关于自定义sparkSQL数据源(Hbase)操作中遇到的坑
Posted niutao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于自定义sparkSQL数据源(Hbase)操作中遇到的坑相关的知识,希望对你有一定的参考价值。

自定义sparkSQL数据源的过程中,需要对sparkSQL表的schema和Hbase表的schema进行整合;
对于spark来说,要想自定义数据源,你就必须得实现这3个接口:
BaseRelation 代表了一个抽象的数据源。该数据源由一行行有着已知schema的数据组成(关系表)。
TableScan 用于扫描整张表,将数据返回成RDD[Row]。
RelationProvider 顾名思义,根据用户提供的参数返回一个数据源(BaseRelation)。
所以,如果对接Hbase的话,就定义一个Hbase的relation
class DefaultSource extends RelationProvider { def createRelation(sqlContext: SQLContext, parameters: Map[String, String]) = { HBaseRelation(parameters)(sqlContext) } }


case class HBaseRelation(@transient val hbaseProps: Map[String,String])(@transient val sqlContext: SQLContext) extends BaseRelation with Serializable with TableScan{ val hbaseTableName = hbaseProps.getOrElse("hbase_table_name", sys.error("not valid schema")) val hbaseTableSchema = hbaseProps.getOrElse("hbase_table_schema", sys.error("not valid schema")) val registerTableSchema = hbaseProps.getOrElse("sparksql_table_schema", sys.error("not valid schema")) val rowRange = hbaseProps.getOrElse("row_range", "->") //get star row and end row val range = rowRange.split("->",-1) val startRowKey = range(0).trim val endRowKey = range(1).trim val tempHBaseFields = extractHBaseSchema(hbaseTableSchema) //do not use this, a temp field val registerTableFields = extractRegisterSchema(registerTableSchema) val tempFieldRelation = tableSchemaFieldMapping(tempHBaseFields,registerTableFields) val hbaseTableFields = feedTypes(tempFieldRelation) val fieldsRelations = tableSchemaFieldMapping(hbaseTableFields,registerTableFields) val queryColumns = getQueryTargetCloumns(hbaseTableFields) def feedTypes( mapping: Map[HBaseSchemaField, RegisteredSchemaField]) : Array[HBaseSchemaField] = { val hbaseFields = mapping.map{ case (k,v) => val field = k.copy(fieldType=v.fieldType) field } hbaseFields.toArray } def isRowKey(field: HBaseSchemaField) : Boolean = { val cfColArray = field.fieldName.split(":",-1) val cfName = cfColArray(0) val colName = cfColArray(1) if(cfName=="" && colName=="key") true else false } def getQueryTargetCloumns(hbaseTableFields: Array[HBaseSchemaField]): String = { var str = ArrayBuffer[String]() hbaseTableFields.foreach{ field=> if(!isRowKey(field)) { str.append(field.fieldName) } } println(str.mkString(" ")) str.mkString(" ") } lazy val schema = { val fields = hbaseTableFields.map{ field=> val name = fieldsRelations.getOrElse(field, sys.error("table schema is not match the definition.")).fieldName val relatedType = field.fieldType match { case "String" => SchemaType(StringType,nullable = false) case "Int" => SchemaType(IntegerType,nullable = false) case "Long" => SchemaType(LongType,nullable = false) case "Double" => SchemaType(DoubleType,nullable = false) } StructField(name,relatedType.dataType,relatedType.nullable) } StructType(fields) } def tableSchemaFieldMapping( externalHBaseTable: Array[HBaseSchemaField], registerTable : Array[RegisteredSchemaField]): Map[HBaseSchemaField, RegisteredSchemaField] = { if(externalHBaseTable.length != registerTable.length) sys.error("columns size not match in definition!") val rs: Array[(HBaseSchemaField, RegisteredSchemaField)] = externalHBaseTable.zip(registerTable) rs.toMap } /** * spark sql schema will be register * registerTableSchema ‘(rowkey string, value string, column_a string)‘ */ def extractRegisterSchema(registerTableSchema: String) : Array[RegisteredSchemaField] = { val fieldsStr = registerTableSchema.trim.drop(1).dropRight(1) val fieldsArray = fieldsStr.split(",").map(_.trim)//sorted fieldsArray.map{ fildString => val splitedField = fildString.split("\\\\s+", -1)//sorted RegisteredSchemaField(splitedField(0), splitedField(1)) } } def extractHBaseSchema(externalTableSchema: String) : Array[HBaseSchemaField] = { val fieldsStr = externalTableSchema.trim.drop(1).dropRight(1) val fieldsArray = fieldsStr.split(",").map(_.trim) fieldsArray.map(fildString => HBaseSchemaField(fildString,"")) } // By making this a lazy val we keep the RDD around, amortizing the cost of locating splits. lazy val buildScan = { val hbaseConf = HBaseConfiguration.create() hbaseConf.set("hbase.zookeeper.quorum", GlobalConfigUtils.hbaseQuorem) hbaseConf.set(TableInputFormat.INPUT_TABLE, hbaseTableName) hbaseConf.set(TableInputFormat.SCAN_COLUMNS, queryColumns) hbaseConf.set(TableInputFormat.SCAN_ROW_START, startRowKey) hbaseConf.set(TableInputFormat.SCAN_ROW_STOP, endRowKey) val hbaseRdd = sqlContext.sparkContext.newAPIHadoopRDD( hbaseConf, classOf[org.apache.hadoop.hbase.mapreduce.TableInputFormat], classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable], classOf[org.apache.hadoop.hbase.client.Result] ) val rs = hbaseRdd.map(tuple => tuple._2).map(result => { var values = new ArrayBuffer[Any]() hbaseTableFields.foreach{field=> values += Resolver.resolve(field,result) } Row.fromSeq(values.toSeq) }) rs } private case class SchemaType(dataType: DataType, nullable: Boolean) }
Hbase的schema:
package object hbase { abstract class SchemaField extends Serializable case class RegisteredSchemaField(fieldName: String, fieldType: String) extends SchemaField with Serializable case class HBaseSchemaField(fieldName: String, fieldType: String) extends SchemaField with Serializable case class Parameter(name: String) //sparksql_table_schema protected val SPARK_SQL_TABLE_SCHEMA = Parameter("sparksql_table_schema") protected val HBASE_TABLE_NAME = Parameter("hbase_table_name") protected val HBASE_TABLE_SCHEMA = Parameter("hbase_table_schema") protected val ROW_RANGE = Parameter("row_range") /** * Adds a method, `hbaseTable`, to SQLContext that allows reading data stored in hbase table. */ implicit class HBaseContext(sqlContext: SQLContext) { def hbaseTable(sparksqlTableSchema: String, hbaseTableName: String, hbaseTableSchema: String, rowRange: String = "->") = { var params = new HashMap[String, String] params += ( SPARK_SQL_TABLE_SCHEMA.name -> sparksqlTableSchema) params += ( HBASE_TABLE_NAME.name -> hbaseTableName) params += ( HBASE_TABLE_SCHEMA.name -> hbaseTableSchema) //get star row and end row params += ( ROW_RANGE.name -> rowRange) sqlContext.baseRelationToDataFrame(HBaseRelation(params)(sqlContext)) } } }
当然了,其中schema的数据类型也得处理下:
object Resolver extends Serializable { def resolve (hbaseField: HBaseSchemaField, result: Result ): Any = { val cfColArray = hbaseField.fieldName.split(":",-1) val cfName = cfColArray(0) val colName = cfColArray(1) var fieldRs: Any = null //resolve row key otherwise resolve column if(cfName=="" && colName=="key") { fieldRs = resolveRowKey(result, hbaseField.fieldType) } else { fieldRs = resolveColumn(result, cfName, colName,hbaseField.fieldType) } fieldRs } def resolveRowKey (result: Result, resultType: String): Any = { val rowkey = resultType match { case "String" => result.getRow.map(_.toChar).mkString case "Int" => result .getRow.map(_.toChar).mkString.toInt case "Long" => result.getRow.map(_.toChar).mkString.toLong case "Float" => result.getRow.map(_.toChar).mkString.toLong case "Double" => result.getRow.map(_.toChar).mkString.toDouble } rowkey } def resolveColumn (result: Result, columnFamily: String, columnName: String, resultType: String): Any = { val column = result.containsColumn(columnFamily.getBytes, columnName.getBytes) match{ case true =>{ resultType match { case "String" => Bytes.toString(result.getValue(columnFamily.getBytes,columnName.getBytes)) case "Int" => Bytes.toInt(result.getValue(columnFamily.getBytes,columnName.getBytes)) case "Long" => Bytes.toLong(result.getValue(columnFamily.getBytes,columnName.getBytes)) case "Float" => Bytes.toFloat(result.getValue(columnFamily.getBytes,columnName.getBytes)) case "Double" => Bytes.toDouble(result.getValue(columnFamily.getBytes,columnName.getBytes)) } } case _ => { resultType match { case "String" => "" case "Int" => 0 case "Long" => 0 case "Double" => 0.0 } } } column } }
做个测试:
object CustomHbaseTest { def main(args: Array[String]): Unit = { val startTime = System.currentTimeMillis() val sparkConf: SparkConf = new SparkConf() .setMaster("local[6]") .setAppName("query") .set("spark.worker.timeout" , GlobalConfigUtils.sparkWorkTimeout) .set("spark.cores.max" , GlobalConfigUtils.sparkMaxCores) .set("spark.rpc.askTimeout" , GlobalConfigUtils.sparkRpcTimeout) .set("spark.task.macFailures" , GlobalConfigUtils.sparkTaskMaxFailures) .set("spark.speculation" , GlobalConfigUtils.sparkSpeculation) .set("spark.driver.allowMutilpleContext" , GlobalConfigUtils.sparkAllowMutilpleContext) .set("spark.serializer" , GlobalConfigUtils.sparkSerializer) .set("spark.buffer.pageSize" , GlobalConfigUtils.sparkBuferSize) .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") .set("spark.driver.host", "localhost") val sparkSession: SparkSession = SparkSession.builder() .config(sparkConf) .enableHiveSupport() //开启支持hive .getOrCreate() var hbasetable = sparkSession .read .format("com.df.test_custom.customSource") .options( Map( "sparksql_table_schema" -> "(id String, create_time String , open_lng String , open_lat String , begin_address_code String , charge_mileage String , city_name String , vehicle_license String)", "hbase_table_name" -> "order_info", "hbase_table_schema" -> "(MM:id , MM:create_time , MM:open_lng , MM:open_lat , MM:begin_address_code , MM:charge_mileage , MM:city_name , MM:vehicle_license)" )).load() hbasetable.createOrReplaceTempView("orderData") sparkSession.sql( """ |select * from orderData """.stripMargin).show() val endTime = System.currentTimeMillis() println(s"花费时间:${endTime - startTime}") } }
所有代码整合完毕之后,跑通了,但是确发现查询出来的数据和具体的列值对不上
比如:
var hbasetable = sparkSession .read .format("com.df.test_custom.customSource") .options( Map( "sparksql_table_schema" -> "(id String, create_time String , open_lng String , open_lat String , begin_address_code String , charge_mileage String , city_name String , vehicle_license String)", "hbase_table_name" -> "order_info", "hbase_table_schema" -> "(MM:id , MM:create_time , MM:open_lng , MM:open_lat , MM:begin_address_code , MM:charge_mileage , MM:city_name , MM:vehicle_license)" )).load()
我指定的sparkSQL表的schema和Hbase的schema如上面的代码;
但是我查询出来的数据是这样的:
hbasetable.createOrReplaceTempView("orderData")
sparkSession.sql(
"""
|select * from orderData
""".stripMargin).show()
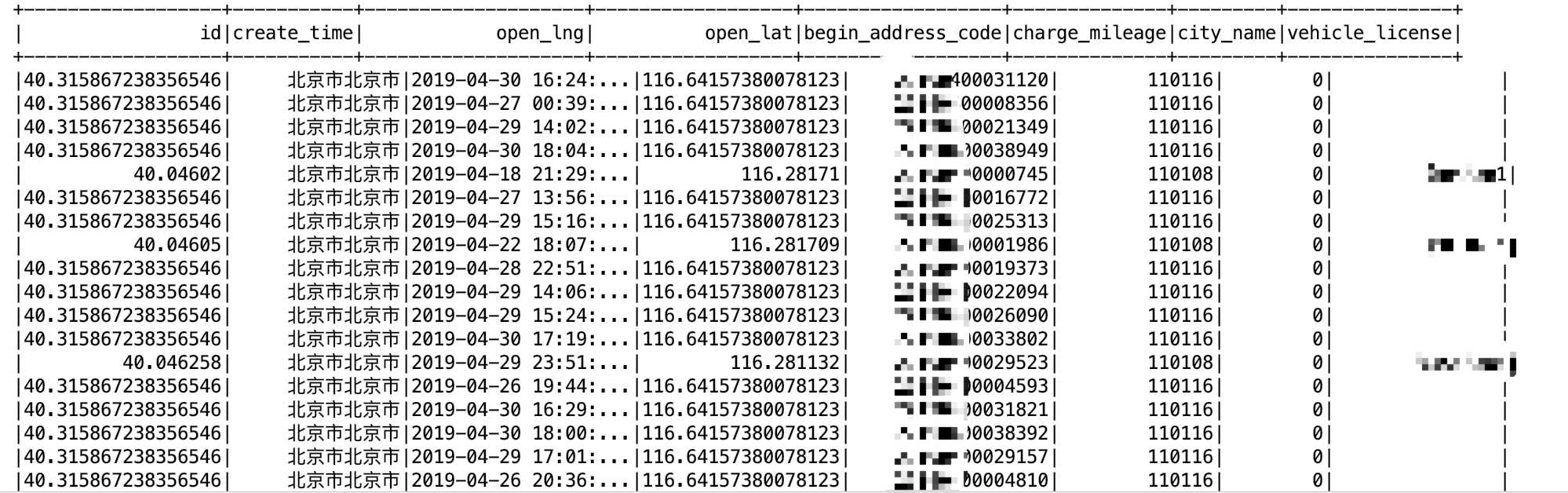
从上面的图可以看到,其实好多列的顺序对不上了!
问题所在的原因:
def tableSchemaFieldMapping( externalHBaseTable: Array[HBaseSchemaField], registerTable : Array[RegisteredSchemaField]): Map[HBaseSchemaField, RegisteredSchemaField] = { if(externalHBaseTable.length != registerTable.length) sys.error("columns size not match in definition!") val rs: Array[(HBaseSchemaField, RegisteredSchemaField)] = externalHBaseTable.zip(registerTable) rs.toMap }
可以看到,最后是----------> rs.toMap
您注意了,scala中的这个map是不能保证顺序的,举个栗子:
object TestMap { def main(args: Array[String]): Unit = { val arr1 = Array("java" , "scla" , "javascripe" , "ii" , "wqe" , "qaz") val arr2 = Array("java" , "scla" , "javascripe" , "ii" , "wqe" , "qaz") val toMap: Map[String, String] = arr1.zip(arr2).toMap for((k,v) <- toMap){ println(s"k :${k} , v:${v}") } } }
结果是这样的:

明显发现,这个结果没按照最初zip后的顺序来,问题其实就是在toMap这里
解决:
在jdk1.5之后,给出了一个可以保持插入顺序强相关的Map,就是 :LinkedHashMap
所以说,解决方案就是,将scala中的Map转成LinkedHashMap
1):修改feedTypes
def feedTypes( mapping: util.LinkedHashMap[HBaseSchemaField, RegisteredSchemaField]) : Array[HBaseSchemaField] = { val hbaseFields = mapping.map{ case (k,v) => val field = k.copy(fieldType=v.fieldType) field } hbaseFields.toArray } // def feedTypes( mapping: Map[HBaseSchemaField, RegisteredSchemaField]) : Array[HBaseSchemaField] = { // val hbaseFields = mapping.map{ // case (k,v) => // val field = k.copy(fieldType=v.fieldType) // field // } // hbaseFields.toArray // }
2):修改tableSchemaFieldMapping
def tableSchemaFieldMapping( externalHBaseTable: Array[HBaseSchemaField], registerTable : Array[RegisteredSchemaField]): util.LinkedHashMap[HBaseSchemaField, RegisteredSchemaField] = { if(externalHBaseTable.length != registerTable.length) sys.error("columns size not match in definition!") val rs: Array[(HBaseSchemaField, RegisteredSchemaField)] = externalHBaseTable.zip(registerTable) val linkedHashMap = new util.LinkedHashMap[HBaseSchemaField, RegisteredSchemaField]() for(arr <- rs){ linkedHashMap.put(arr._1 , arr._2) } linkedHashMap } // def tableSchemaFieldMapping( externalHBaseTable: Array[HBaseSchemaField], registerTable : Array[RegisteredSchemaField]): Map[HBaseSchemaField, RegisteredSchemaField] = { // if(externalHBaseTable.length != registerTable.length) sys.error("columns size not match in definition!") // val rs: Array[(HBaseSchemaField, RegisteredSchemaField)] = externalHBaseTable.zip(registerTable) // rs.toMap // }
然后在跑test代码:结果
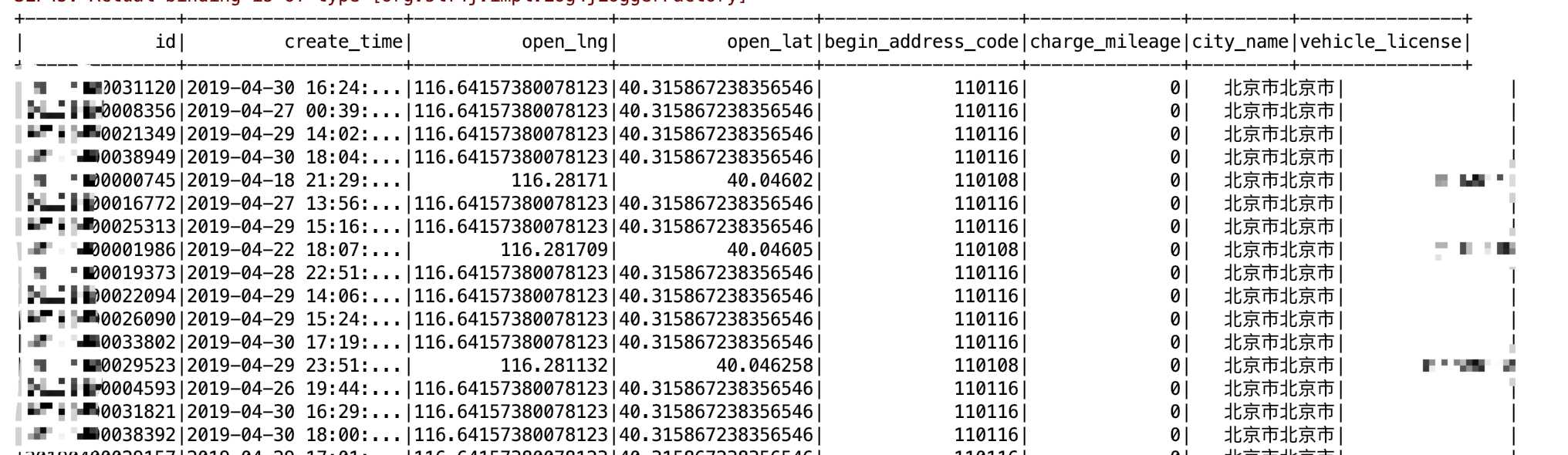
跑通!!!
PS:直接赋值我的代码就能用了
另外:
var hbasetable = sparkSession .read .format("com.df.test_custom.customSource") .options( Map( "sparksql_table_schema" -> "(id String, create_time String , open_lng String , open_lat String , begin_address_code String , charge_mileage String , city_name String , vehicle_license String)", "hbase_table_name" -> "order_info", "hbase_table_schema" -> "(MM:id , MM:create_time , MM:open_lng , MM:open_lat , MM:begin_address_code , MM:charge_mileage , MM:city_name , MM:vehicle_license)" )).load()
sparksql_table_schema和hbase_table_schema 顺序必须一样
以上是关于关于自定义sparkSQL数据源(Hbase)操作中遇到的坑的主要内容,如果未能解决你的问题,请参考以下文章