Mac-搭建Hadoop集群
Posted taojietaoge
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mac-搭建Hadoop集群相关的知识,希望对你有一定的参考价值。
You have to work very hard to believe that you are really powerless.
Mac-搭建Hadoop集群
我用到了:VMware Fusion、CentOS7、FileZilla、jdk-8u181-linux-x64.tar.gz和hadoop-2.7.6.tar.gz
1、集群部署规划
NameNode单点部署:
| 节点名称 | NN1 | NN2 | DN | RM | NM | 规划IP | other |
| tjt01 | NameNode | DataNode | NodeManager | 172.16.114.130 | hive/hdfs | ||
| tjt02 | SecondaryNameNode | DataNode | ResourceManager | NodeManager | 172.16.114.131 | hbase/kms | |
| tjt03 | DataNode | NodeManager | 172.16.114.132 | mysql/spark |
2、三台客户机相关准备
2.1、安装VMware虚拟机
在虚拟机中安装CentOS镜像,由初始安装的CentOS7版本的镜像,完整克隆出另外两台虚拟机
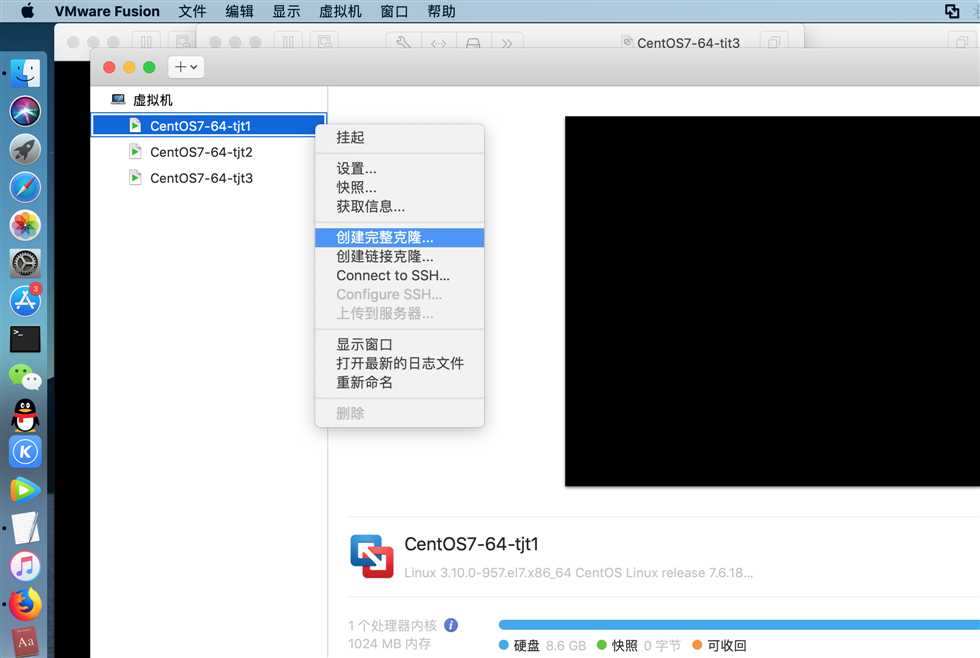
2.2、修改主机名
[[email protected] tjt]# vi /etc/hostname
分别修改三台虚拟机主机名:tjt01、tjt02、tjt03
2.3、修改host文件
配置主机host:
[[email protected] tjt]# vi /etc/hosts
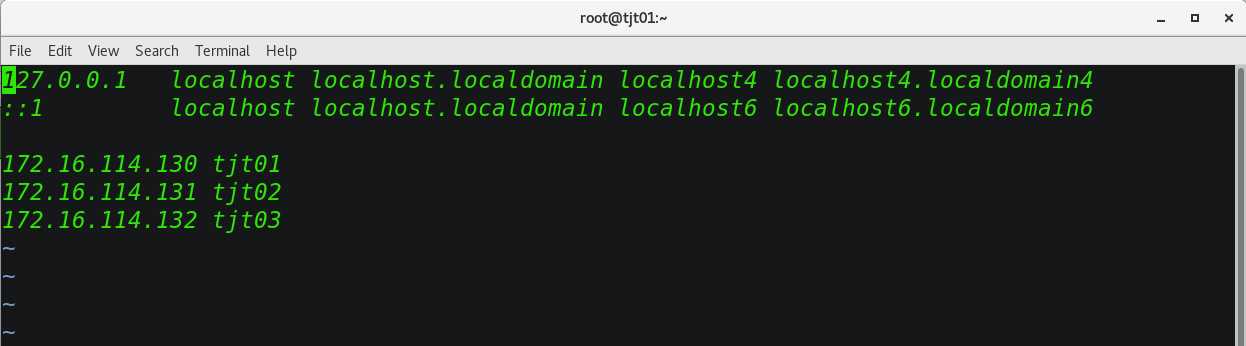
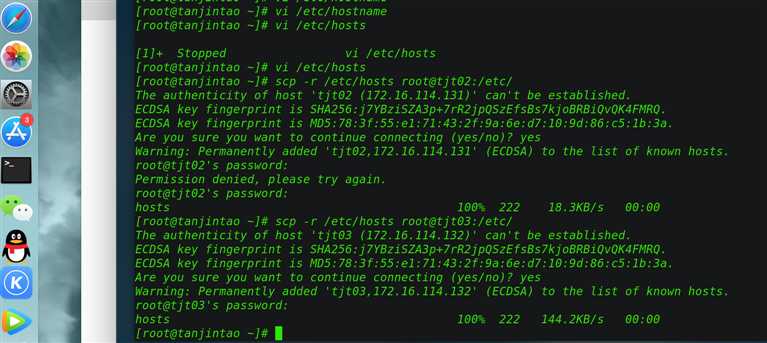
将配置发送到其他的主机,同时在其他主机上配置:
scp -r /etc/hosts [email protected]:/etc/
scp -r /etc/hosts [email protected]:/etc/
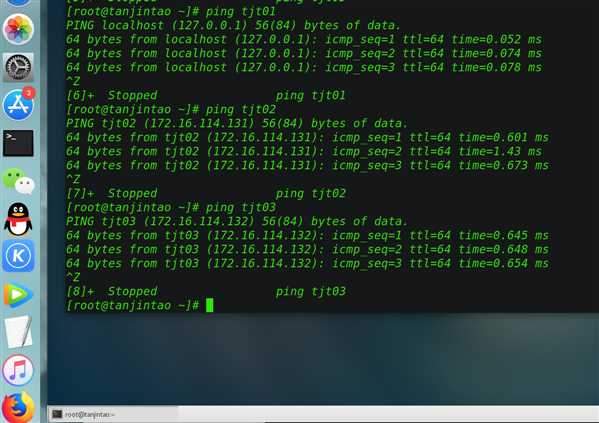
测试host文件修改结果:
ping tjt01
ping tjt02
pint tjt03
2.4、设置SSH免密登录
每两台主机之间设置免密码,自己的主机与自己的主机之间也要求设置免密码;
输入:ssh-keygen -t rsa
然后按下四次回车,之后在把密匙发到其他主机上,输入:ssh-copy-id tjt01 并按提示输入密码,然后是ssh-copy-id 02和ssh-copy-id 03同样的操作;
之后,在另外两台虚拟机上也执行相同的步骤:
ssh-keygen -t rsa
ssh-copy-id tjt01
ssh-copy-id tjt02
ssh-copy-id tjt03
ssh tjt01、ssh tjt02、ssh tjt03
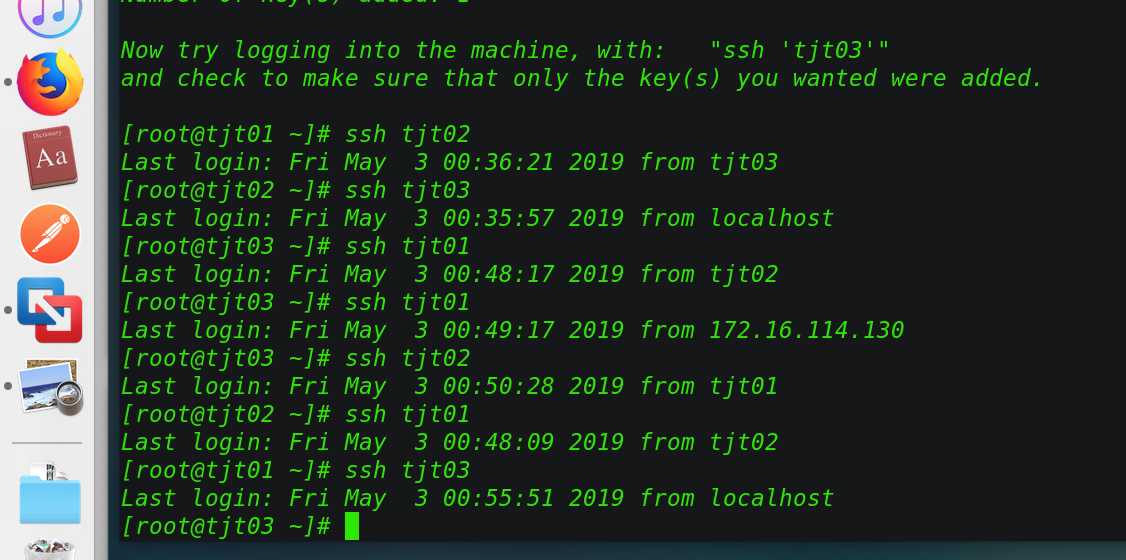
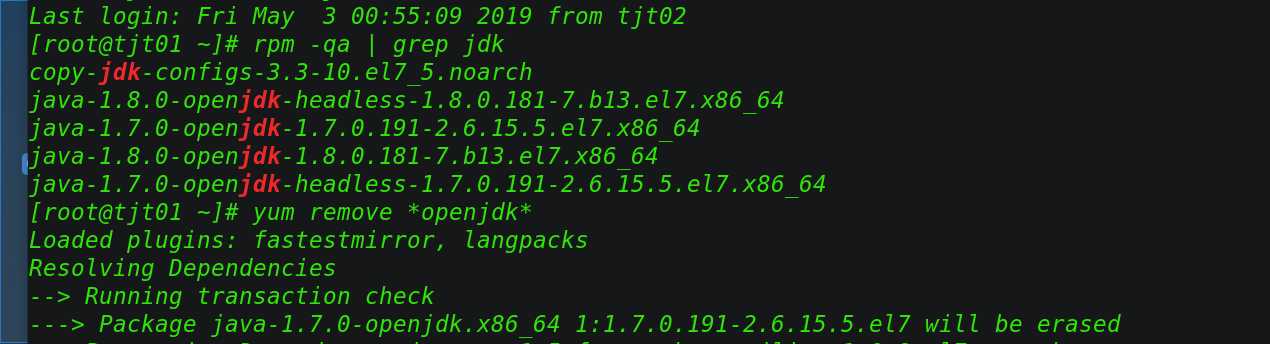
rpm -qa | grep jdk
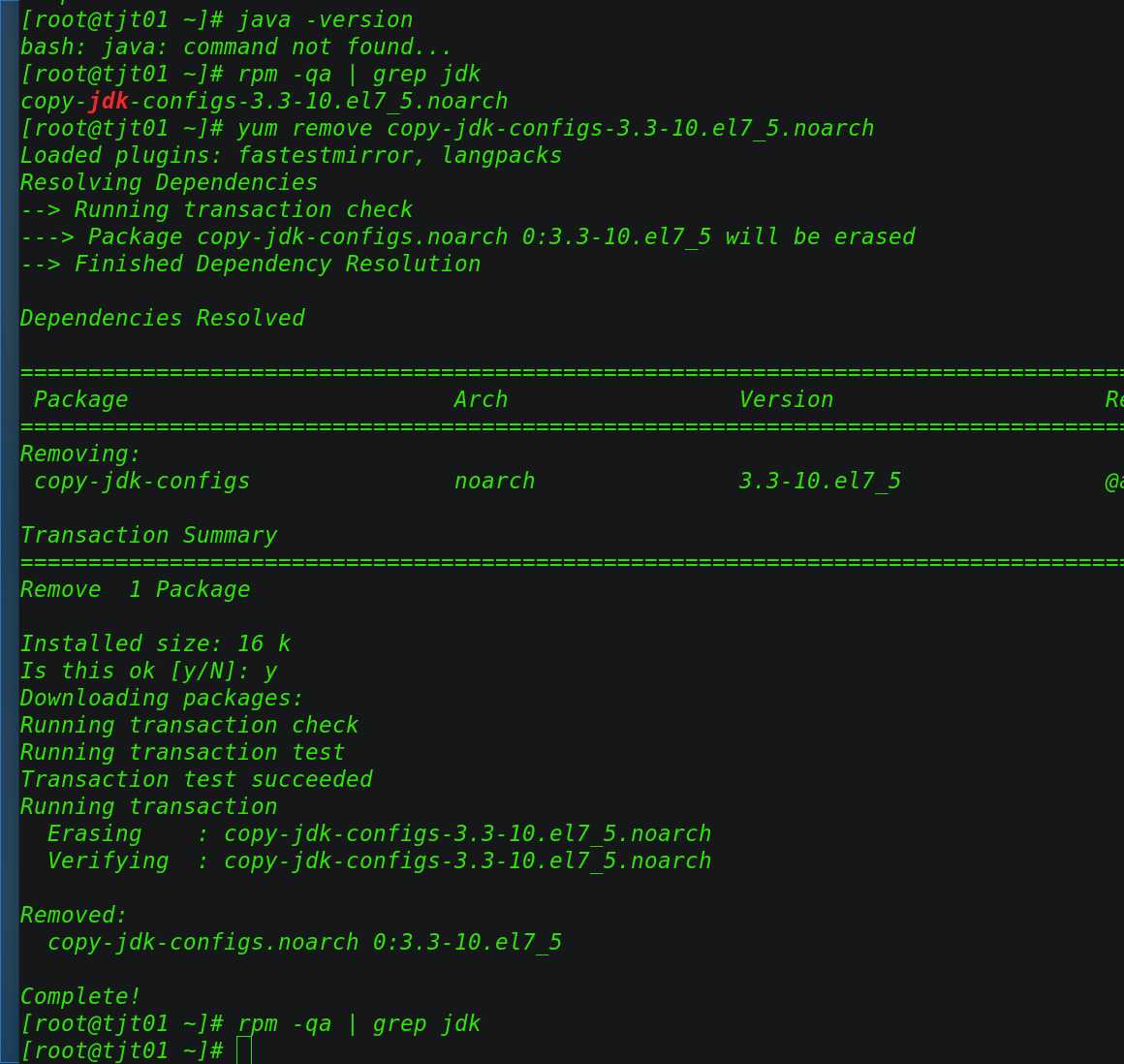
yum remove *openjdk*
yum remove copy-jdk-configs-3.3-10.el7_5.noarch
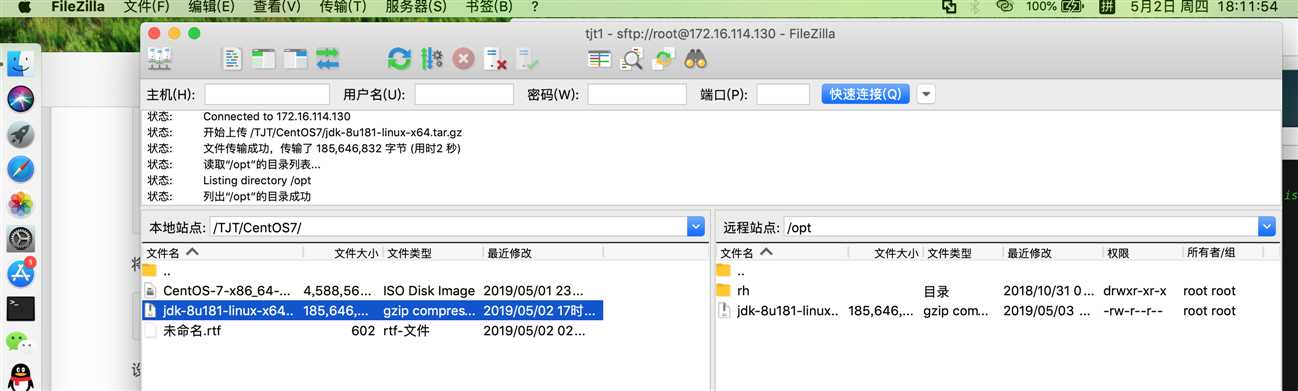
将JDK安装包上传到/opt下,可以通过XShell的rz上传,也可以用FileZilla:
到/opt 目录下解压:tar xzvf jdk-8u181-linux-x64.tar.gz
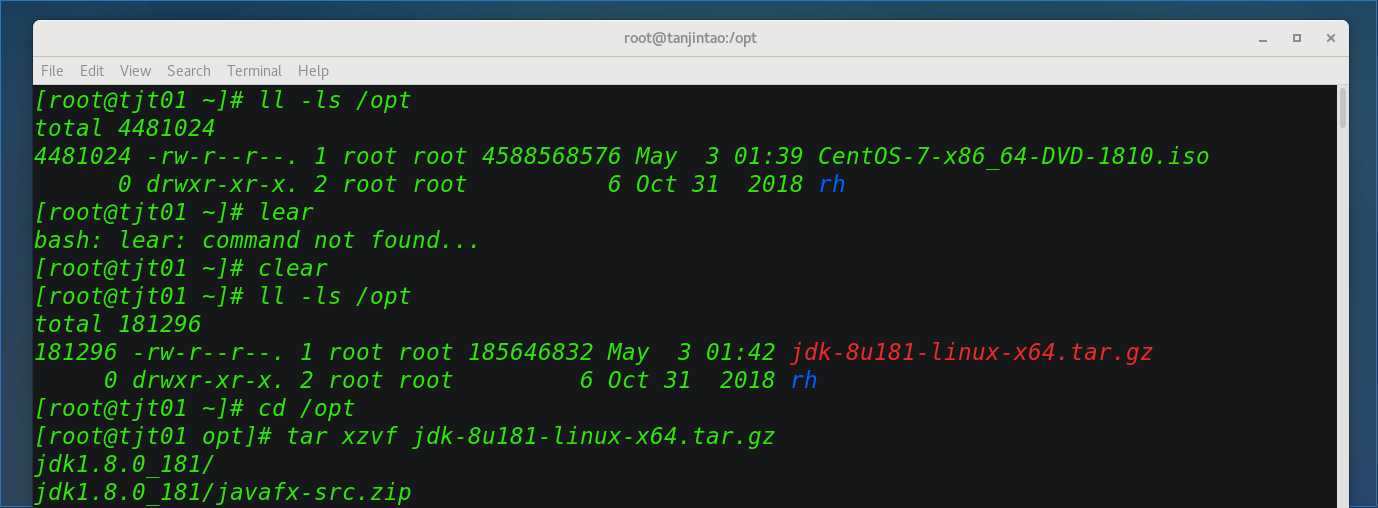
设置JAVA_HOME:
输入:vi /etc/profile,在profile文件中的编辑模式下加上下方export配置:
export JAVA_HOME=/opt/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/sbin

复制JDK到另外两个节点:
在这之前要先把另外两台虚拟机上的openjdk也干掉:
yum remove *openjdk*
yum remove copy-jdk-configs-3.3-10.el7_5.noarch
然后复制jdk到另外两个虚拟机上:
scp -r /opt/jdk1.8.0_181 [email protected]:/opt/
scp -r /opt/jdk1.8.0_181 [email protected]:/opt/
向其他节点复制profile文件:
scp /etc/profile [email protected]:/etc/
scp /etc/profile [email protected]:/etc/

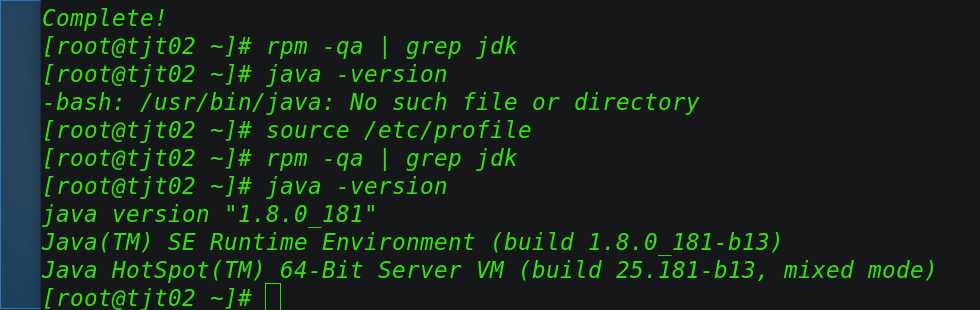
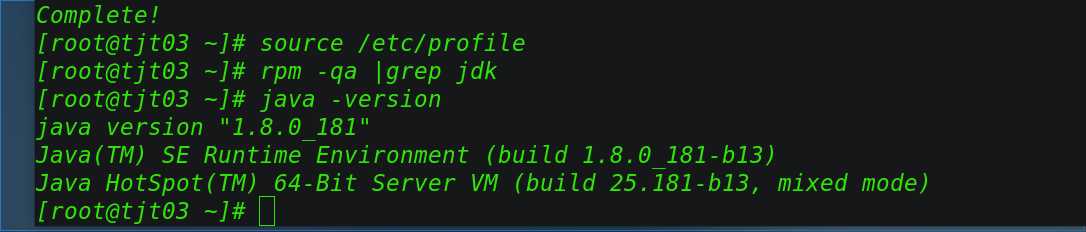
然后每个节点分别执行 source /etc/profile ,使profile生效下,并通过java-version简单测试下,jdk复制是否成功:
tjt02:
tjt03:
3、安装Hadoop
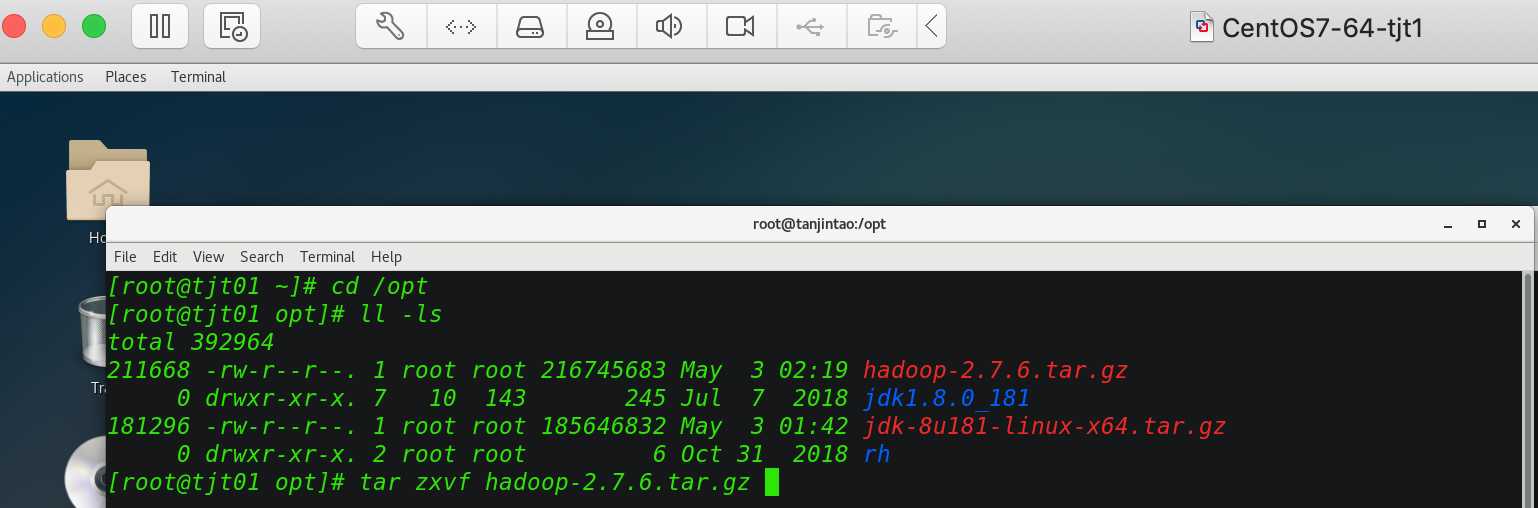
3.1、上传并解压Hadoop
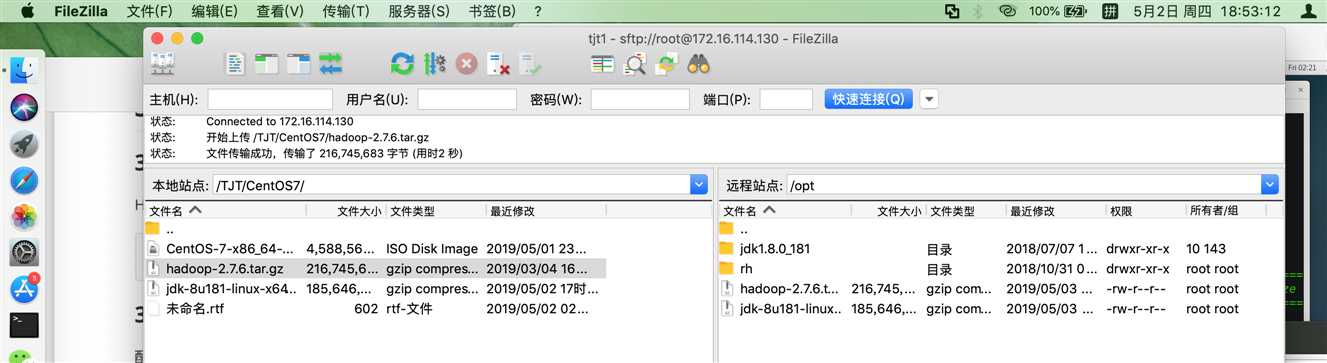
解压:tar zxvf hadoop-2.7.6.tar.gz
3.2、搭建Hadoop集群
配置文件在hadoop2.7.6/etc/hadoop/下,修改设置hadoop2.7.6目录下的可执行权限
3.2.1、修改 core-site.xml
[[email protected] hadoop]# vi core-site.xml
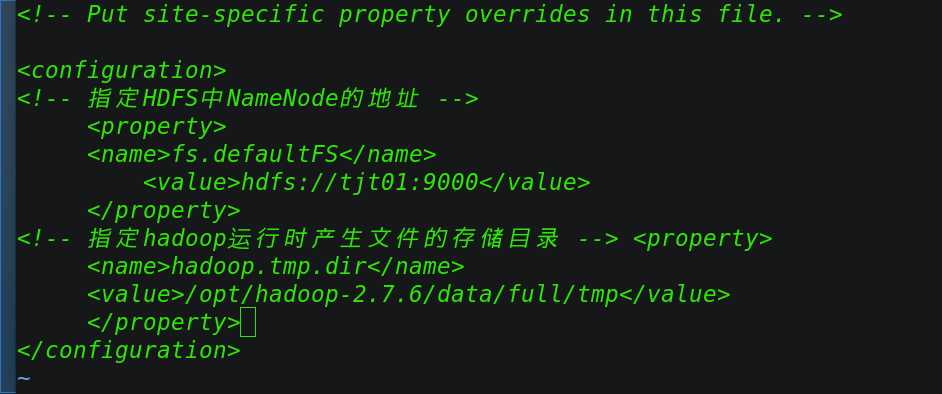
然后在core-site.xml文件中编辑如下:
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://tjt01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 --> <property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.6/data/full/tmp</value>
</property>
3.2.2、修改hadoop-env.sh
[[email protected] hadoop]# vi hadoop-env.sh
修改JAVA_HOME:

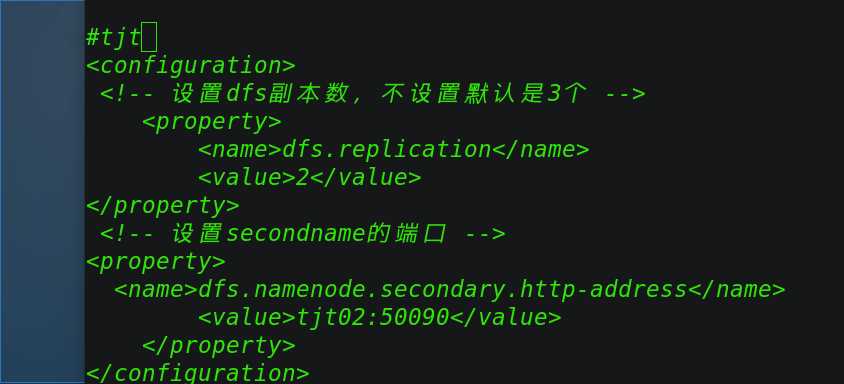
3.2.3 修改hdfs-site.xml
[[email protected] hadoop]# vi hdfs-site.xml
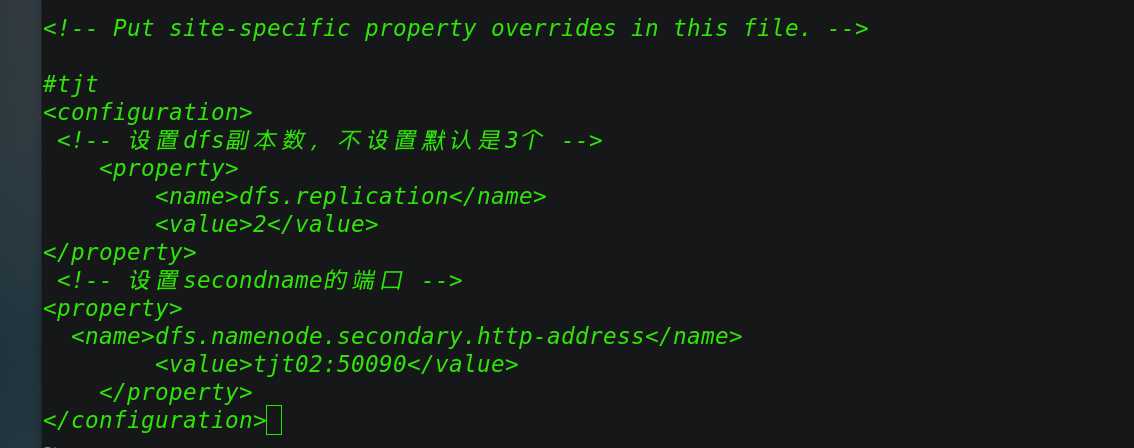
修改 hdfs-site.xml 的配置如下:
<configuration>?
<!-- 设置dfs副本数,不设置默认是3个 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>?
<!-- 设置secondname的端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>tjt02:50090</value>
</property>
</configuration>
3.2.4 修改 slaves
[[email protected] hadoop]# vi slaves
增加slaves 配置如下:
tjt01
tjt02
tjt03

3.2.5 修改mapred-env.sh
[[email protected] hadoop]# vi mapred-env.sh
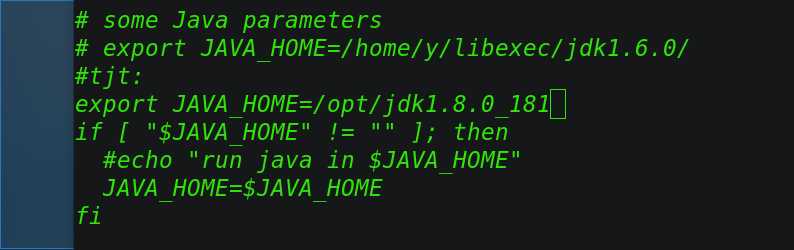
修改其JAVA_HOME如下:
export JAVA_HOME=/opt/jdk1.8.0_181

3.2.6 修改mapred-site.xml
[[email protected] hadoop]# mv mapred-site.xml.template mapred-site.xml
[[email protected] hadoop]# vi mapred-site.xml
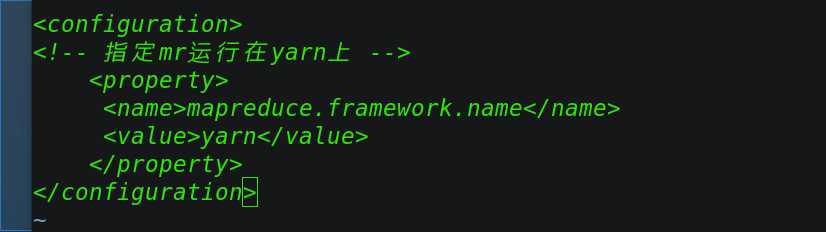
修改其configuration如下:
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.2.7 修改yarn-env.sh
[[email protected] hadoop]# vi yarn-env.sh
修改其JAVA_HOME如下:
export JAVA_HOME=/opt/jdk1.8.0_181
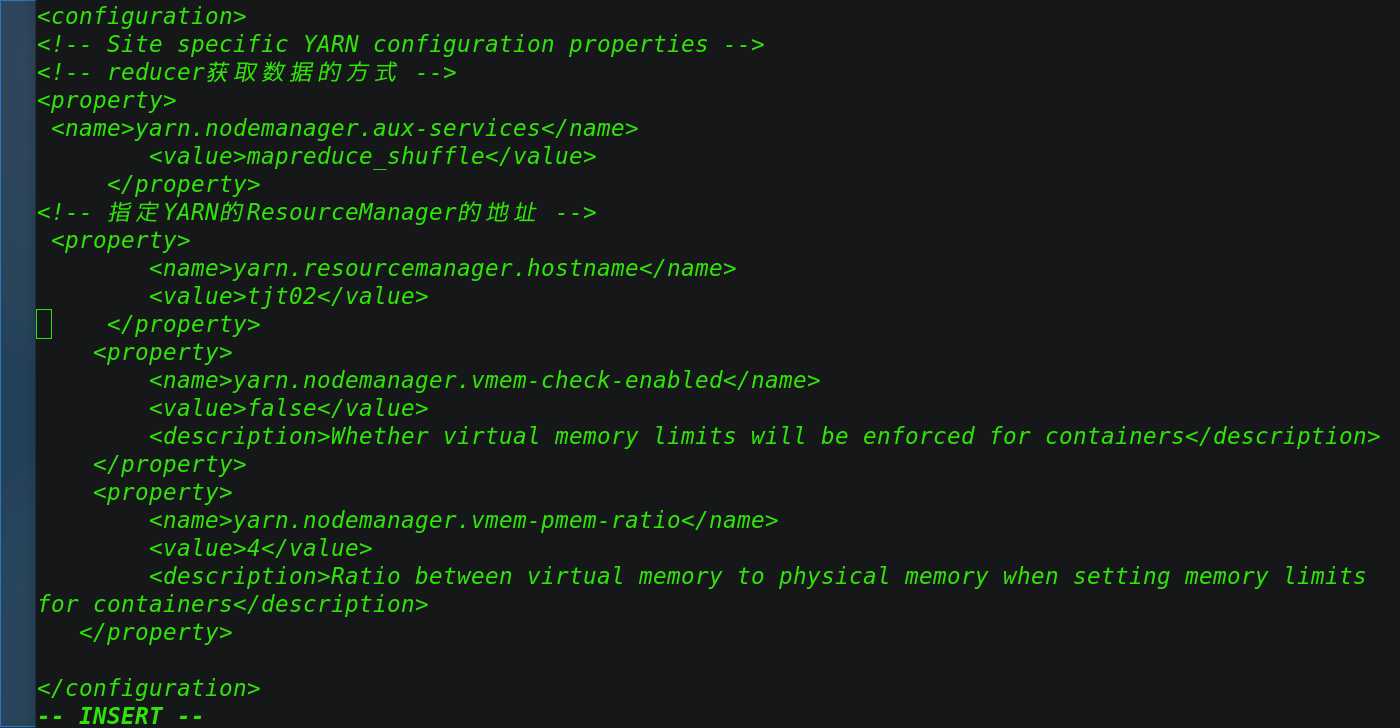
3.2.8 修改yarn-site.xml
[[email protected] hadoop]# vi yarn-site.xml
修改配置如下:
<configuration>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>tjt02</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits
for containers</description>
</property>
</configuration>
3.3 分发hadoop到各个节点
[[email protected] hadoop]# scp -r /opt/hadoop-2.7.6/ [email protected]:/opt
[[email protected] hadoop]# scp -r /opt/hadoop-2.7.6/ [email protected]:/opt
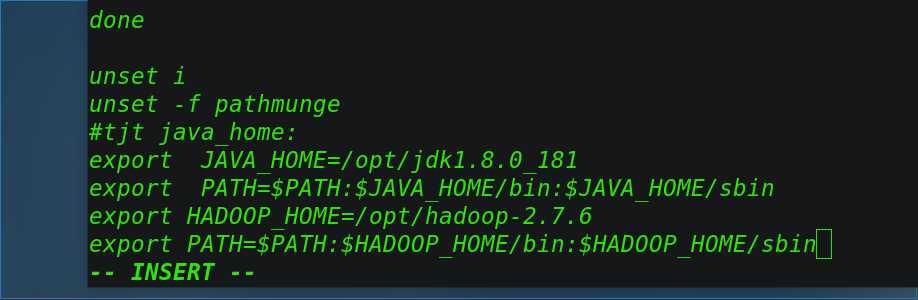
3.4 配置环境变量
[[email protected] hadoop]# vi /etc/profile
修改配置如下:
export HADOOP_HOME=/opt/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile 使profile文件生效;
[[email protected] hadoop]# source /etc/profile
3.5 分发profile到各个节点
[[email protected] hadoop]# scp /etc/profile [email protected]:/etc/
[[email protected] hadoop]# scp /etc/profile [email protected]:/etc/

到各自的服务节点上是profile 生效:
[[email protected] ~]# source /etc/profile
[[email protected] ~]# source /etc/profile
4 启动验证集群
4.1 启动集群
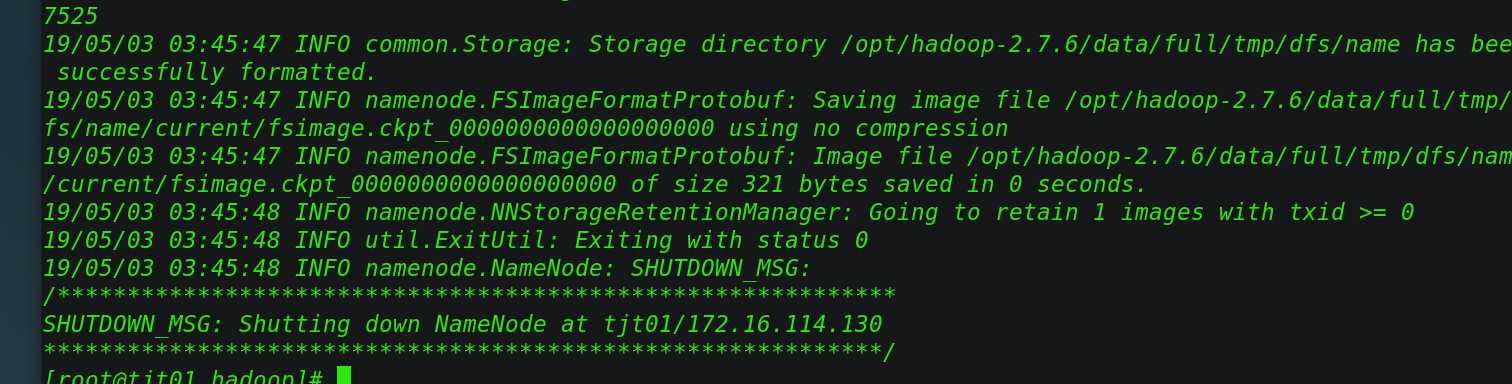
[[email protected] hadoop]# hdfs namenode -format
当看到19/05/03 03:45:47 INFO common.Storage: Storage directory /opt/hadoop-2.7.6/data/full/tmp/dfs/name has been successfully formatted. 就格式化OK了;
[[email protected] hadoop-2.7.6]# start-dfs.sh

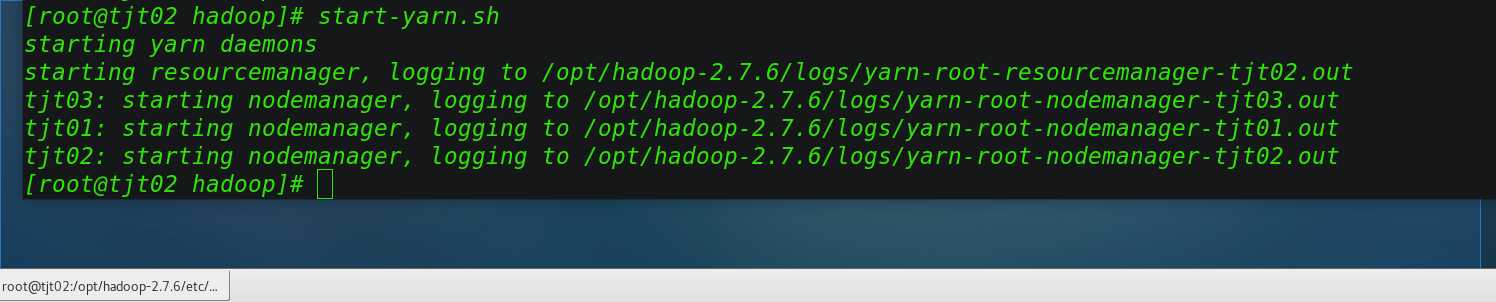
如果Namenode和ResourceManager不是同一台虚拟机的话,不能在NameNode上启动yarn,应该在ResourceManager所在的机器上启动yarn;我的yarn配置在tjt02服务器上,一次需要到tjt02机器上启动yarn

[[email protected] hadoop]# start-yarn.sh
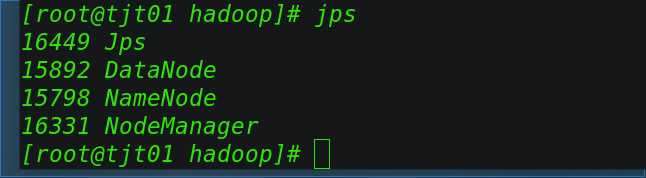
[[email protected] hadoop]# jps
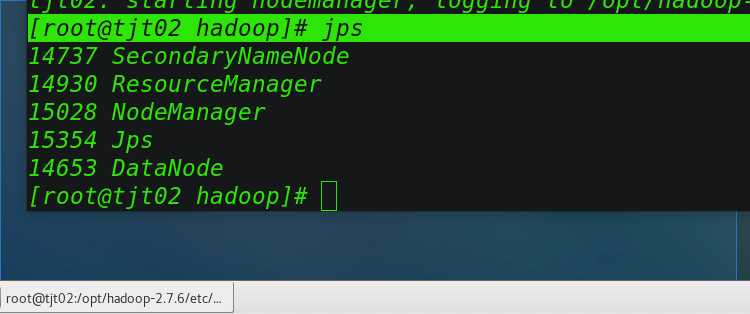
[[email protected] hadoop]# jps
[[email protected] hadoop]# jps

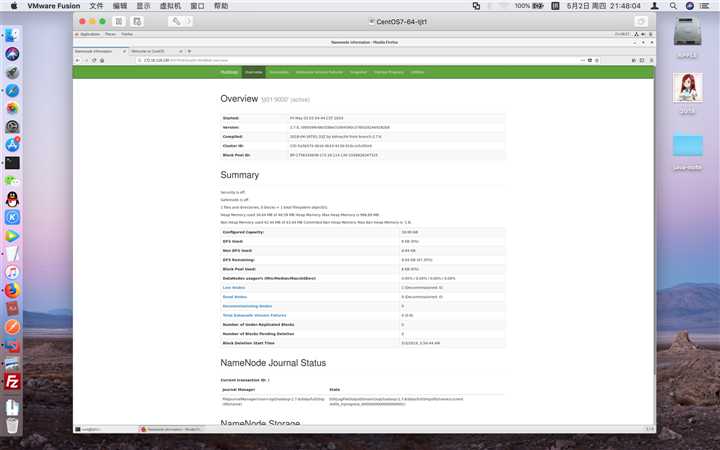
在虚拟机tjt01上访问:http://172.16.114.130:50070
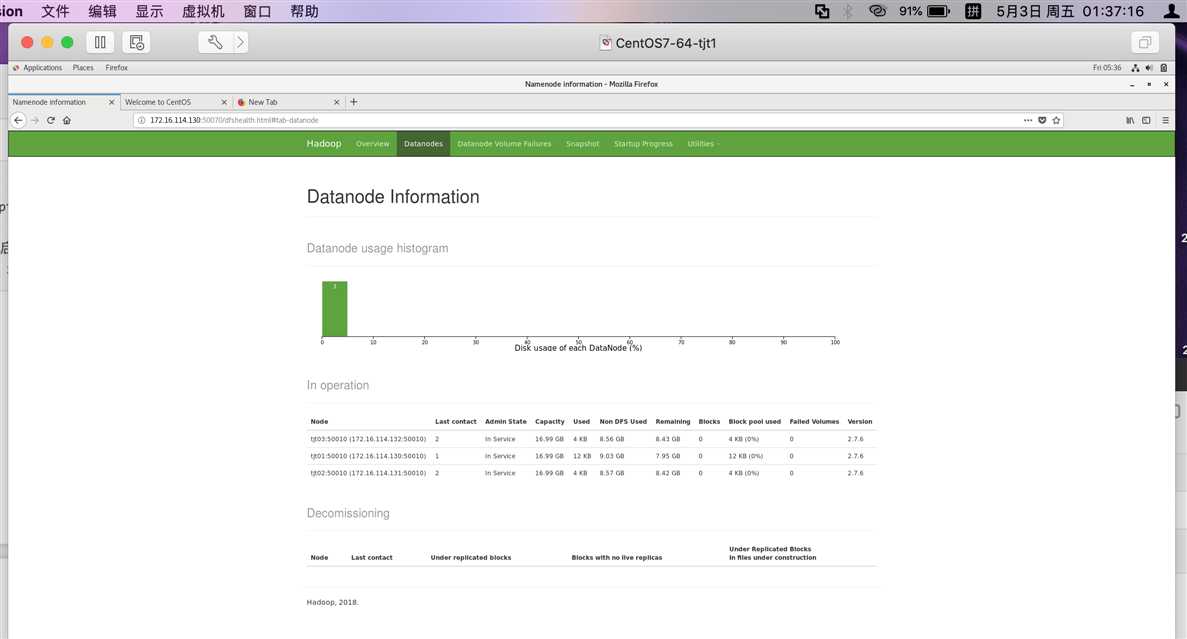
Datanode:
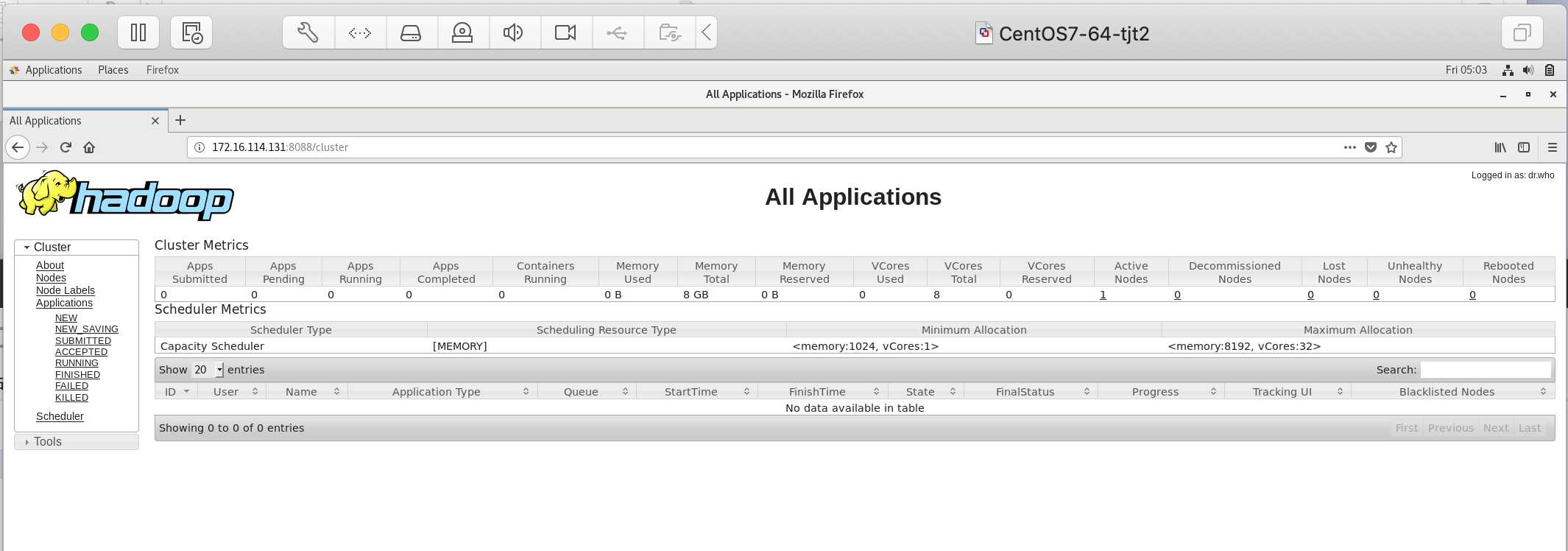
在虚拟机tjt02上访问:http://172.16.114.131:8088/cluster
4.2、Hadoop停止启动方式
1)各个服务组件逐一启动
分别启动hdfs 组件:
hadoop-deamon.sh start | stop namenode | datnode | secondarynamenode
启动yarn:
yarn-deamon.sh start | stop resourcemanager | nodemanager
2) 各个模块分开启动(常用)
start | stop-dfs.sh
start | stop-yarn.sh
3) 全部启动
start | stop-all.sh
其他
1、关闭防火墙
//临时关闭
systemctl stop firewalld
//禁止开机启动
systemctl disable firewalld

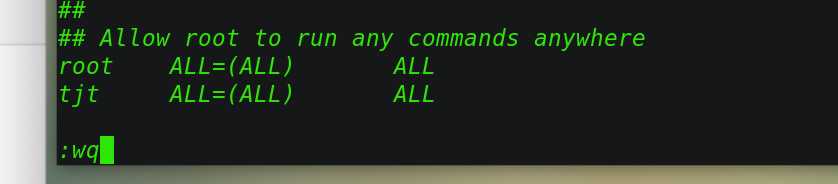
2、创建用户,设置文件权限
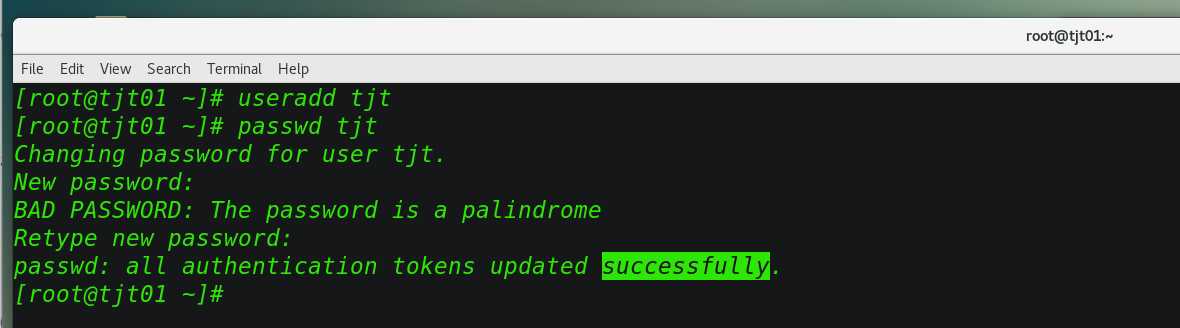
创建用户,修改密码:
[[email protected] ~]# useradd tjt
[[email protected] ~]# passwd tjt

以上是关于Mac-搭建Hadoop集群的主要内容,如果未能解决你的问题,请参考以下文章