一种简单高效的音频降噪算法示例(附完整C代码)
Posted cpuimage
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一种简单高效的音频降噪算法示例(附完整C代码)相关的知识,希望对你有一定的参考价值。
近期比较忙,
抽空出来5.1开源献礼.
但凡学习音频降噪算法的朋友,肯定看过一个算法.
<<语音增强-理论与实践>> 中提及到基于对数的最小均方误差的降噪算法,也就是LogMMSE.
资料见:
<<Speech enhancement using a minimum mean-square error log-spectral amplitude estimator.>>
-----Ephraim, Y. and Malah, D. (1985)
之前也是花了不少时间去查阅降噪相关的思路,
但是最终发现前人的思路,有很多局限性或者说弊端.
一般都是提出一种数学先验的假设,换句话说,在paper里讲点故事.
然后最终,故事的结局都是it works.
但实际应用却差强人意.
而一般的图像降噪流程,见图:
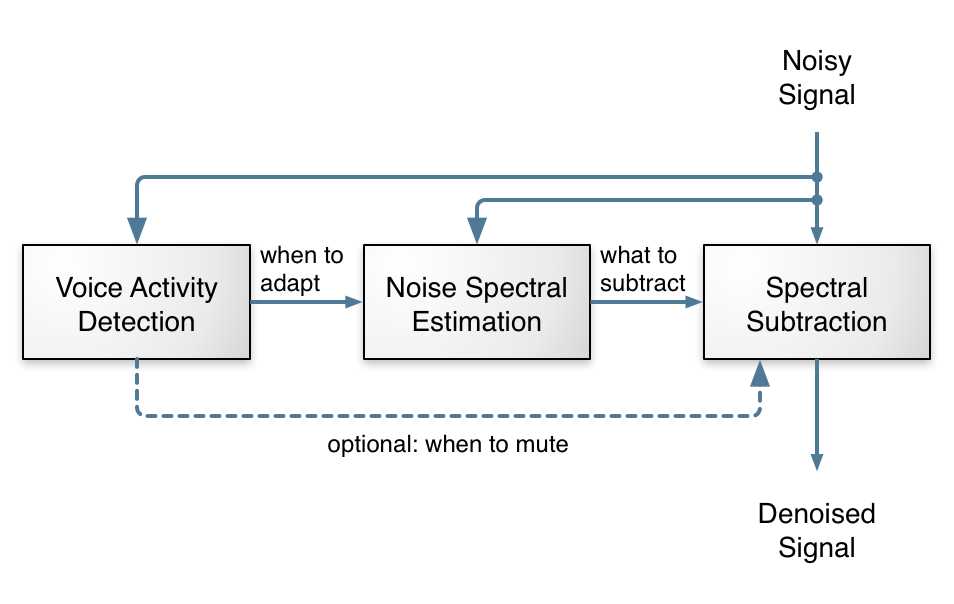
也就是,一个降噪算法的基本组成部分有:
1.噪声提取(用于提取噪声)
2.静音检测(一般检测是否为人声,减少误判)
3.数学先验假设(用于降噪)
当然最小均方误差的降噪思路,用在图像上一样适用.
但是,大多数音频降噪算法仅仅适配某种特殊情况(特例).
工程化应用时,会发现,
一个坑接着一个坑,
然后不得不妥协.勉强能用就行,
要求太高不现实.
而当年看了logMMSE的思路之后,就很清楚地明白,
这思路是可行的,但是特别鸡肋.
话说如此,但是对作为学习信号处理,音频降噪来说,
这个是一个特别好的入门示例算法.
至少经过实践之后,你心中能有了个大概的印象.
音频降噪是一个什么样的工作,会碰到什么样的难点.
logmmse的各种实现,在github搜索一下,都能找得到.
这里,并不打算解析logmmse的算法细节.
只是分享一段非常简单有效的类似logmmse算法的c语言实现.
说是类似,不如说,
思路来自logmmse,只是更加的简洁明了.(自我以为)
自己动手,丰衣足食.
稍微改进一下,可以进一步适配各种环境和情况,
当然也不是那么容易,
例如:
+vad.
+延时记忆机制诸如此类
代码基于本人最近开源的基于傅里叶变换的重采样算法.
https://github.com/cpuimage/FFTResampler
题外话:
在之前为了找各种重采样算法,费心死了.
所以,写一个通用简洁的重采样算法是我的一个待办事项.
重采样算法算是暂时结束了.
https://github.com/cpuimage/resampler
https://github.com/cpuimage/FFTResampler
这两个平时应该是够用了,
下一步要继续做的话,
可能就是音频超分辨率算法了.
除了懒,没别的,能复用就复用了.
回到主题上,这个简易的算法用来去除平稳噪声或底噪,是非常合适的,
当然当前开源实现的算法,是非实时的,
当然稍微改进下可以应用在实时的环境.
值5.1放假之际,开源出来,给大家参考学习.
权当抛砖引玉,一起玩耍.
项目地址:
https://github.com/cpuimage/SimpleAudioDenoise
若有其他相关问题或者需求也可以邮件联系俺探讨。
当然一些基础性的问题,一概忽略.
有时间给我写邮件,不如多看点资料书籍.
邮箱地址是:
[email protected]
以上是关于一种简单高效的音频降噪算法示例(附完整C代码)的主要内容,如果未能解决你的问题,请参考以下文章