大数据学习之提交job流程,分区和合并11
Posted hidamowang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习之提交job流程,分区和合并11相关的知识,希望对你有一定的参考价值。
一:合并(mapTask的合并)
使用合并的注意事项:
(1)合并是一种特殊的Reducer
(2)合并是在Mapper端执行一次合并,用于减少Mapper输出到Reducer的数据量,可以提高效率。
(3)举例:以WordCount为例
(4)注意:一定要谨慎使用Combiner,有些不能使用:求平均值
有Combiner,或者没有Combiner,都不能改变Map和Reduce对应数据的类型
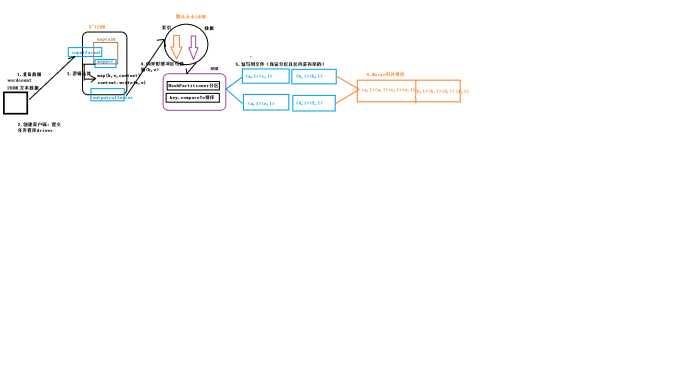
原理图:
1:maptask并行度与决定机制
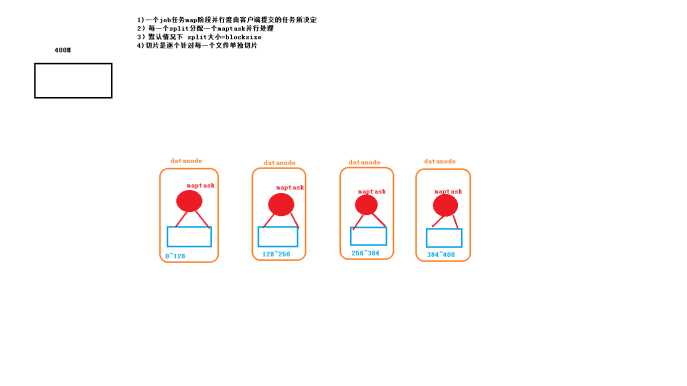
2 maptask工作机制
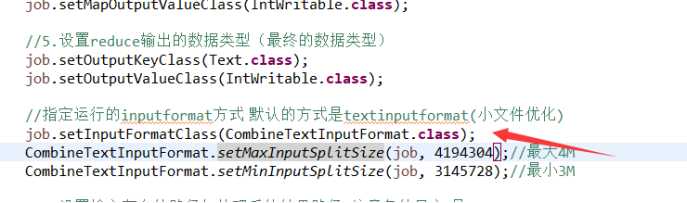
3:代码改写:使用上回的WordCount程序。添加如下代码就行了
二:自定义分区
1:自定义一个Partition类(直接使用上次那个流量统计那个代码)
package it.dawn.YARNPra.flow流量汇总序列化.partition;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author Dawn
* @date 2019年5月3日22:03:08
* @version 1.0
* 自定义一个分区
*/
public class PhonenumPartitioner extends Partitioner<Text, FlowBean>{
//根据手机号前三位进行分区
@Override
public int getPartition(Text key, FlowBean value, int numpartitions) {
//1.获取手机号前三位
String phoneNum=key.toString().substring(0, 3);
//2:分区
int partitioner=4;
if("135".equals(phoneNum)) {
return 0;
}else if("137".equals(phoneNum)){
return 1;
}else if("138".equals(phoneNum)) {
return 2;
}else if("139".equals(phoneNum)) {
return 3;
}
return partitioner;
}
}
2:在Driver类中添加Partiton的分区个数
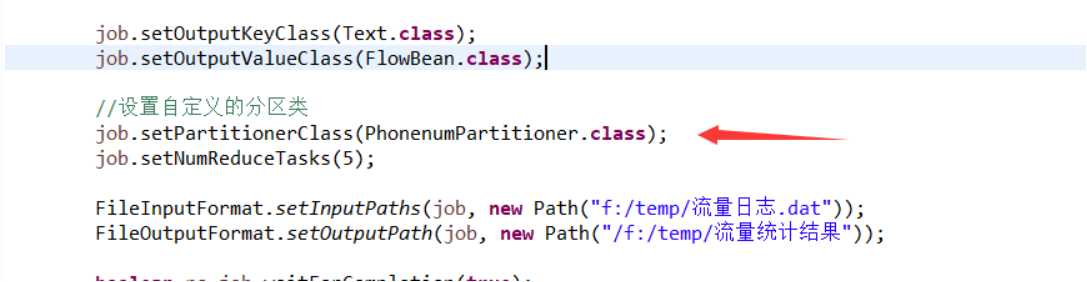
3:运行结果
以上是关于大数据学习之提交job流程,分区和合并11的主要内容,如果未能解决你的问题,请参考以下文章