吴裕雄 python 机器学习——模型选择分类问题性能度量
Posted tszr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴裕雄 python 机器学习——模型选择分类问题性能度量相关的知识,希望对你有一定的参考价值。
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import SVC from sklearn.datasets import load_iris from sklearn.preprocessing import label_binarize from sklearn.multiclass import OneVsRestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,fbeta_score,classification_report,confusion_matrix,precision_recall_curve,roc_auc_score,roc_curve #模型选择分类问题性能度量accuracy_score模型 def test_accuracy_score(): y_true=[1,1,1,1,1,0,0,0,0,0] y_pred=[0,0,1,1,0,0,1,1,0,0] print(‘Accuracy Score(normalize=True):‘,accuracy_score(y_true,y_pred,normalize=True)) print(‘Accuracy Score(normalize=False):‘,accuracy_score(y_true,y_pred,normalize=False)) #调用test_accuracy_score() test_accuracy_score()

#模型选择分类问题性能度量precision_score模型 def test_precision_score(): y_true=[1,1,1,1,1,0,0,0,0,0] y_pred=[0,0,1,1,0,0,0,0,0,0] print(‘Accuracy Score:‘,accuracy_score(y_true,y_pred,normalize=True)) print(‘Precision Score:‘,precision_score(y_true,y_pred)) #调用test_precision_score() test_precision_score()

#模型选择分类问题性能度量recall_score模型 def test_recall_score(): y_true=[1,1,1,1,1,0,0,0,0,0] y_pred=[0,0,1,1,0,0,0,0,0,0] print(‘Accuracy Score:‘,accuracy_score(y_true,y_pred,normalize=True)) print(‘Precision Score:‘,precision_score(y_true,y_pred)) print(‘Recall Score:‘,recall_score(y_true,y_pred)) #调用test_recall_score() test_recall_score()

#模型选择分类问题性能度量f1_score模型 def test_f1_score(): y_true=[1,1,1,1,1,0,0,0,0,0] y_pred=[0,0,1,1,0,0,0,0,0,0] print(‘Accuracy Score:‘,accuracy_score(y_true,y_pred,normalize=True)) print(‘Precision Score:‘,precision_score(y_true,y_pred)) print(‘Recall Score:‘,recall_score(y_true,y_pred)) print(‘F1 Score:‘,f1_score(y_true,y_pred)) #调用test_f1_score() test_f1_score()
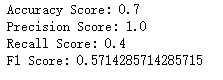
#模型选择分类问题性能度量fbeta_score模型 def test_fbeta_score(): y_true=[1,1,1,1,1,0,0,0,0,0] y_pred=[0,0,1,1,0,0,0,0,0,0] print(‘Accuracy Score:‘,accuracy_score(y_true,y_pred,normalize=True)) print(‘Precision Score:‘,precision_score(y_true,y_pred)) print(‘Recall Score:‘,recall_score(y_true,y_pred)) print(‘F1 Score:‘,f1_score(y_true,y_pred)) print(‘Fbeta Score(beta=0.001):‘,fbeta_score(y_true,y_pred,beta=0.001)) print(‘Fbeta Score(beta=1):‘,fbeta_score(y_true,y_pred,beta=1)) print(‘Fbeta Score(beta=10):‘,fbeta_score(y_true,y_pred,beta=10)) print(‘Fbeta Score(beta=10000):‘,fbeta_score(y_true,y_pred,beta=10000)) #调用test_fbeta_score() test_fbeta_score()

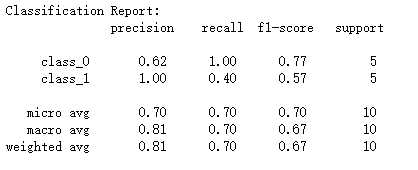
#模型选择分类问题性能度量classification_report模型 def test_classification_report(): y_true=[1,1,1,1,1,0,0,0,0,0] y_pred=[0,0,1,1,0,0,0,0,0,0] print(‘Classification Report:\\n‘,classification_report(y_true,y_pred,target_names=["class_0","class_1"])) #调用test_classification_report() test_classification_report()
#模型选择分类问题性能度量confusion_matrix模型 def test_confusion_matrix(): y_true=[1,1,1,1,1,0,0,0,0,0] y_pred=[0,0,1,1,0,0,0,0,0,0] print(‘Confusion Matrix:\\n‘,confusion_matrix(y_true,y_pred,labels=[0,1])) #调用test_confusion_matrix() test_confusion_matrix()

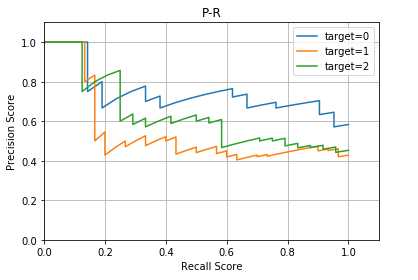
#模型选择分类问题性能度量precision_recall_curve模型 def test_precision_recall_curve(): ### 加载数据 iris=load_iris() X=iris.data y=iris.target # 二元化标记 y = label_binarize(y, classes=[0, 1, 2]) n_classes = y.shape[1] #### 添加噪音 np.random.seed(0) n_samples, n_features = X.shape X = np.c_[X, np.random.randn(n_samples, 200 * n_features)] X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.5,random_state=0) ### 训练模型 clf=OneVsRestClassifier(SVC(kernel=‘linear‘, probability=True,random_state=0)) clf.fit(X_train,y_train) y_score = clf.fit(X_train, y_train).decision_function(X_test) ### 获取 P-R fig=plt.figure() ax=fig.add_subplot(1,1,1) precision = dict() recall = dict() for i in range(n_classes): precision[i], recall[i], _ = precision_recall_curve(y_test[:, i],y_score[:, i]) ax.plot(recall[i],precision[i],label="target=%s"%i) ax.set_xlabel("Recall Score") ax.set_ylabel("Precision Score") ax.set_title("P-R") ax.legend(loc=‘best‘) ax.set_xlim(0,1.1) ax.set_ylim(0,1.1) ax.grid() plt.show() #调用test_precision_recall_curve() test_precision_recall_curve()
#模型选择分类问题性能度量roc_curve、roc_auc_score模型 def test_roc_auc_score(): ### 加载数据 iris=load_iris() X=iris.data y=iris.target # 二元化标记 y = label_binarize(y, classes=[0, 1, 2]) n_classes = y.shape[1] #### 添加噪音 np.random.seed(0) n_samples, n_features = X.shape X = np.c_[X, np.random.randn(n_samples, 200 * n_features)] X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.5,random_state=0) ### 训练模型 clf=OneVsRestClassifier(SVC(kernel=‘linear‘, probability=True,random_state=0)) clf.fit(X_train,y_train) y_score = clf.fit(X_train, y_train).decision_function(X_test) ### 获取 ROC fig=plt.figure() ax=fig.add_subplot(1,1,1) fpr = dict() tpr = dict() roc_auc=dict() for i in range(n_classes): fpr[i], tpr[i], _ = roc_curve(y_test[:, i],y_score[:, i]) roc_auc[i] = roc_auc_score(fpr[i], tpr[i]) ax.plot(fpr[i],tpr[i],label="target=%s,auc=%s"%(i,roc_auc[i])) ax.plot([0, 1], [0, 1], ‘k--‘) ax.set_xlabel("FPR") ax.set_ylabel("TPR") ax.set_title("ROC") ax.legend(loc="best") ax.set_xlim(0,1.1) ax.set_ylim(0,1.1) ax.grid() plt.show() #调用test_roc_auc_score() test_roc_auc_score()
以上是关于吴裕雄 python 机器学习——模型选择分类问题性能度量的主要内容,如果未能解决你的问题,请参考以下文章