访问多个CPU:Cpython解释器,有一个GIL锁
threading模块
现有threading模块,后有multiprocessing模块,后者完全模仿前者,并且实现了池的功能concurrent.futures
import os import time from threading import Thread def func(): time.sleep(1) print(‘in func‘,os.getpid()) print(‘in main‘,os.getpid()) for i in range(20): # func() Thread(target=func).start()
线程中的其他方法
from threading import active_count 返回当前有多少个正在工作的线程
print(active_count())
from threading import enumerate,Thread def func(): print(‘in son thread‘) Thread(target=func).start() print(enumerate()) 返回一个存储着所有存活线程对象的列表
线程没有terminate,不能强制结束,必须等所有的子线程结束后结束
守护线程
- 主线程会等待子线程结束才结束
- 守护线程会随着主线程的结束而结束
- 守护线程会守护主线程和所有的子线程
- 进程会随着主线程的结束而结束
import time from threading import Thread def daemon_func(): while True: time.sleep(0.5) print(‘守护线程‘) def son_func(): print(‘start son‘) time.sleep(5) print(‘end son‘) t = Thread(target=daemon_func) t.daemon = True 设置守护 t.start() Thread(target=son_func).start() time.sleep(3) print(‘主线程结束‘)
线程中的锁
数据不安全问题
在线程中也是会出现数据不安全问题(1.对全局变量进行修改 2.对某个值+= -= *= /*)
只能通过加锁来解决
递归锁
from threading import Rlock,Thread
可以连续加锁
池(帮助利用多核,批量处理任务)
进程池
好处:控制进程的数量,节省资源的开销
示例:
import os import time from concurrent.futures import ProcessPoolExecutor 线程池 # def make(i): # time.sleep(1) # print(‘%s 制作螺丝%s‘%(os.getpid(),i)) # return i**2 # # if __name__ == ‘__main__‘: # p = ProcessPoolExecutor(4) # 创建一个进程池 # for i in range(100): # p.submit(make,i) # 向进程池中提交任务 # p.shutdown() # 阻塞 直到池中的任务都完成为止 # print(‘所有的螺丝都制作完了‘) # p.map(make,range(100)) # submit的简便用法 # 接收返回值 # ret_l = [] # for i in range(100): # ret = p.submit(make,i) # ret_l.append(ret) # for r in ret_l: # print(r.result()) # ret = p.map(make, range(100)) # for i in ret: # print(i)import os import time from concurrent.futures import ProcessPoolExecutor 线程池 # def make(i): # time.sleep(1) # print(‘%s 制作螺丝%s‘%(os.getpid(),i)) # return i**2 # # if __name__ == ‘__main__‘: # p = ProcessPoolExecutor(4) # 创建一个进程池 # for i in range(100): # p.submit(make,i) # 向进程池中提交任务 # p.shutdown() # 阻塞 直到池中的任务都完成为止 # print(‘所有的螺丝都制作完了‘) # p.map(make,range(100)) # submit的简便用法 # 接收返回值 # ret_l = [] # for i in range(100): # ret = p.submit(make,i) # ret_l.append(ret) # for r in ret_l: # print(r.result()) # ret = p.map(make, range(100)) # for i in ret: # print(i)
线程池
from urllib.request import urlopen from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def get_html(name,addr): ret = urlopen(addr) return {‘name‘:name,‘content‘:ret.read()} def parser_page(ret_obj): dic = ret_obj.result() with open(dic[‘name‘]+‘.html‘,‘wb‘) as f: f.write(dic[‘content‘]) url_lst = { ‘name‘:‘url‘, ‘name‘:‘url‘, ‘name‘:‘url‘, ‘name‘:‘url‘, ‘name‘:‘url‘, } t = ThreadPoolExecutor(20) for url in url_lst: task = t.submit(get_html,url,url_lst[url]) task.add_done_callback(parser_page)
协程(第三方模块greenlet、gevent(推荐使用))
是一个比线程还小的单位
协程不是操作系统可见的,是用户级别的,是代码控制切换的。
特点:从python代码级别的,完成代码在多个函数之间的切换。
协程(本质是一条线程,操作系统不可见)
是有程序员操作的,而不是由操作系统调度的
多个协程的本质是一条线程,所以多个协程不能利用多核
出现的意义 : 多个任务中的IO时间可以共享,当执行一个任务遇到IO操作的时候,
可以将程序切换到另一个任务中继续执行
在有限的线程中,实现任务的并发,节省了调用操作系统创建\\销毁线程的时间
并且协程的切换效率比线程的切换效率要高
协程执行多个任务能够让线程少陷入阻塞,让线程看起来很忙
线程陷入阻塞的次数越少,那么能够抢占CPU资源就越多,你的程序效率看起来就越高
1.开销变小了
2.效率变高了
示例:
协程模块 帮助我们更加简单的进行函数之间的切换
gevent模块(遇到IO操作自动切换)
import time import gevent def eat(): # 协程任务 协程函数 print(‘start eating‘) gevent.sleep(1) print(‘end eating‘) def sleep(): # 协程任务 协程函数 print(‘start sleeping‘) gevent.sleep(1) print(‘end sleeping‘) g1 = gevent.spawn(eat) g2 = gevent.spawn(sleep) # g1.join() # 阻塞,直到g1任务执行完毕 # g2.join() # 阻塞,直到g2任务执行完毕 gevent.joinall([g1,g2]) #合并上面两句
用了monkey.patch_all()之后,把所有导入的打成一个包,全部能使用。就可以不用上面的gevent.sleep(1).
from gevent import monkey monkey.patch_all() import time import gevent def eat(): # 协程任务 协程函数 print(‘start eating‘) time.sleep(1) print(‘end eating‘) def sleep(): # 协程任务 协程函数 print(‘start sleeping‘) time.sleep(1) print(‘end sleeping‘) g1 = gevent.spawn(eat) # 创建协程 g2 = gevent.spawn(sleep) gevent.joinall([g1,g2]) # 阻塞 直到协程任务结束
以上是关于并发编程的主要内容,如果未能解决你的问题,请参考以下文章