tensorflow fp16训练
Posted sunny-li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tensorflow fp16训练相关的知识,希望对你有一定的参考价值。
理论
在混合精度训练中,权重,激活值和梯度是保存成fp16的形式,为了能够匹配fp32的网络精度,有一个权重的fp32的master copy。
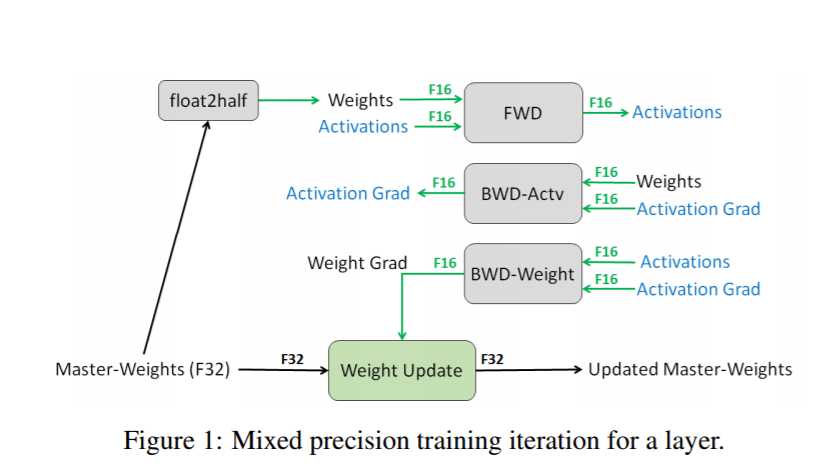
在tensorflow中的具体实现
tensorflow支持fp16的存储和tensor计算。包含tf.float16的数据类型的卷积和矩阵运算会自动使用fp16的计算。
为了能够使用tensor的core,fp32的模型需要转换成fp32和fp16的混合,可以手动完成,也可以自动混合精度(AMP)。
Tensorflow中自动混合精度训练
自动混合精度训练的启动很简单,只需要设定一个环境变量 export tf_enable_auto_mixed_precision=1
当然也可以在tensorflow的python脚本里面去设定 os.environ[‘TF_ENABLE_AUTO_MIXED_PRECISION‘]=‘1‘
一旦打开之后,AMP就会帮你做以下两件事情
1.在你的tensorflow的图中插入合适的cast运算,在合适的时机使用float16来计算和存储
2.在训练optimizer里面,打开自动loss scaling
手动在tensorflow中使用混合精度训练
1.去nvidia GPU cloud(NGC) container registry中拿最新的tensorflow container,这个container已经build好了,测试过并且调试过,可以直接用。这个contianer包含最新的cuda版本,fp16支持,并且基于最新的架构进行了优化
2.在矩阵运算或者卷积运算中采用tf.fp16,这个数据类型会尽可能的使用tensor core的硬件,举个例子
dtype = tf.float16
data = tf.placeholder(dtype, shape=(nbatch, nin))
weights = tf.get_variable(‘weights‘, (nin, nout), dtype)
biases = tf.get_variable(‘biases‘, nout, dtype,
initializer=tf.zeros_initializer())
logits = tf.matmul(data, weights) + biases
3.确保可以训练的参数是fp32类型的,并且在模型中使用他们的时候cast成fp16
tf.cast(tf.get_variable(..., dtype=tf.float32), tf.float16)
4.确保softmax的计算时fp32精度的
tf.losses.softmax_cross_entropy(target, tf.cast(logits, tf.float32))
5.使用loss-scaling,这个会在计算梯度的时候乘以一个因子,然后算出来之后除以一个相同的因子
loss, params = ... scale = 128 grads = [grad / scale for grad in tf.gradients(loss * scale, params)]
参考:
https://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html#tensorflow
https://arxiv.org/pdf/1710.03740.pdf
以上是关于tensorflow fp16训练的主要内容,如果未能解决你的问题,请参考以下文章
NVIDIA V100 上的 TensorRT FP16 或 INT8 无法加速