模型选择
Posted pjishu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型选择相关的知识,希望对你有一定的参考价值。
1.数据分组
将原始数据分成训练集,验证集和测试集,它们的比例分别为:60%,20%,20%。
训练集(train set) —— 用于模型拟合的数据样本。
验证集(development set)—— 是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。
在神经网络中, 我们用验证数据集去寻找最优的网络深度(number of hidden layers),或者决定反向传播算法的停止点或者在神经网络中选择隐藏层神经元的数量;
测试集 —— 用来评估模最终模型的泛化能力,用来计算模型的泛化误差。但不能作为调参、选择特征等算法相关的选择的依据。
2.训练好每个模型再挑选模型
若不知道该选择下面哪个模型,可以先利用训练集对每一个模型进行训练,得到相应的参数值,随后通过计算每个训练好的模型的验证集的准确率来决定要哪个模型。
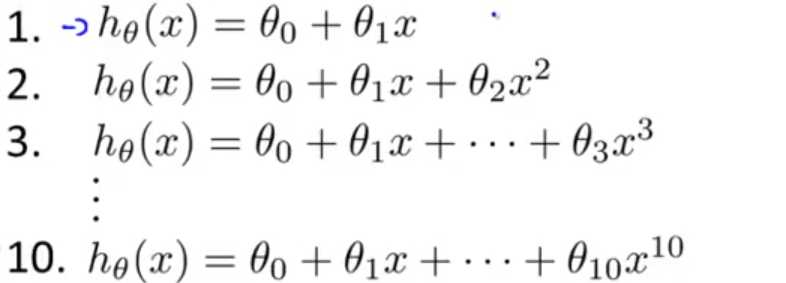
再比如,当不知道λ该取何值时,可以采取与上面类似的方法:

注意:当训练好模型之后,查看训练集,验证集和测试集的准确率的时候就不用λ项了,而是采取下图的方式(假定均方误差形式):
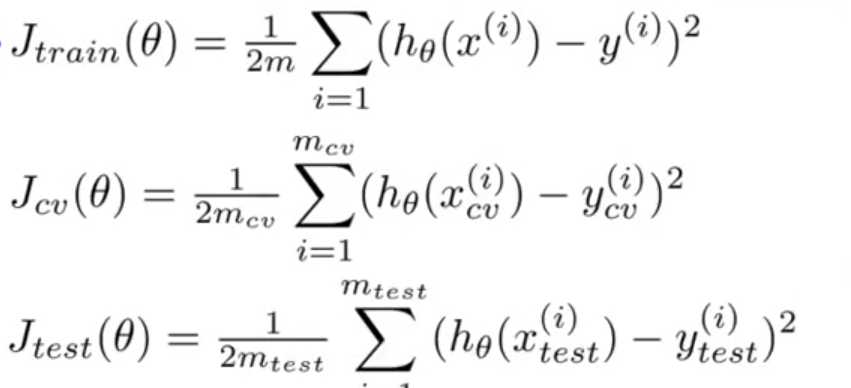
以上是关于模型选择的主要内容,如果未能解决你的问题,请参考以下文章