Pandas_实现数字顺序填充指定值交替填充日期顺序填充(按日月年)
Posted wodexk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas_实现数字顺序填充指定值交替填充日期顺序填充(按日月年)相关的知识,希望对你有一定的参考价值。
excel表的数据情况如下:下面数据区域的左边和上边都是空,这会导致我们读取近pathon里时,结构不是我们要的,需要用到skiprow和usecols来控制我们想要读取的区域
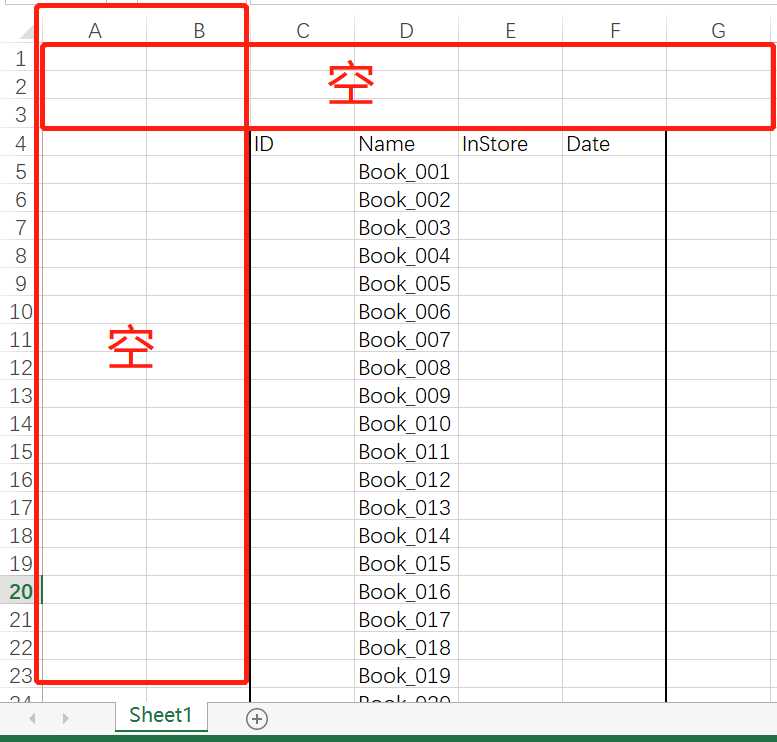
整合:
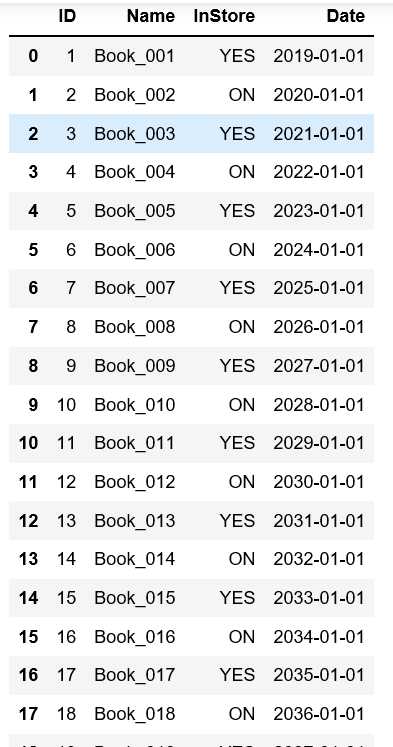
import pandas as pd from datetime import date,timedelta books = pd.read_excel("../004/Books.xlsx",skiprows=3,usecols="C:F",dtype={"ID":str,"InStore":str,"Date":str}) # books.dtypes # 设置个起始日期 start = date(2019,1,1) # 设置个月份递增的函数 def add_month(d,md): y = md // 12 m = d.month + md % 12 if m !=12: y += m // 12 m = m % 12 return date(d.year + y, m,d.day) for i in books.index: books["ID"].at[i]=i+1 books["InStore"].at[i]="YES" if i % 2 ==0 else "ON" # books["Date"].at[i]=start + timedelta(days=i) # 逐日增加 # books["Date"].at[i]=add_month(start,i) # 逐月增加 books["Date"].at[i]=date(start.year+i,start.month,start.day) # 逐年增加 print(books) # 设置索引为ID列 books.set_index("ID",inplace=True) # 将设置好的数据存入名为:out_books的excel表里 books.to_excel("out_books.xlsx") print("Done!")
结果图:
分解:
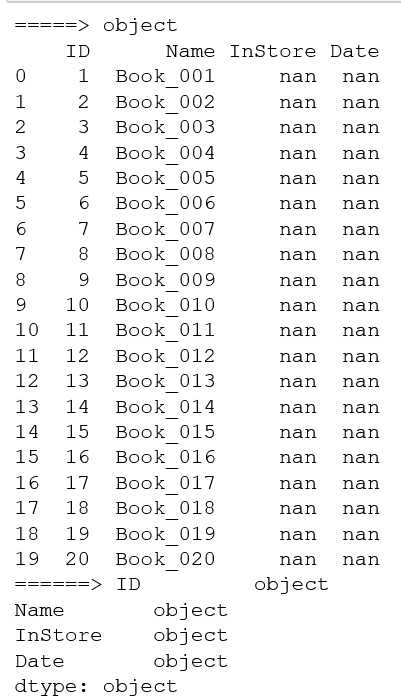
import pandas as pd # skiprows=3 表示跳过上面的3行后再读取 # usecols="C:F" 表示读取excel里C到F的列,如果时要跳着选择列可以写成:usecols="C,D,E,F" books = pd.read_excel("../004/Books.xlsx",skiprows=3,usecols="C:F",dtype={"ID":str,"InStore":str,"Date":str}) print(books.head())
一、为ID列自动填充1-20的数字 :
# ID列的数据都是NaN,NaN的类型是浮点数,如果不先转换ID列的数据类型,直接给ID填充赋值后的数据也是浮点类型,因此我们需要在导入数据时就把 # 字段的类型先做转换,但是因为NaN的数据不让我们转为int,会报错,我们可以用个小技巧,把NaN的列先转换为str类型,这样一会就可以正常赋值 print("=====>",books["ID"].dtypes) # 这句是为了查看ID的数据类型 # 下面开始给指定列赋值 # 方法1: for i in books.index: books["ID"].at[i]=i+1 # 方法2: for i in range(0,20): # books["ID"].at[i]=i+1 这是先找出指定的那一列(Series),再找到要替换的那一行 books.at[i,"ID"]=i+1 # 这是直接在二维表(DataFrame)里指定第几行,第几列要替换 print(books) print("======>",books.dtypes) # 这句是查看books数据里所有列的数据类型
结果图:
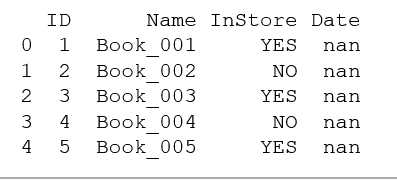
二、给 InStore 列 替换式的填充 YES 和 NO :
for i in books.index: books["InStore"].at[i]="YES" if i % 2 ==0 else "NO" print(books.head())
结果图:
三、 按日期填充数据:
# 先导入datetime库 from datetime import date,timedelta # 先设置一个起始日期 start = date(2019,1,1)
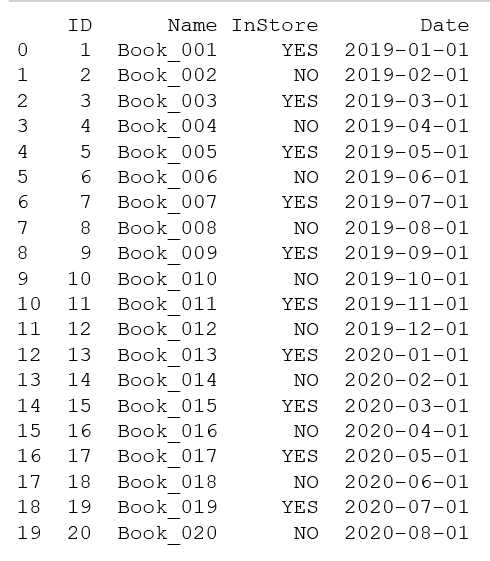
1、给 Date 列的日期逐日增加填充
# 按日给Date列填充时间 for i in books.index: books["Date"].at[i]=start+timedelta(days=i) # 用 timedelta(days=i) 实现按日填充 # books["Date"].at[i]=date(start.year,start.month,start.day+i) 也可以这么写来实现逐日填充 print(books)
结果图:
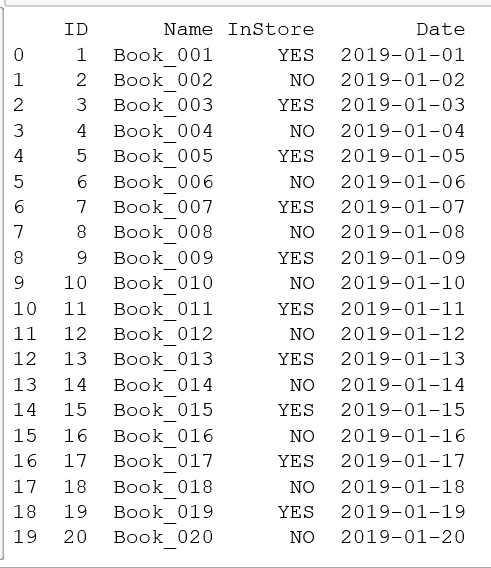
2、给 Date 列的日期按年填充 :
for i in books.index: books["Date"].at[i]=date(start.year+i,start.month,start.day) print(books.head())
结果图:
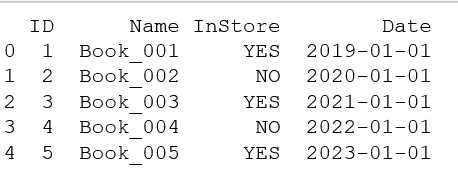
3、给 Date 列的日期按月份填充,需要设置个函数实现:
# d:传入的起始日期 # md: 要增加多少个月 def add_month(d,md): y = md //12 # 要增加的月份能换算成多少年 m = d.month + md % 12 # md % 12:要增加的月份除以12后的余数(即剩下多少个月) if m !=12: y += m // 12 m = m % 12 return date(d.year+y,m,d.day)
# 用for 循环填充 for i in books.index: books["Date"].at[i]=add_month(start,i) print(books)
结果图:
以上是关于Pandas_实现数字顺序填充指定值交替填充日期顺序填充(按日月年)的主要内容,如果未能解决你的问题,请参考以下文章